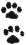 | Информационная система | |
ОТРАСЛЕВОЙ СТАНДАРТ
|
АВТОМАТИЗИРОВАННАЯ СИСТЕМА ВЕСОВОГО КОНТРОЛЯ Структура внутренних массивов и основные алгоритмы |
ОСТ 1 00352-79 |
|
На 25 страницах |
|
|
Введен впервые |
Распоряжением Министерства от 28 сентября 1879 г. № 087-16 срок введения установлен с 1 июля 1980 г.
Настоящий стандарт устанавливает структуру внутренних массивов (банка данных, буферного массива, каталога) и порядок функционирования основных программ (организации банка данных, каталога и выдачи выходной информации).
1. СТРУКТУРА ВНУТРЕННИХ МАССИВОВ
1.1. Структура банка данных
1.1.1. Банк данных (черт. 1) представляет собой объединение блоков данных (абзацев) - квадраты, каждый из которых представляет описание (модель) отдельной сборочной единицы основного изделия, состоящий в свою очередь из самостоятельных подблоков данных, которые называются фразами.
Каждый абзац заголовок (шифр абзаца) и ссылки в явной форме (указатели) к абзацам, моделирующим нижестоящие по уровню иерархии сборочные единицы.
В банке данных по особому моделируется сборочная единица при многократном ее применении на основном изделии.
Черт. 1
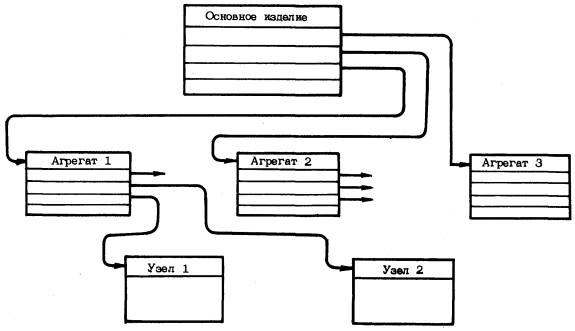
В этом случае в банке данных содержится только один абзац, моделирующий данную сборочную единицу, а суммарное количество указателей в других абзацах на данный абзац равно числу применений сборочной единицы на основном изделии. Такое построение банка данных в ряде случаев позволяет существенно сократить его объем. Пример составления банка данных для изделия 100, имеющего многократно применяющиеся сборочные единицы 110, 111, 112, 120 к 121 (черт. 2), представлен на черт. 3.
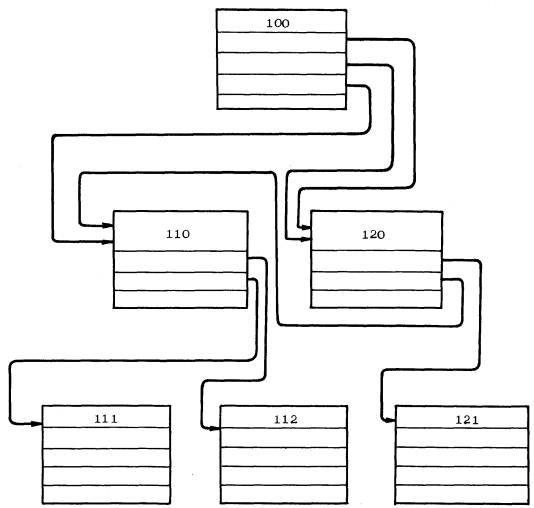
Черт. 2
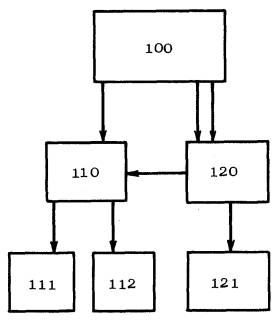
Черт. 3
1.1.2. Абзац банка данных представляет собой объединение фраз, имеющих самостоятельное смысловое значение:
- головной фразы;
- фраз-указателей;
- фраз-деталей.
Головная фраза (1 или 1а типа) - заголовок абзаца - дает общую характеристику сборочной единицы. Наличие головной фразы в абзаце обязательно. Остальные фразы составляют тело абзаца.
Фраза-указатель (фраза II типа) содержит ссылку на нижестоящую сборочную единицу и описание положения системы координат ее.
Фраза-деталь (фраза III или IV типа) содержит описание детали, входящей в сборочную единицу, моделируемую абзацем. Фразы тела абзаца локализованы: вначале стоят фразы-указатели, затем фразы-детали. Такое расположение фраз в абзаце существенно упрощает расчетные алгоритмы АСВК. Количество фраз, составляющих тело абзаца, переменное и может равняться нулю. В этом случае абзац будет состоять только из головной фразы.
1.1.3. Каждая фраза состоит из самостоятельных смысловых единиц (слов) трех видов: признаков, текстов, чисел. Признаки и числа имеют фиксированную (наперед заданную) длину, причем числа представлены в форме с плавающей запятой. Длина текста (текстовой информации) не фиксирована. Все фразы имеют общий принцип построения:
- фиксированное для данного типа фразы количество слов;
- слова, содержащие текстовую информацию, располагаются впереди слов, содержащих числовые константы;
- первым словом фразы является признак типа фразы, одновременно служащей меткой начала фразы;
- длина фразы не фиксирована;
- конец каждой фразы определяется по метке начала следующей фразы, т.е. признак фразы служит разделителем фраз в банке данных.
1.1.4. В качестве головной фразы применяется фраза 1 типа или фраза 1а типа.
Фраза 1а типа - неполная головная фраза - является в абзаце временной, так как после завершения образования абзаца в процессе поступления информации в банк данных она будет замещена головной фразой 1 типа. Абзац с головной фразой 1а типа называется неполным, так как он содержит неполный набор фраз, позволяющих описать сборочную единицу. Абзацы с неполной головной фразой не принимают участия в расчетах на ЭВМ.
Фраза 1а типа содержит шифр (номер чертежа) сборочной единицы и состоит из двух слов: признака фразы 1а типа и шифра сборочной единицы.
Шифр сборочной единицы одновременно является и шифром абзаца.
Фраза 1 типа считается полной головной фразой абзаца, который в этом случае будет называться активным или полным абзацем.
Фраза 1 типа дает общую характеристику сборочной единицы и содержит следующие слова в порядке их расположения в фразе (черт. 4):
- признак начала фразы 1 типа (I);
- признак стирания (с), используемый во фразах буферного массива для стирания абзацев из банка данных;
- шифр (обозначение чертежа) сборочной единицы, моделируемой абзацем;
- признак начала наименования (Н);
- наименование;
- признак начала числовых констант (К);
- лимитная
масса ![]() ;
;
- чертежная
масса ![]() ;
;
- фактическая
масса ![]() .
.

Черт. 4
1.1.5. В качестве фразы-указателя служит фраза II типа. Фраза II типа содержит следующие слова в порядке их расположения внутри фразы (черт. 5):
- признак начала фразы II типа (II);
- признак симметрии (ПС), который задается при описании вхождения нижестоящей сборочной единицы в сборочную единицу, моделируемую абзацем;
- признак стирания (С), используемый во фразах буферного массива для стирания идентичных фраз II типа из абзацев банка данных;
- шифр (обозначение чертежа) входящей сборочной единицы;
- признак начала наименования (Н);
- признак начала числовых констант (К);
- x, y, z - координаты положения начала системы координат входящей сборочной единицы, моделируемой абзацем;
- ![]() - плоскостные углы
поворота осей системы координат входящей сборочной единицы в системе координат
сборочной единицы, моделируемой абзацем.
- плоскостные углы
поворота осей системы координат входящей сборочной единицы в системе координат
сборочной единицы, моделируемой абзацем.

Черт. 5
1.1.6. В качестве фразы-детали применяется фраза III типа или фраза IV типа.
Фраза III типа служит для описания детали, которая считается материальной точкой, не имеющей собственных моментов инерции.
Фраза IV типа служит для описания детали, которая задана собственными моментами инерции относительно своей системы координат, проходящих через центр тяжести детали.
Фраза III типа содержит следующие слова в порядке их расположения внутри фразы (черт. 6):
- признак начала фразы Ш типа (III);
- признак симметрии (ПС), который задается при описании вхождения детали в сборочную единицу, моделируемую абзацем;
- признак стирания (С), используемый в фразах буферного массива для стирания идентичных фраз III типа из абзацев банка данных;
- шифр (обозначение чертежа) детали;
- признак начала наименования (Н);
- наименование детали;
- признак начала числовых констант (К);
- чертежная
масса детали ![]() ;
;
- фактическая
масса детали ![]() ;
;
- x, y, z - координаты центра тяжести детали в системе координат сборочной единицы, моделируемой абзацем.

Черт. 6
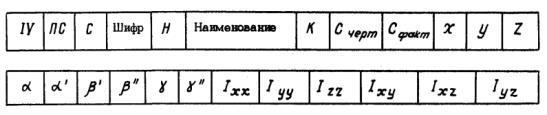
Фраза IV типа содержит следующие слова в порядке их расположения в фразе (черт. 7):
- признак начала фразы IV типа (IV);
- признак симметрии (ПС), который задается при описании вхождения детали в сборочную единицу, моделируемую абзацем;
- признак стирания (С), используемый в фразах буферного массива для стирания идентичных фраз IV типа из абзацев банка данных;
- шифр (обозначение чертежа) детали;
- признак начала наименования (Н);
- наименование детали;
- признак начала числовых констант (К);
- чертежная
масса детали ![]() ;
;
- фактическая
масса детали ![]() ;
;
- x, y, z - координаты центра тяжести детали в системе координат сборочной единицы, моделируемой абзацем;
- ![]() - плоскостные углы
поворота осей собственной системы координат детали в системе координат сборочной
единицы;
- плоскостные углы
поворота осей собственной системы координат детали в системе координат сборочной
единицы;
- Ixx, Iyy, Izz, Ixy, Ixz, Iyz - моменты инерции детали в собственной системе координат.
Черт. 7
1.2. Структура буферного массива
1.2.1. Входная информация поступает в банк данных через буферный массив. Буферный массив, как и банк данных, делится на абзацы. Абзацы буферного массива двух типов:
- содержащие только одну головную фразу 1 типа;
- начинающиеся с неполных головных фраз 1а типа.
Тело абзаца с головной фразой 1а типа содержит фразы лишь одного типа (фразы II, III или IV типа). В буферном массиве дополнительно используются также фразы V и VI типов.
Соответственно этому в буферном массиве дополнительно применяются два типа абзацев:
- абзац, состоящий из одной фразы V типа;
- абзац с головной фразой 1а типа, тело которого составляют фразы VI типа.
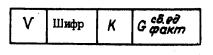
Фраза V типа предназначена для внесения фактического веса в описание сборочной единицы и содержит следующие слова в порядке их расположения внутри фразы (черт. 8):
- признак начала фразы V типа (V);
- шифр (обозначение чертежа) сборочной единицы;
- признак начала числовых констант (К);
- фактическая масса сборочной единицы ![]()
Черт. 8
Фраза VI типа предназначена для внесения фактической массы в описание детали и содержит следующие слова в порядке их расположения в фразе (черт. 9):
- признак начала фразы VI типа (VI);
- шифр (обозначение чертежа) детали;
- признак начала числовых констант (К);
- чертежная масса детали (Gчерт);
- фактическая масса детали (Gфакт).

Черт. 9
1.3. Структура каталога
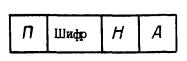
1.3.1. Каталог формируется в процессе создания банка данных и служит для ускорения поиска абзацев в банке данных при проведении расчетов. Каталог состоит из фраз переменной длины. Каждая фраза каталога содержит следующие слова в порядке их расположения внутри фразы (черт. 10):
- признак начала фразы (П);
- шифр абзаца;
- признак начала наименования (Н);
- адрес абзаца в банке данных (А).
Черт. 10
2. ФУНКЦИОНИРОВАНИЕ ОСНОВНЫХ ПРОГРАММ
2.1. Комплекс программ подразделяется на две основные группы: программы организации банка данных и каталога и программы выдачи выходной информации.
Основные программы организации банка данных и каталога, предназначенные для ЭВМ типа БЭСМ-4:
ИНК0 - программа контроля входной информации;
ПР1 - программа преобразования информации с бланков формы 2*;
__________________
* Формы здесь и далее - по ОСТ 1 00273-78.
ПР2 - программа преобразования информации с бланков формы 3;
ПР3 - программа преобразования информации с бланков формы 4;
ПР4 - программа преобразования информации с бланков формы 5;
ПР4А - программа преобразования информации с бланков формы 6;
ПР5 - программа раздвижки буферного массива;
ПР6 - программа упорядочения абзацев в зонах буферного массива;
ПР7 - программа упорядочения абзацев в буферном массиве;
ПР8 - программа упорядочения фраз внутри абзацев буферного массива;
ПР9 - программа формирования банка данных;
Каталог - программа формирования каталога.
Программа ИНК0 применяется автономно для контроля входной информации на перфокартах и используется перед вводом информации в банк данных. Остальные программы работают последовательно в процессе ввода информации автоматически вызывая друг друга.
2.2. Основные программы организации банка данных и каталога, предназначенные для ЭВМ типа ЕС:
INK0 - программа контроля входной информации;
BUF - программа преобразования информации с бланков формы 2, 3, 4, 5, 6;
SORT-2 - программа упорядочения буферного массива;
PR9 - программа формирования банка данных;
KATAL0 - программа формирования каталога.
Программа INK0 применяется автономно для контроля входной информации и используется перед вводом информации в банк данных. Остальные программы работают последовательно в процессе ввода информации в банк данных под управлением программы-диспетчера ZVF.
2.3. Основные программы выдачи выходной информации, предназначенные для ЭВМ типа ЕС (для ЭВМ типа БЭСМ-4):
MASSA (МАССА) - программа расчета и выдачи на печать весовых характеристик;
CEMS (ЦЕМО) - программа расчета и выдачи на печать центровочных и массово-инерционных характеристик;
SOTS (ОТСЕК) - программа расчета и выдачи на печать массово-инерционных характеристик по отсекам;
GRAFZ (ГРАФ) - программа выдачи графической информации на АЦПУ;
PECBD (ПЕЧАТЬ БД) - программа распечатки банка данных;
PSB (ПЕЧАТЬ СБОРОК) - программа распечатки абзацев банка данных;
PEC0 (ОШИБКИ БД) - программа поиска ошибок заполнения банка данных и выдачи на печать неполных абзацев.
Каждая из этих программ работает автономно и запускается по требованию весового подразделения.
2.4. Алгоритм программы INK0
После ввода каждой колоды перфокарт проводится логический и синтаксический контроль информации.
В начале обработки каждой колоды проводится распечатка на АЦПУ нанесенной на перфокарты информации для визуального контроля. Распечатка проводится по строкам информации с нумерацией каждой строки информации.
Под строкой информации понимается набор символов, расположенный между двумя разделителями (символами ◊ и ◊ или символами % и %), независимо от количества перфокарт, занимаемых строкой информации. После распечатки информации проводится смысловой и синтаксический контроль каждой строки информации. Строки, содержащие ошибочную информацию, выводятся на печать с фиксацией ошибки. При этом возможны следующие сообщения:
- сообщение из одной строки печати:
ПРОВЕРЬТЕ ПЕРВУЮ П-К.
Такое сообщение появляется в случае, когда информация первой перфокарты колоды не соответствует первой строке бланка с информацией;
- сообщение из двух строк печати:
печать СТРОКА НЕ СООТВЕТСТВУЕТ БЛАНКУ;
распечатка ошибочной строки.
Такое сообщение выдается, когда количество разделителей (символов *) в строке информации не соответствует типу бланка;
- сообщение из двух строк печати:
печать ОШИБКИ;
распечатка ошибочной строки.
Такое сообщение выдается в случае, когда в позиции строки отсутствуют необходимые символы или присутствуют запрещенные символы. Каждый ошибочный символ при печати заключается в квадратные скобки («[ ]»). Если ошибка состоит в отсутствии в позиции символа, то при печати в этом месте строки стоят две подряд идущие квадратные скобки («[ ]»).
2.5. Работа программ организации банка данных и каталога
2.5.1. Общая схема представлена в следующем виде (черт. 11):
- ввод входной информации;
- преобразование информации из символьного во внутренний вид ЭВМ и занесение в буферный массив;
- сортировка буферного массива в два этапа: сортировка абзацев внутри буферного массива и сортировка фраз внутри каждого абзаца;
- перезапись содержимого нового банка данных в старый банк;
- слияние старого банка данных с буферным массивом и запись полученных данных в новый банк, при этом программой выдаются на печать контрольные сообщения «СТИРАНИЕ» и «НЕТ СТИРАНИЯ»;
- формирование каталога на базе нового банка данных.
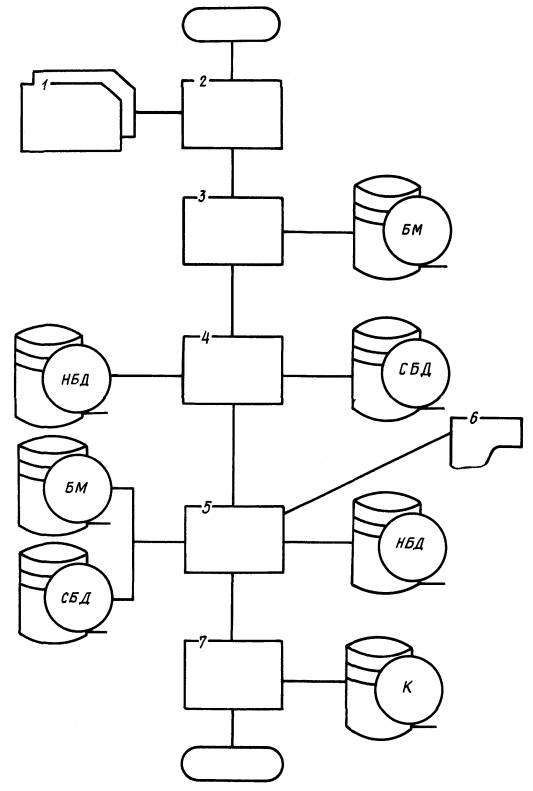
1 - входная информация на перфокартах; 2 - ввод и преобразование информации; 3 - сортировка буферного массива; 4 - перезапись нового банка данных в старый банк данных; 5 - формирование нового банка данных; 6 - печать на АЦПУ сообщений «СТИРАНИЕ», «НЕТ СТИРАНИЯ»; 7 - формирование каталога; БМ - буферный массив; НБД - новый банк данных; СБД - старый банк данных; К - каталог
Черт. 11
2.5.2. Функционирование программы «ПР1»
По данным первой строки банка создается абзац, моделирующий сборочную единицу, на которую задана информация в этой строке, и состоящий из головной фразы 1 типа. Каждая последующая строка бланка обрабатывается дважды:
- при первом преобразовании образуется неполный абзац, состоящий из двух фраз: фразы Iа типа (неполной головной фразы), шифр которой берется из первой строки, и фразы II типа (фразы-указателя), все данные которой берутся из обрабатываемой строки; полученный абзац является описанием положения системы координат нижестоящей сборочной единицы в системе координат сборочной единицы, описываемой в первой строке бланка;
- при втором преобразовании создается абзац, состоящий из одной фразы I типа, являющейся головной фразой абзаца, моделирующего сборочную единицу с шифром (обозначением чертежа), соответствующим шифру обрабатываемой строки бланка.
2.5.3. Функционирование программы «ПР2»
По данным первой строки бланка создается абзац, моделирующий сборочную единицу, на которую задана информация в этой строке, и состоящий из головной фразы I типа. При преобразовании каждой последующей строки бланка образуется неполный абзац, состоящий из двух фраз:
- фразы Iа типа, шифр которой берется из обрабатываемой строки бланка;
- фразы II типа, шифр которой берется из первой строки бланка, а остальные данные - из обрабатываемой строки бланка.
Полученный абзац содержит описание положения системы координат сборочной единицы с шифром первой строки бланка в системе координат вышестоящей сборочной единицы, имеющей шифр (обозначение чертежа), соответствующий шифру обрабатываемой строки бланка.
2.5.4. Функционирование программы «ПР3»
Информация о деталях сборочной единицы из таблицы формы 4 преобразуется в неполный абзац, состоящий из головной фразы Iа типа и набора фраз III типа (фраз-деталей). Фраза Iа типа имеет шифр, соответствующий шифру первой строки бланка. Каждая фраза III типа образуется по данным каждой последующей строки бланка. Полученный абзац является описанием деталей, входящих в сборочную единицу с шифром (обозначением чертежа), соответствующим шифру первой строки детали. Если в обрабатываемой строке есть номер части детали, то он присоединяется к шифру детали.
2.5.5. Функционирование программы «ПР4»
Информация о комплектующих изделиях таблицы, выполненной по форме 5, преобразуется в неполный абзац, состоящий из головной фразы Iа типа и набора фраз IV типа (фраз-деталей). Фраза Iа типа имеет шифр, соответствующий шифру первой строки бланка. Каждая фраза IV типа образуется по данным последующих строк бланка. Полученный абзац является описанием деталей, входящих в сборочную единицу с шифром (обозначением чертежа), соответствующим шифру первой строки бланка.
2.5.6. Функционирование программы «ПР4А»
Преобразование информации о фактической массе изделий из таблиц, выполненных по форме 6, проводится дважды:
- при первом - из каждой строки бланка образуется фраза V типа, шифр которой соответствует шифру второй позиции строки;
- при втором - образуются абзацы, состоящие из головной фразы Iа типа и фраз VI типа. Шифры фраз Iа типа берутся из первых позиций строк, шифры фраз VI типа берутся из вторых позиций строк бланка.
2.5.7. Упорядочение буферного массива (ПР 5, ПР 6, ПР 7, ПР 8)
I этап - упорядочение абзацев внутри буферного массива по возрастанию внутреннего содержания шифров головных фраз абзацев.
II этап - упорядочение фраз внутри тепа каждого абзаца по возрастанию внутреннего содержания всей фразы.
2.5.8. Формирование банка данных
I этап - перезапись нового банка в старый банк данных.
II этап - слияние упорядоченного старого банка с упорядоченным буферным массивом и запись результата в новый банк данных, при этом проводится слияние каждой группы тождественных (с одинаковыми шифрами головных фраз) абзацев буферного массива и банка данных в один абзац банка данных последовательно по одному абзацу в следующем порядке:
- слияние абзаца банка данных и первого абзаца буферного массива;
- слияние полученного абзаца банка данных со вторым абзацем буферного массива;
- слияние нового абзаца банка данных с третьим абзацем буферного массива и т.д.
Слияние каждой пары тождественных абзацев проводится в два этапа: создание головной фразы нового абзаца банка данных и создание тела нового абзаца. В качестве головной фразы выбирается головная фраза абзаца буферного массива, если это фраза I типа, в противном случае - головная фраза абзаца банка данных.
При наличии среди головных фраз тождественных абзацев фразы I типа в качестве головной ставится фраза, стоящая последней среди сливаемых фраз I типа.
При отсутствии фраз I типа в качестве головной фразы ставится фраза Iа типа.
Расстановка тождественных абзацев перед слиянием следующая: абзац банка данных, абзацы буферного массива в порядке их поступления при вводе информации. Тело нового абзаца получается как результат объединения тел всех тождественных абзацев.
![]()
где Т1, Т2 - тела сливаемых абзацев.
Из соотношения следует, что если в теле объединяемых абзацев встречаются полностью идентичные фразы, то в теле нового абзаца будет присутствовать только одна из групп идентичных фраз. Например, фразы, входящие одновременно в тела абзацев Т1, Т2, Т3 (зачерненная область на черт. 12), в новом абзаце присутствуют только один раз.
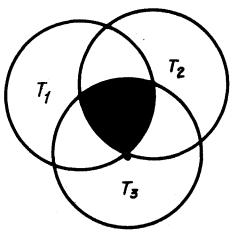
Черт. 12
Из соотношения также следует, что повторный ввод ранее введенной информации или части ее не изменит содержания соответствующих абзацев банка данных. Например, объединение тела абзаца банка данных Т1 с телом абзаца буферного массива Т абсолютно не изменит содержания тепа абзаца банка данных Т1 (черт. 13).
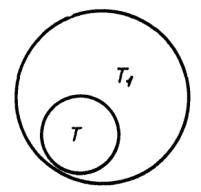
Черт. 13
В процессе слияния проводится также стирание информации из банка данных в случае, если в буферном массиве имеются фразы, содержащие признак стирания. Алгоритм стирания содержит две возможности стирания: всего абзаца или части фраз из тела абзаца.
2.5.8.1. Для стирания абзаца банка данных необходимо наличие признака стирания в головной фразе I типа тождественного абзаца буферного массива. В процессе стирания абзаца на печать АЦПУ выдается контрольное сообщение в две строки:
- печать «СТИРАНИЕ»;
- распечатка фразы I типа абзаца буферного массива.
При отсутствии в банке данных тождественного абзаца на печать АЦПУ выдается контрольное сообщение в две строчки:
- печать «НЕТ СТИРАНИЯ»;
- распечатка фразы I типа абзаца буферного массива.
2.5.8.2. Для стирания фраз из тела абзаца банка данных (ТБД) необходимо наличие в теле тождественного абзаца буферного массива (ТБМ) фраз, содержащих признак стирания, полностью идентичных стираемым фразам.
При изъятии каждой фразы на печать АЦПУ выдается контрольное сообщение в три строки:
- печать «СТИРАНИЕ»;
- шифр головной фразы абзаца буферного массива;
- распечатка стираемой фразы.
Новый абзац будет состоять из оставшихся фраз (заштрихованная область на черт. 14).
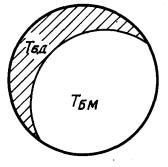
Черт. 14
Для каждой фразы тела абзаца буферного массива, содержащей признак стирания, у которой нет соответствующих идентичных фраз в теле тождественного абзаца банка данных (область 2 на черт. 15), выдается на печать АЦПУ контрольное сообщение в три строки:
- печать «НЕТ СТИРАНИЯ»;
- шифр головной фразы абзаца буферного массива;
- распечатка фразы тела абзаца буферного массива, содержащей признак стирания.
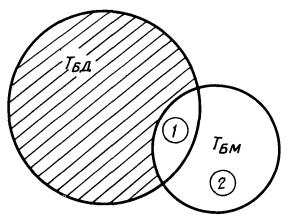
Черт. 15
2.6. Работа программы расчета весовых центровочных и массово-инерционных характеристик.
Все расчетные программы работают по одной и той же схеме. Сначала вводится шифр корневой сборочной единицы. После этого проводится расчет характеристик всех сборочных единиц, являющихся узлами иерархического дерева, порожденного корневой сборочной единицей.
При работе программ используются дополнительные массивы: «магазин» и «шкала».
Магазин - массив, организованный по принципу «первым пришел - последним ушел», служит для запоминания непройденных путей иерархического дерева. В нем проводится запись начала каждого абзаца, выбранного из банка данных, включая все фразы II типа (фразы-указатели). Считывание из магазина проводится по одной фразе с конца магазина.
Шкала представляет собой ряд последовательных массивов - полей шкалы, каждое из которых служит для накопления расчетных характеристик сборочной единицы определенного уровня:
- первое поле - для корневой сборочной единицы (сборочной единицы 0-го уровня);
- второе поле - для каждой сборочной единицы 1-го уровня;
- третье поле - для каждой сборочной единицы 2-го уровня и т.д.
При движении по ветви иерархического дерева сверху-вниз при переходе к новому уровню шкала сдвигается вправо последовательно на второе поле, на третье поле шкалы и т.д.
При движении по ветви иерархического дерева снизу-вверх шкала сдвигается влево последовательно на n-е поле, n-1-е поле шкалы и т.д.
Характеристики сборочных единиц суммируются и выдаются на печать АЦПУ.
Виды выходных документов, получаемых в результате работы программ, - по ОСТ 1 00273-78.
Процесс расчета модельного банка данных приведен в обязательном приложении.
ПРИЛОЖЕНИЕ
Обязательное
ПРОЦЕСС РАСЧЕТА МОДЕЛЬНОГО БАНКА ДАННЫХ
1. Схема работы счетных программ для изделия 100, состоящего из сборочных единиц 200, 300 и 400 (черт. 1), представлена на черт. 2.
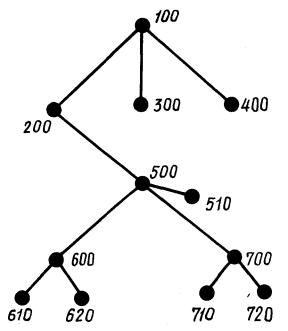
Черт. 1
2. Левая часть схемы изображает состояние шкалы, средняя часть - обрабатываемый абзац, правая часть - состояние магазина.
1-й этап. Шкала и магазин пустые. Вводится шифр корневой сборочной единицы 200.
2-й этап. Открыто для записи первое поле, на которое заносится исходная матрица направляющих косинусов и исходные координаты положения системы координат корневой сборочной единицы. По заданному шифру при помощи каталога из банка данных вызывается абзац с шифром 200. Фразы абзацев I и II типов заносятся в магазин.
3-й этап. Из магазина считывается фраза II типа, это означает движение по иерархическому дереву сверху-вниз; шкала сдвигается вправо на второе поле. По данным первого поля шкалы и фразы II типа вычисляется матрица направляющих косинусов поворота и координаты положения начала системы координат сборочной единицы с шифром 500 относительно корневой системы координат. Эти данные заносятся во второе поле шкалы. Из фразы II типа выделяется шифр, и по нему при помощи каталога из банка данных вызывается абзац с шифром 500.
Фразы абзаца I и II типов заносятся в магазин. Фраза II типа обрабатывается, и результат заносится во второе поле шкалы. Шкала сдвигается вправо, на третье поле.

Черт. 2
4-й этап. По данным второго поля шкалы и фразы II типа рассчитывается матрица направляющих косинусов углов поворота и координаты положения системы координат сборочной единицы 700 относительно корневой системы координат. Эти данные заносятся в третье поле шкалы. Из фразы II типа выделяется шифр 700, и по нему при помощи каталога из банка данных вызывается абзац с шифром 700. Фраза I типа абзаца заносится в магазин. Фраза III типа обрабатываются и результаты заносятся в третье попе шкалы.
5-й этап. Из магазина считывается очередная фраза (фраза I типа). В случае фразы I типа сдвига шкалы вправо не происходит.
По данным третьего поля шкалы и фразы I типа формируются и выдаются на печать окончательные характеристики сборочной единицы второго уровня с шифром 700. Часть данных из третьего поля шкалы добавляется к данным второго поля шкалы. Шкала сдвигается влево на второе поле шкалы, а третье поле шкалы обнуляется.
6-й этап. Проводится по схеме 4-го этапа.
7-й этап. Проводится по схеме 5-го этапа.
8-й этап. Из магазина считывается очередная фраза I типа. По данным второго поля шкалы и фразы I типа формируются и выдаются на печать окончательные характеристики сборочной единицы первого уровня с шифром 300. Часть данных из второго поля добавляется к данным первого поля шкалы. Шкала сдвигается вправо на первое поле шкалы, а второе поле обнуляется.
9-й этап. Из магазина считывается очередная фраза I типа. По данным первого поля шкалы и фразы I типа формируются и выдаются на печать окончательные характеристики корневой сборочной единицы нулевого уровня с шифром 200.
3. Блок-схема работы расчетных программ показана на черт. 3. Ниже рассматривается работа алгоритма, начиная с обработки сборочной единицы (i - 1)-го уровня. Шкала установлена на i-е поле шкалы (Шi), счетчик уровня иерархии равен i.
4. По шифру сборочной единицы в каталоге проводится поиск адреса абзаца с данным шифром в банке данных (номер зоны и начало абзаца в зоне). Поиск проводится методом деления пополам. Ввиду того, что массив каталога упорядочен, этот метод обладает большим быстродействием. Количество необходимых сравнений шифров пропорционально при этом логарифму от количества фраз каталога:
![]()
где S - среднее количество сравнения;
n - количество фраз в каталоге.
5. По найденному адресу на банка данных выделяется абзац с заданным шифром, фразы I и II типов абзаца переписываются в магазин. После этого проводится последовательная выборка фраз-деталей (фраз III и IV типов) и их обработка.
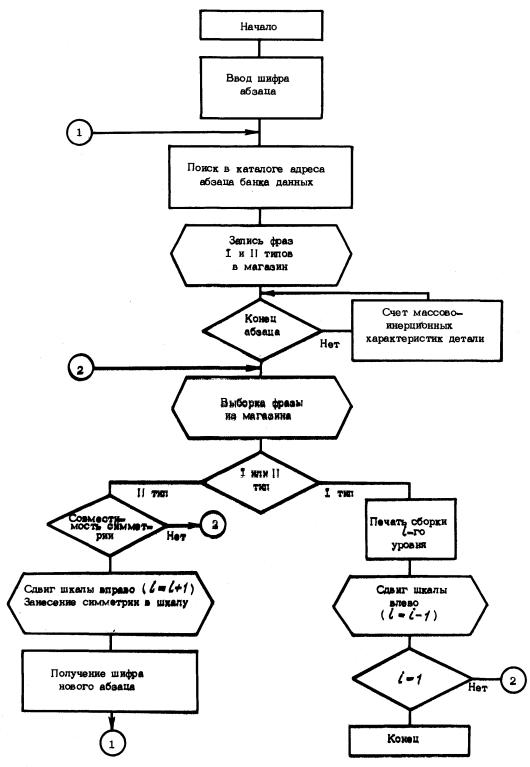
Черт. 3
Обработка заключается в подсчете массы, статических моментов, моментов инерции каждой детали относительно корневой системы координат и записи этих данных в поле шкалы. Счет проводится по таблице, приведенной на черт. 4.
|
Сборка |
|||
|
0 (нулевая) |
Л (левая) |
П (правая) |
|
|
0 (нулевая) |
G |
G |
G |
|
S |
S (-Sz) |
S |
|
|
J |
|
J |
|
|
Л (левая) |
G |
G |
Несовместимо |
|
S |
S (-Sz) |
||
|
J |
|
||
|
П (правая) |
G |
Несовместимо |
G |
|
S |
S |
||
|
J |
J |
||
|
С (симметричная) |
G = 2G |
G |
G |
|
S = 2S (Sz = 0) |
S (-S2) |
S |
|
|
|
|
G |
|
Черт. 4
Здесь показано, как меняются расчетные характеристики детали в зависимости от сочетания признаков симметрии сборочной единицы и принадлежащей ей детали.
В результате в поле шкалы накапливаются следующие характеристики:
G = {Gr, Gф, Gр} - масса;
S = {Sx, Sy, Sz} - статические моменты;
I = {Ixx, Iyy, Izz, Ixy, Ixz, Iyz} - моменты инерции.
При этом
![]()
![]()
![]() ,
,
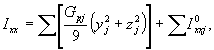
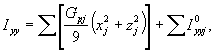
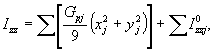
![]()
![]()
![]()
где Gpj - расчетная масса детали, равная Grj, в случае, если Gфj = 0 или Gфj, если Gфj ≠ 0;
xj, yj, zj - координаты j-й детали в корневой системе координат;
![]() - собственные моменты инерции j-й
детали в корневой системе
- собственные моменты инерции j-й
детали в корневой системе ![]() координат.
координат.
6. После обработки деталей абзаца проводится выборка очередной фразы из магазина и сравнение ее на тип фразы.
Если это фраза II типа (указатель к нижестоящей сборочной единице), то проводится проверка на совместимость признаков симметрии i-го поля шкалы (сборочной единицы) (i - 1)-го уровня и фразы II типа (сборочной единицы i-го уровня). Проверка проводится по схеме, показанной на черт. 5.
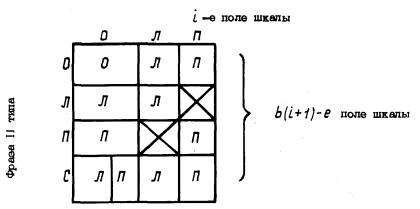
Черт. 5
В случае несовместимости признаков симметрии управление передается на выборку из магазина следующей фразы.
Если в поле шкалы стоит нулевой признак симметрии, а во фразе II типа - признак С (симметрично), то проводится такая процедура.
Во фразе II типа признак симметрии С меняется на признак П (правый), и она заносится с этим признаком симметрии обратно в магазин, а в ее копии, которая остается для дальнейшей обработки, ставится признак симметрии Л (левый).
7. В случае совместимости признаков симметрии, включая и вышеизложенный случай, по данным i-го поля шкалы и фразы II типа вычисляется матрица направляющих косинусов и координаты положения начала системы координат очередной сборочной единицы в корневой системе координат. Шкала сдвигается на одно поле вправо (Шi = Шi + ΔШ), счетчик уровня иерархии увеличивается на единицу (i = i + 1). В новое поле шкалы заносится признак симметрии, выбранный из фразы II типа, а также матрица направляющих косинусов и координаты, вычисленные по следующим соотношениям:
![]()
![]()
![]()
![]()
где Aшi, Xшi, Yшi, Zшi - вычисленные матрица направляющих косинусов и координаты, которые заносятся в i-е поле шкалы;
Aшi-1, Xшi-1, Yшi-1, Zшi-1 - матрица направляющих косинусов и координаты, которые берутся из i-го поля шкалы;
AфII, XфII, YфII, ZфII - матрица, полученная по данным фразы II типа, и координаты, взятые из фразы II типа.
Из фразы II типа выделяется шифр очередной сборочной единицы, и управление передается на поиск адреса абзаца в банке данных.
Если из магазина выбрана фраза I типа, это означает, что для данной сборочной единицы (i - 1)-го уровня проведен расчет всех входящих в нее элементов.
8. По данным фразы I типа проводится окончательное формирование i-го поля шкалы, после чего часть данных из i-го поля суммируется с соответствующими данными (i - 1)-го поля шкалы. Характеристики сборочной единицы (i - 1)-го уровня выводятся на печать, счетчик уровня иерархии уменьшается на единицу (i = i - 1), шкала сдвигается влево (Шi = Шi - ΔШ) и управление передается на выборку из магазина очередной фразы.
9. Работа заканчивается после выборки из магазина фразы I уровня, когда счетчик уровня иерархии равен 1, что соответствует окончательному расчету характеристик корневой сборочной единицы нулевого уровня.
10. Виды выходных документов, получаемых в результате работы программ, - по ОСТ 1 00273-78.
ПЕРЕЧЕНЬ ОБОЗНАЧЕНИЙ ССЫЛОЧНОЙ ДОКУМЕНТАЦИИ, ИСПОЛЬЗУЕМОЙ В СТАНДАРТЕ
ОСТ 1 00273-78.
СОДЕРЖАНИЕ