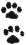 | Информационная система | |
ГОСТ Р 51294.9-2002
(ИСО/МЭК 15438-2001)
ГОСУДАРСТВЕННЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ
Автоматическая идентификация
КОДИРОВАНИЕ ШТРИХОВОЕ
Спецификации символики PDF417 (ПДФ417)
ГОССТАНДАРТ РОССИИ
Москва
Предисловие
1 РАЗРАБОТАН Ассоциацией автоматической идентификации ЮНИСКАН/EAN РОССИЯ/AIM РОССИЯ совместно с ЗАО «Фирма ПИЛОТ»
ВНЕСЕН Техническим комитетом по стандартизации ТК 355 «Автоматическая идентификация»
2 ПРИНЯТ И ВВЕДЕН В ДЕЙСТВИЕ Постановлением Госстандарта России от 26 августа 2002 г. № 314-ст
3 Настоящий стандарт представляет собой аутентичный текст международного стандарта ИСО/МЭК 15438-2001 «Информационная технология. Технологии автоматической идентификации и сбора данных. Спецификации символики штрихового кода ПДФ417» (ISO/IEC 15438-2001 «Information Technology Automatic Identification and Data Capture - Bar code symbology specifications - PDF417»), за исключением раздела «Библиография», и приложений V, W, X. Дополнительные положения выделены курсивом.
При применении настоящего стандарта рекомендуется использовать вместо ссылочных международных стандартов соответствующие им межгосударственные стандарты, сведения о которых приведены в дополнительном приложении W, и государственные стандарты Российской Федерации, сведения о которых приведены в дополнительном приложении X.
4 ВВЕДЕН ВПЕРВЫЕ
СОДЕРЖАНИЕ
Введение
Технология штрихового кодирования основана на распознавании комбинаций штрихов и пробелов определенных размеров. Существуют множество методов кодирования информации в формате штрихового кода, именуемых символиками, и множество правил перевода знаков в комбинации штрихов и пробелов и других важных параметров, именуемых спецификациями символики.
Производителям оборудования для штрихового кодирования и пользователям технологии штрихового кодирования необходим общедоступный стандарт спецификаций символики, к которому можно обращаться при разработке оборудования или стандартов применений. Символика, представленная в данном стандарте, является общественным достоянием и не подлежит ограничениям для пользователей, лицензированию и взиманию взносов.
ГОСТ Р 51294.9-2002
(ИСО/МЭК 15438-2001)
ГОСУДАРСТВЕННЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ
Автоматическая идентификация
КОДИРОВАНИЕ ШТРИХОВОЕ
Спецификации символики PDF417 (ПДФ417)
Automatic identification. Bar coding.
Symbology specifications PDF417
Дата введения 2003-01-01
1 Область применения
Настоящий стандарт устанавливает:
- требования к символике штрихового кода PDF-417;
- показатели символики PDF-417, кодирование знаков данных, форматы символов, размеры, правила коррекции ошибки, алгоритм декодирования и совокупность параметров применения.
2 Нормативные ссылки
В настоящем стандарте использованы ссылки на следующие стандарты1:
ИСО 646-91 Информационная технология - 7-битный кодированный набор знаков ИСО для обмена информацией
ИСО 8859-1-98 Обработка информации. Наборы 8-битных однобайтовых кодированных графических символов. Часть 1. Латинский алфавит № 1
ИСО/МЭК 15416-2000 «Информационная технология. Технологии автоматической идентификации и сбора данных. Спецификации испытаний качества печати штриховых кодов. Линейные символы»
ЕН 796-96 Штриховое кодирование. Идентификаторы символик
ЕН 1556-98 Штриховое кодирование. Терминология
1 Соответствие межгосударственных стандартов и государственных стандартов Российской Федерации международным стандартам приведено в приложениях W и X. Международные спецификации, указанные в разделе 2 ИСО/МЭК 15438, перенесены в раздел «Библиография» ([1] и [5]).
3 Определения, обозначения и сокращения
3.1 Определения
Применительно к настоящему стандарту использованы следующие термины и определения, данные в ЕН 1556:
Алгоритм (algorithm), стандарт применения (application standard), версия КОИ-7 (ASCII), автораспознавание (autodiscrimination), штрих (bar), штриховой код (bar code), двунаправленность декодирования (bi-directional), двоичный (binary), бит (bit), кодовое слово (codeword), столбец символа штрихового кода (column), непрерывный штриховой код (continuous code), знак данных (data character), кодовое слово данных (data codeword), уплотнение данных (data compaction), поле данных символа (data region), алгоритм декодирования (decode algorithm), декодер (decoder), элемент символа штрихового кода (element), кодирование (encode), уровень коррекции ошибок (error correction level), визуальное представление знаков (human readable character), начальные нули (leading zeros), линейная символика (linear symbology), модуль (module), расчет «по модулю» контрольного знака (modulo), многострочная символика (multi-row symbology), n, k символика (n, k symbology), набор цифровых знаков (numeric), дополнение символа штрихового кода (overhead), знак-заполнитель (pad character), кодовое слово-заполнитель (pad codeword), свободная зона (quiet zone), рекомендуемый алгоритм декодирования (reference decode algorithm), строка символа штрихового кода (row), сканер (scanner), самоконтроль знака символа штрихового кода (self-checking), пробел символа штрихового кода (space), знак СТАРТ (start character), знак СТОП (stop character), коэффициент сжатия символа штрихового кода (symbol aspect ratio), знак символа (symbol character), символика штрихового кода (symbology), идентификатор символики (symbology identifier), длина символа штрихового кода (symbol width), размер X (X-dimension), размер Y (Y-dimension).
В настоящем стандарте применяют также следующие термины с соответствующими определениями:
3.1.1 модель базового канала (Basic Channel Model): Стандартная система кодирования и передачи данных штрихового кода, в которой с выхода декодера поступают байты данных сообщения, но не передается никакой управляющей информации о сообщении.
Примечание - В соответствии с данной моделью декодер работает в режиме базового канала
3.1.2 последовательность штрихов и пробелов (bar-space sequence): Последовательность, представляющая ширину элементов знака символа в модулях.
3.1.3 кластер (cluster): Одно из трех подмножеств самостоятельных знаков символа PDF417, в котором знаки символа соответствуют особым структурным правилам, используемым при декодировании символики.
3.1.4 режим уплотнения (compaction mode): Наименование каждого из трех алгоритмов уплотнения данных PDF417: режим текстового уплотнения (Text Compaction mode), режим цифрового уплотнения (Numeric Compaction mode) и режим байтового уплотнения (Byte Compaction mode), эффективно преобразующих 8-битные байты данных в кодовые слова PDF417.
3.1.5 кодовое слово коррекции ошибок (Error correction codeword): Кодовое слово в символе, которое кодирует значение, получаемое из алгоритма исправления ошибок кодовых слов для декодирования обнаруженных ошибок и их исправления в зависимости от уровня коррекции ошибок.
3.1.6 интерпретация расширенного канала (Extended Channel Interpretation): Процедура, применяемая в некоторых символиках, включая PDF417, для точной замены интерпретации по умолчанию иной интерпретацией.
Примечание - Интерпретация, изначально предназначенная для формирования символа, может быть восстановлена после декодирования сканированного символа для воссоздания сообщения данных в его исходном формате.
3.1.7 модель расширенного канала (Extended Channel Model): Система кодирования и передачи байтов данных сообщения и управляющей информации о сообщении, в которой управляющая информация передается с использованием управляющей последовательности интерпретации расширенного канала.
Примечание - Декодер, соответствующий данной модели, работает в режиме расширенного канала.
3.1.8 функциональное кодовое слово (function codeword): Кодовое слово в символике, которое инициирует определенную операцию в символике.
Примечание - Функциональное кодовое слово используется, например, для перехода между кодированными наборами данных, вызова схемы уплотнения, программирования считывающего устройства и вызова интерпретаций расширенного канала.
3.1.9 идентификатор глобальной метки (Global Label Identifier): Процедура в рамках символики PDF417, предназначенная для замены интерпретации по умолчанию иной интерпретацией.
Примечания:
1 Назначение указанной процедуры идентично назначению интерпретации расширенного канала.
2 Связанная с символикой система идентификаторов глобальных меток предшествовала независимой от символики системе интерпретации расширенного канала.
3.1.10 Макро PDF417 (Macro PDF417): Процедура в символике PDF417 по логической передаче данных из компьютерного файла в комплект связанных символов PDF417.
Примечания:
1 Эта процедура значительно расширяет емкость данных по сравнению с емкостью единичного символа.
2 Настоящая процедура подобна параметру структурированного соединения, применяемому в других символиках.
3.1.11 кодовое слово фиксации в режиме (Mode Latch codeword): Кодовое слово, которое используется для перехода из одного режима в другой, который будет действовать до применения кодового слова фиксации в режиме или регистра в режиме, либо до окончания символа.
3.1.12 кодовое слово регистра в режиме (Mode Shift codeword): Кодовое слово, которое используется для перехода из одного режима в другой только для одного кодового слова, после чего режим кодирования возвращается к исходному.
3.1.13 кодовое слово индикатора строки (Row Indicator codeword): Кодовое слово PDF417, примыкающее к знаку СТАРТ или знаку СТОП в строке, которое кодирует информацию о структуре символа PDF417: идентификацию строки, общее количество строк и столбцов и уровень коррекции ошибки.
3.1.14 кодовое слово дескриптора длины символа (Symbol Length Descriptor): Кодовое слово в символе PDF417, кодирующее общее количество кодовых слов данных в символе.
Примечание - Дескриптор длины символа всегда должен быть первым кодовым словом в символе PDF417.
3.2 Обозначения математических символов и операций
В настоящем стандарте используются следующие обозначения математических символов, которые согласуются с наиболее общим использованием системы счисления:
A - коэффициент сжатия символа (symbol aspect ratio) PDF417 (отношение высоты к длине);
b - ширина элемента в знаке символа;
c - количество столбцов в символе в области данных (за исключением знаков СТАРТ и СТОП и кодовых слов индикаторов строк);
d - кодовое слово данных, включая все функциональные кодовые слова;
E - кодовое слово коррекции ошибок;
e - расстояние между подобными краями в знаке символа;
F - номер строки;
f - количество ошибок подстановки;
H - высота символа, включая свободную зону;
K - номер кластера;
k - количество кодовых слов коррекции ошибок;
L - левый индикатор строки (Left row indicator);
L - количество стираний;
M - количество первоначальных кодовых слов данных, предшествующих дополнению дескриптора длины символа и любых кодовых слов-заполнителей (pad);
N - общее количество кодовых слов данных, включая дескриптор длины символа и все кодовые слова-заполнители;
P - шаг или ширина знака символа;
QH - горизонтальная свободная зона;
QV - вертикальная свободная зона;
R - правый индикатор строки (Right row indicator);
r - число строк в символе;
s - уровень коррекции ошибок;
W - длина символа, включая свободную зону;
X - размер X или ширина модуля;
Y - высота модуля (также именуется высотой строки).
В настоящем стандарте используют также следующие обозначения для математических операций:
div - оператор целоисчисленного деления с округлением в меньшую сторону;
INT - целое число, полученное в результате округления в меньшую сторону до целого значения, с отбрасыванием десятых долей;
mod - положительный остаток целого числа после деления.
Примечание - Если остаток окажется отрицательным, для получения положительного результата прибавляют значение делителя. Например, остаток от деления -29160 на 929 равен -361. При прибавлении к остатку -361 делителя 929 получают положительное значение 568.
3.3 Сокращения
В настоящем стандарте применяют следующие сокращения:
ECI - интерпретация расширенного канала;
GLI - идентификатор глобальной метки.
4 Требования к символике PDF417
4.1 Показатели символики
4.1.1 Основные показатели
Символика штрихового кода PDF417 (русское обозначение ПДФ417) имеет следующие основные показатели:
a) кодируемый набор знаков:
в режиме текстового уплотнения (4.4.2) позволяет кодировать все графические знаки КОИ-7, т.е. знаки с десятичными значениями от 32 до 126 включительно в соответствии с ИСО/МЭК 646*, а также некоторые управляющие знаки,
в режиме байтового уплотнения (4.4.3) позволяет кодировать все 256 значений 8-битных байтов. Этот режим включает все знаки КОИ-7 с десятичными значениями от 0 до 127 включительно и предусматривает поддержку международных наборов знаков,
в режиме цифрового уплотнения (4.4.4) позволяет эффективно кодировать цифровые последовательности данных,
различные функциональные кодовые слова для управления;
* Версия 7-битного кодированного набора знаков для обмена и обработки информации по ИСО 646 соответствует набору С0 ссылочной версии КОИ-7Н0 по ГОСТ 27463 и набору Г0 версии КОИ-8 B1 по ГОСТ Р 34.303. В ИСО/МЭК 15438 указанная версия обозначена как ASCII.
b) структура знака символа: знаки (n, k, m), представленные 17 модулями (n), элементами - 4 штрихами и 4 пробелами (k), с самым крупным элементом шириной в 6 модулей (m);
c) максимально возможное количество знаков данных в символе (при нулевом уровне коррекции ошибок) - 925 кодовых слов данных, позволяющих закодировать:
в режиме текстового уплотнения - 1850 знаков (2 знака данных на кодовое слово),
в режиме байтового уплотнения - 1108 знаков (1,2 знака данных на кодовое слово),
в режиме цифрового уплотнения - 2710 знаков (2,93 знака данных на кодовое слово).
При минимальном рекомендуемом уровне коррекции ошибок (error correction level) имеется 863 кодовых слов данных, позволяющих закодировать:
в режиме текстового уплотнения - 1726 знаков (2 знака данных на кодовое слово),
в режиме байтового уплотнения - 1033 знака (1,2 знака данных на кодовое слово),
в режиме цифрового уплотнения - 2528 знаков (2,93 знака данных на кодовое слово);
d) размер символа:
количество строк - от 3 до 90,
количество столбцов - от 1 до 30,
длина в модулях - от 90X до 583X, включая свободные зоны,
максимальное количество кодовых слов - 928,
максимальное количество кодовых слов данных - 925.
Поскольку может быть задано как число строк, так и число столбцов, при печати может быть изменен и коэффициент сжатия символа PDF417 для выполнения требований по размещению;
e) задаваемая коррекция ошибок - от 2 до 510 кодовых слов на символ (4.7);
f) знаки, не относящиеся к знакам данных:
на строку - 73 модуля, включая свободные зоны,
на символ - не менее трех дополнительных кодовых слов, представленных в виде знаков символа;
g) тип кода - непрерывный, многострочный, двухмерный;
h) самоконтроль знака - присутствует;
i) двунаправленное декодирование - присутствует.
4.1.2 Дополнительные свойства
В символике PDF417 к дополнительным свойствам (обязательным или необязательным) относят:
a) уплотнение данных (обязательное свойство).
Установлены три схемы уплотнения совокупности знаков данных в кодовые слова. Обычно данные непосредственно не представляются на основе «один знак - одно кодовое слово» (4.4.2 - 4.4.4);
b) интерпретации расширенного канала (необязательное свойство).
Данный механизм позволяет кодировать до 811800 различных наборов знаков данных или интерпретаций (4.5);
c) Макро PDF417 (необязательное свойство).
Данный механизм предоставляет логическое и последовательное представление файлов данных в ряде символов PDF417. Таким образом, вплоть до 99999 символов PDF417, могут быть связаны или соединены и отсканированы в любом порядке для правильного восстановления исходного файла данных (4.13);
d) декодируемость от края до края (обязательное свойство).
PDF417 может декодироваться измерением размеров от края одного элемента знака символа до соответствующего края другого элемента (4.3.1);
e) перекрестное сканирование строк (обязательное свойство).
Для перекрестного сканирования строк в PDF417 используют сочетание трех следующих показателей:
- синхронизацию по горизонтали или синхронизацию по времени,
- идентификацию строки,
- синхронизацию по вертикали использованием значения кластеров для обеспечения локального распознавания строк.
При использовании данного сочетания одиночное линейное сканирование при пересечении ряда строк позволяет получить неполное декодирование данных, если хотя бы один полный знак символа в строке был декодирован и получено значение его кодового слова. В дальнейшем с помощью алгоритма декодирования отдельные кодовые слова могут быть соединены в значащую матрицу;
f) коррекция ошибок (обязательное свойство).
Пользователь может задать один из девяти уровней коррекции ошибок. На всех уровнях, кроме нулевого, возможно не только обнаружение ошибок, но и исправление ошибочно закодированных или недостающих кодовых слов (4.7);
g) Компакт PDF417 (Compact PDF417) (необязательное свойство).
В относительно «чистой» среде возможно сокращение некоторых строк со знаками, не относящимися к данным (4.12).
Примечание - В предыдущей версии показателей PDF417 данное свойство именовалось «Сокращенный PDF417» («Truncated PDF417»). Термин Компакт PDF417 (Compact PDF417) является предпочтительным во избежание путаницы с наиболее общим использованием термина «сокращенный» (‘truncated’).
4.2 Структура символа
4.2.1 Параметры символа PDF417
Любой символ PDF417, состоящий из множества выровненных по вертикали строк, должен содержать не менее трех строк (но не более 90). Любая строка должна содержать не менее одного знака символа (но не более 30 знаков символа) без учета столбцов знаков СТАРТ, СТОП и столбцов индикатора строк. Символ должен включать свободные зоны со всех 4-х сторон. На рисунке 1 приведен символ PDF417 с закодированными данными: PDF417 Symbology Standard.

Рисунок 1 - Структура символа PDF417.
4.2.2 Параметры строки
Каждая строка PDF417 должна содержать:
a) начальную свободную зону,
b) знак СТАРТ,
c) знак символа левого индикатора строки,
d) от 1 до 30 знаков символа,
e) знак символа правого индикатора строки,
f) знак СТОП,
g) конечную свободную зону.
Примечание - Число знаков символа (или кодовых слов), приведенных в перечислении d), соответствует числу столбцов в символе PDF417.
4.2.3 Последовательность кодовых слов
Символ PDF417 может содержать до 928 знаков символа или кодовых слов.
Примечание - Термин «Знак символа PDF417» рекомендуется использовать для обозначения напечатанной комбинации штрихов и пробелов; «кодовое слово» - для числового значения знака символа.
Кодовые слова должны быть приведены в следующей последовательности:
a) первое кодовое слово - дескриптор длины символа - всегда должно кодировать общее количество кодовых слов данных в символе, включая сам дескриптор длины символа, кодовые слова данных и кодовые слова-заполнители, за исключением числа кодовых слов коррекции ошибок;
b) кодовые слова формируют по старшинству разрядов подлежащих кодированию знаков. Могут быть вставлены функциональные знаки для уплотнения данных;
c) кодовые слова-заполнители помогают представлять последовательности кодовых слов в виде прямоугольной матрицы. Кодовые слова-заполнители можно также использовать для формирования дополнительных полных конечных строк с целью получения желаемого коэффициента сжатия или установленного в нормативном документе по применению;
d) необязательный управляющий блок Макро PDF417;
e) кодовые слова коррекции ошибки для обнаружения и исправления ошибок.
Кодовые слова должны быть расположены таким образом, чтобы кодовое слово позиции старшего разряда примыкало к дескриптору длины символа (Symbol Length Descriptor), а кодовые слова кодировались слева направо от верхнего ряда к нижнему. На рисунке 2 представлена в виде схемы последовательность для символа, подобного представленному на рисунке 1. На рисунке 2 используется уровень коррекции ошибок 1 и требуется одно кодовое слово для полного заполнения матрицы символа.
|
L1 |
d15 |
d14 |
R1 |
СТОП |
|
|
L2 |
d13 |
d12 |
R2 |
||
|
L3 |
d11 |
d10 |
R3 |
||
|
L4 |
d9 |
d8 |
R4 |
||
|
L5 |
d7 |
d6 |
R5 |
||
|
L6 |
d5 |
d4 |
R6 |
||
|
L7 |
d3 |
d2 |
R7 |
||
|
L8 |
d1 |
d0 |
R8 |
||
|
L9 |
E3 |
E2 |
R9 |
||
|
L10 |
E1 |
E0 |
R10 |
Обозначения: d15 - дескриптор длины символа; d14 - d1 - закодированное представление данных; d0 - кодовое слово-заполнитель.
Рисунок 2 - Пример схемы размещения символа PDF417
Примечание - Значения L, R, d и Е определены в 3.2.
Правила и рекомендации по определению структуры матрицы приведены в 4.9.
4.3 Основное кодирование
4.3.1 Структура знака символа
Каждый знак символа PDF417 должен состоять из следующих элементов: четырех штрихов и четырех пробелов, ширина каждого из которых может быть от 1 до 6 модулей. Совокупная ширина 4 штрихов и 4 пробелов должна составлять 17 модулей. Знаки символа PDF417 могут быть декодированы путем измерения расстояний «e» внутри знака.
Каждый знак символа задается последовательностью штрихов и пробелов из восьми цифр, которые представляют ширину в модулях каждого из восьми элементов этого знака символа. На рисунке 3 представлен знак символа с последовательностью штрихов и пробелов 51111125.
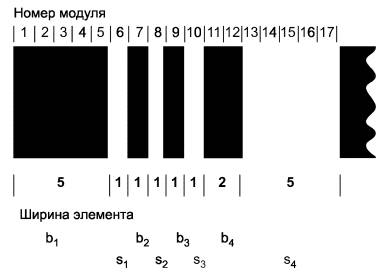
Рисунок 3 - Знак символа PDF417.
В PDF417 имеется 929 установленных значений знаков символа (кодовых слов), пронумерованных от 0 до 928.
Кодовые слова представлены в виде трех взаимно исключающих наборов знаков символа или кластеров. Каждый кластер кодирует 929 допустимых кодовых слов PDF417 в виде различных комбинаций штрихов и пробелов так, что один кластер отличается от другого. Кластеры обозначают номерами 0, 3, 6. Задание кластера распространяется на все знаки символа PDF417, за исключением знаков СТАРТ и СТОП.
Номер кластера K определяют по следующей формуле
K = (b1 - b2 + b3 - b4 + 9) mod 9,
где b1, b2, b3 и b4 - ширина в модулях соответственно четырех штрихов.
Номер кластера K для знака символа, представленного на рисунке 3, составляет
K = (5 - 1 + 1 - 2 + 9) mod 9 = 3.
Значения кодовых слов и последовательности штрихов и пробелов для каждого кластера знаков символа приведены в приложении А.
4.3.2 Знаки СТАРТ и СТОП
Знаки СТАРТ и СТОП должны быть представлены в соответствии с таблицей 1 и рисунком 4.
Таблица 1 - Последовательность штрихов и пробелов для знаков СТАРТ и СТОП
|
Последовательность штрихов и пробелов |
|||||||||
|
B |
S |
B |
S |
B |
S |
B |
S |
В |
|
|
СТАРТ |
8 |
1 |
1 |
1 |
1 |
1 |
1 |
3 |
|
|
СТОП |
7 |
1 |
1 |
3 |
1 |
1 |
1 |
2 |
1 |
Примечания:
1 Знаки PDF417 СТАРТ и СТОП уникальны тем, что в них присутствуют элементы шириной более 6 модулей.
2 Знак СТОП имеет один дополнительный элемент - штрих шириной 1 модуль.
Последовательность штрихов и пробелов в знаках СТАРТ и СТОП должна быть одинаковой для всех строк.

Рисунок 4 - Знаки PDF417 СТАРТ и СТОП.
4.4 Высокоуровневое кодирование данных
Высокоуровневое кодирование преобразовывает знаки данных в соответствующие им значения кодовых слов.
При высокоуровневом кодировании используют схемы уплотнения данных. Соответствие заданных пользователем данных и последовательностей кодовых слов в PDF417 устанавливают три режима уплотнения данных:
текстовое (4.4.2),
байтовое (4.4.3),
цифровое (4.4.4).
Данная цепочка байтов данных может быть представлена различными последовательностями кодовых слов, в зависимости от кодирования переходов между режимами и подрежимами уплотнения. В символе PDF417 нет специального способа кодирования данных.
В каждом режиме предусмотрены 900 кодовых слов для кодирования данных и иных функций в рамках этого режима. Оставшиеся 29 кодовых слов предназначены для специальных функций (4.4.1), независимых от текущего режима уплотнения.
PDF417 также поддерживает систему интерпретации расширенного канала, позволяющую точно кодировать разные интерпретации данных в символе (4.5).
4.4.1 Функциональные кодовые слова
Кодовые слова со значениями от 900 до 928 (далее - кодовые слова от 900 до 928) назначены в качестве функциональных кодовых слов:
- для переключения между режимами (4.4.1.1),
- для усовершенствованных применений, использующих интерпретации расширенного канала,
- для других усовершенствованных применений (4.4.1.3 и 4.4.1.4).
В настоящее время кодовые слова от 903 до 912 и от 914 до 920 зарезервированы. В таблице 2 приведен полный список назначенных и зарезервированных функциональных кодовых слов, функции которых установлены в 4.4.1.1 - 4.4.1.4. Зарезервированные кодовые слова представлены в 4.4.6.
Таблица 2 - Назначение функциональных кодовых слов PDF417
|
Значение кодового слова |
Функция |
Наименование кодового слова |
Пункт настоящего стандарта |
|
|
русское |
международное |
|||
|
900 |
Фиксация режима в режиме текстового уплотнения |
Фиксация в режиме текстового уплотнения |
Text Compaction mode latch |
|
|
901 |
Фиксация режима в режиме байтового уплотнения |
Фиксация в режиме байтового уплотнения |
Byte Compaction mode latch |
|
|
902 |
Фиксация режима в режиме цифрового уплотнения |
Фиксация в режиме цифрового уплотнения |
Numeric Compaction mode latch |
|
|
903 - 912 |
Зарезервированы |
- |
- |
- |
|
913 |
Переключение регистра в режим байтового уплотнения |
Регистр в режиме байтового уплотнения |
mode shift to Byte Compaction mode |
|
|
914 - 920 |
Зарезервированы |
- |
- |
- |
|
921 |
Инициализация считывающего устройства |
Инициализация считывающего устройства |
reader initialization |
|
|
922 |
Конечное кодовое слово для управляющего блока Макро PDF417 |
Ограничитель Макро PDF417 |
Macro PDF417 Terminator |
|
|
923 |
Метка последовательности для идентификации необязательных полей в управляющем блоке Макро PDF417 |
Начало необязательного поля Макро PDF417 |
Beginning of Macro PDF417 Optional Field |
|
|
924 |
Фиксация режима в режиме байтового уплотнения (используется отлично от 901) |
Фиксация в режиме байтового уплотнения |
Byte Compaction mode latch |
|
|
925 |
Идентификатор для задаваемой пользователем интерпретации расширенного канала |
Идентификатор ECI пользователя |
identifier for a user defined ECI |
|
|
926 |
Идентификатор общего назначения формата ECI |
Идентификатор общего назначения формата ECI |
identifier for a general purpose ECI format |
|
|
927 |
Идентификатор ECI для набора знаков или кодовой страницы |
Идентификатор ECI для набора знаков или кодовой страницы |
identifier for an ECI of a character set or code page |
|
|
928 |
Кодовое слово - Макро-метка для указания начала управляющего блока Макро PDF |
Начало управляющего блока Макро PDF417 или Макро-маркер |
Beginning of Macro PDF417 Control Block or Macro marker |
|
4.4.1.1 Функциональные коды для перехода режима
В одном символе PDF417 предусмотрена возможность двухстороннего переключения режимов с требуемой частотой. Рекомендации по выбору режимов приведены в 4.4.5.
Для перехода из текущего режима в требуемый режим (который будет оставаться в действии до тех пор, пока он не будет изменен на другой) должно использоваться кодовое слово фиксации в режиме. Для этой функции предназначены кодовые слова 900 - 902 и 924 (таблица 3).
Таблица 3 - Кодовые слова установления режима и перехода между режимами
|
Фиксация в режиме |
Регистр в режиме |
|
|
Текстовое уплотнение |
900 |
913 |
|
Байтовое уплотнение |
901/924 |
|
|
Цифровое уплотнение |
902 |
Примечание - В таблице указаны кодовые слова, используемые для перехода в требуемый режим.
Кодовое слово регистра в режиме 913 вызывает временный переход из режима текстового уплотнения в режим байтового уплотнения. Этот переход действует только для следующего кодового слова, после чего должен вернуться прежний подрежим режима текстового уплотнения. Кодовое слово 913 может применяться только в режиме текстового уплотнения; его использование установлено в 4.4.2.4.
Порядок перехода между тремя режимами установлен в таблице 4 и на рисунке 5.
Таблица 4 - Таблица перехода между режимами, представляющая кодовые слова и их функции
|
Исходный режим |
Кодовое слово, используемое для перехода в требуемый режим |
||
|
текстового уплотнения |
байтового уплотнения |
цифрового уплотнения |
|
|
Текстовое уплотнение |
900 (фиксация в режиме текстового уплотнения) |
913 (регистр в режиме байтового уплотнения) 901 (фиксация в режиме байтового уплотнения) 924 (фиксация в режиме байтового уплотнения) |
902 (фиксация в режиме цифрового уплотнения) |
|
Байтовое уплотнение |
900 (фиксация в режиме текстового уплотнения) |
901 (фиксация в режиме байтового уплотнения) 924 (фиксация в режиме байтового уплотнения) |
902 (фиксация в режиме цифрового уплотнения) |
|
Цифровое уплотнение |
900 (фиксация в режиме текстового уплотнения) |
901 (фиксация в режиме байтового уплотнения) 924 (фиксация в режиме байтового уплотнения) |
902 (фиксация в режиме цифрового уплотнения) |
![]() Регистр в режиме (Mode Shift)
Регистр в режиме (Mode Shift)
![]() Фиксация в режиме (Mode Latch)
Фиксация в режиме (Mode Latch)
Рисунок 5 - Возможные переходы между режимами.
Правила перехода в режим байтового уплотнения приведены в 4.4.3.1.
4.4.1.2 Функциональные кодовые слова для перехода к интерпретациям расширенного канала
Кодовое слово интерпретации расширенного канала (кодовое слово ECI) может быть использовано для перехода к особой интерпретации, которая будет действовать до другого кодового слова ECI или до окончания данных. Для этой функции назначены кодовые слова от 925 до 927 (4.5).
4.4.1.3 Функциональные кодовые слова для Макро PDF417
Символы Макро PDF417 (в соответствии с 4.13) должны использовать кодовое слово 928 в начале управляющего блока Макро PDF417. Кодовые слова 922 и 923 используют для особых функций в Макро PDF417.
4.4.1.4 Функциональное кодовое слово для инициализации считывающего устройства
Кодовое слово используют для указания считывающему устройству, что данные, заключенные внутри символа, являются программным кодом для инициализации считывающего устройства. Кодовое слово 921 должно быть первым кодовым словом после дескриптора длины символа. В случае применения последовательности инициализации Макро PDF417 в каждом символе должно появляться кодовое слово 921.
Данные, содержащиеся в инициализации символа или в последовательности символов, не должны передаваться считывающим устройством.
4.4.2 Режим текстового уплотнения
Режим текстового уплотнения включает все графические знаки версии КОИ-7 (т.е. знаки с десятичными значениями от 32 до 126) и три управляющих знака версии КОИ-7: ГТ (НТ) или ГОРИЗОНТАЛЬНОЕ ТАБУЛИРОВАНИЕ (десятичное значение знака 9), ПС (LF) или ПЕРЕВОД СТРОКИ (десятичное значение знака 10), и ВК (CR) или ВОЗВРАТ КАРЕТКИ (десятичное значение знака 13).
Примечание - В скобках приведены международные обозначения управляющих знаков (приложение V).
Режим текстового уплотнения предусматривает также различные знаки с функциями фиксации и переключения регистра, которые используют исключительно в рамках режима текстового уплотнения.
В режиме текстового уплотнения осуществляется кодирование до двух знаков в кодовом слове. Правила уплотнения для преобразования данных в кодовые слова PDF417 приведены в 4.4.2.2. Переключения подрежимов приведены в 4.4.2.3.
4.4.2.1 Подрежимы режима текстового уплотнения
Режим текстового уплотнения предусматривает четыре подрежима:
- прописных букв (Alpha) (прописные буквы латинского алфавита),
- строчных букв (Lower) (строчные буквы латинского алфавита),
- смешанных знаков (Mixed) (числа и некоторые знаки пунктуации),
- знаков пунктуации (Punctuation).
В каждом подрежиме содержится 30 знаков, в том числе знаки фиксации в подрежиме (sub-mode latch) и регистра в подрежиме (sub-mode shift).
Режимом уплотнения по умолчанию для PDF417 должен быть режим текстового уплотнения в подрежиме прописных букв. При переходе из другого режима кодовое слово фиксации в режиме текстового уплотнения должно всегда переключать в подрежим прописных букв режима текстового уплотнения.
Все знаки и их значения приведены в таблице 5.
Таблица 5 - Определение подрежимов режима текстового уплотнения
|
Подрежимы режима текстового уплотнения |
||||||||
|
прописных букв (Alpha) |
строчных букв (Lower) |
смешанных знаков (Mixed) |
знаков пунктуации (Punctuation) |
|||||
|
Знак |
КОИ-7 |
Знак |
КОИ-7 |
Знак |
КОИ-7 |
Знак |
КОИ-7 |
|
|
0 |
А |
65 |
а |
97 |
0 |
48 |
; |
59 |
|
1 |
В |
66 |
b |
98 |
1 |
49 |
< |
60 |
|
2 |
С |
67 |
с |
99 |
2 |
50 |
> |
62 |
|
3 |
D |
68 |
d |
100 |
3 |
51 |
@ |
64 |
|
4 |
Е |
69 |
е |
101 |
4 |
52 |
[ |
91 |
|
5 |
F |
70 |
f |
102 |
5 |
53 |
\ |
92 |
|
6 |
G |
71 |
g |
103 |
6 |
54 |
] |
93 |
|
7 |
Н |
72 |
h |
104 |
7 |
55 |
_ |
95 |
|
8 |
I |
73 |
i |
105 |
8 |
56 |
‘ |
96 |
|
9 |
J |
74 |
j |
106 |
9 |
57 |
~ |
126 |
|
10 |
К |
75 |
k |
107 |
& |
38 |
! |
33 |
|
11 |
L |
76 |
l |
108 |
ВК (CR) |
13 |
ВК (CR) |
13 |
|
12 |
М |
77 |
m |
109 |
ГТ (НТ) |
9 |
ГТ (НТ) |
9 |
|
13 |
N |
78 |
n |
110 |
, |
44 |
, |
44 |
|
14 |
О |
79 |
o |
111 |
: |
58 |
: |
58 |
|
15 |
P |
80 |
p |
112 |
# |
35 |
ПС (LF) |
10 |
|
16 |
Q |
81 |
q |
113 |
- |
45 |
- |
45 |
|
17 |
R |
82 |
r |
114 |
. |
46 |
. |
46 |
|
18 |
S |
83 |
s |
115 |
$ |
36 |
$ |
36 |
|
19 |
T |
84 |
t |
116 |
/ |
47 |
/ |
47 |
|
20 |
U |
85 |
u |
117 |
+ |
43 |
“ |
34 |
|
21 |
V |
86 |
v |
118 |
% |
37 |
| |
124 |
|
22 |
W |
87 |
w |
119 |
* |
42 |
* |
42 |
|
23 |
X |
88 |
x |
120 |
= |
61 |
( |
40 |
|
24 |
Y |
89 |
y |
121 |
^ |
94 |
) |
41 |
|
25 |
Z |
90 |
z |
122 |
pl |
? |
63 |
|
|
26 |
Пробел (space) |
32 |
Пробел (space) |
32 |
Пробел (space) |
32 |
{ |
123 |
|
27 |
ll |
as |
ll |
} |
125 |
|||
|
28 |
ml |
ml |
al |
‘ |
39 |
|||
|
29 |
ps |
ps |
ps |
al |
||||
Примечания
1 Обозначения:
al - знак фиксации в подрежиме прописных букв (latch to Alpha)
as - знак регистра в подрежиме прописных букв (shift to Alpha)
ml - знак фиксации в подрежиме смешанных знаков (latch to Mixed)
pl - знак фиксации в подрежиме знаков пунктуации (latch to Punctuation).
2 В графах «Знак» представлена интерпретация по умолчанию идентификатора глобальной метки GLI 0 и интерпретация расширенного канала ECI 000002 для значений байтов, представленных в соседних графах «КОИ-7». Каждая величина, указанная в таблице, представляет собой половину кодового слова, т.е. значения от 0 до 29 (4.4.2.2).
3 В графах «Знак» в скобках указаны международные обозначения знаков.
4.4.2.2 Правила уплотнения для кодирования в режиме текстового уплотнения
В режиме текстового уплотнения пары знаков данных должны быть представлены одним кодовым словом. Значения знаков данных находятся в диапазоне от 0 до 29 (т.е. 30 базовых значений) и указаны в таблице 5. В каждой паре из 30 базовых значений первое или находящееся слева значение пары должно обозначать значение h более высокого порядка, следующее значение пары - значение более низкого порядка l.
Закодированное кодовое слово в PDF417 определяется по формуле
d = h × 30 + l,
где d - установлено в 3.2.
Эта формула также распространяется на 30 базовых значений для функций фиксации в подрежиме (sub-mode latch) и регистра в подрежиме (sub-mode shift) в рамках режима текстового уплотнения. Для переключения между подрежимами следует использовать соответствующие значения знаков фиксации в подрежиме (sub-mode latch) и регистра в подрежиме (sub-mode shift). Если в результате кодирования последовательности знаков не получено четное число 30 базовых значений, следует использовать специальную методику, приведенную в 4.4.2.4.
Приведенный пример кодирования (таблица 6) представляет, каким образом достигается уплотнение в режиме текстового уплотнения.
Таблица 6 - Пример кодирования в режиме текстового уплотнения
|
h |
1 |
h × 30 + l |
Значение кодового слова |
|
|
P D |
15 |
3 |
15 × 30 + 3 |
453 |
|
F ml |
5 |
28 |
5 × 30 + 28 |
178 |
|
4 l |
4 |
1 |
4 × 30 + 1 |
121 |
|
7 сзп (ps) |
7 |
29 |
7 × 30 + 29 |
239 |
Примечания
1 ml - знак фиксации в подрежиме смешанных знаков используется для переключения с целью кодирования цифровых знаков.
2 Знак ps используется в этом примере как значение-заполнитель, могут использоваться и другие значения знаков регистра в подрежиме и фиксации в подрежиме (4.4.2.4).
Подлежащие кодированию данные: PDF417.
Данные PDF417 представлены кодовыми словами 453, 178, 121, 239.
4.4.2.3 Переключение подрежимов режима текстового уплотнения (функции фиксации в подрежиме и регистра в подрежим)
Переключение из одного подрежима в другой в пределах режима текстового уплотнения должно выполняться с помощью значений знаков фиксации в подрежиме и регистра в подрежиме, заданных для подрежима и действовавших до переключения.
Знак регистра в подрежиме должен использоваться для переключения из одного подрежима режима текстового уплотнения в другой только для одного знака данных. Последующие кодовые слова возвращаются в подрежим, который использовался непосредственно до знака регистра в подрежиме (кроме случая, когда знак ps используется в качестве знака-заполнителя, в соответствии с 4.4.2.4). Функции знака регистра в подрежиме:
ps - переключение регистра в подрежим знаков пунктуации (shift to punctuation sub-mode),
as - переключение регистра в подрежим прописных букв (shift to uppercase alphabetic sub-mode).
Знак фиксации в подрежиме должен использоваться для переключения из одного подрежима режима текстового уплотнения в другой, который будет действовать до тех пор, пока не будет явно задействован другой знак регистра в подрежиме или знак фиксации в подрежиме. Функции знака фиксации в подрежиме:
al - фиксация в подрежиме прописных букв (latch to uppercase alphabetic sub-mode),
ll - фиксация в подрежиме строчных букв (latch to lowercase alphabetic sub-mode),
ml - фиксация в подрежиме смешанных знаков (цифровые или другие знаки пунктуации) (latch to mixed sub-mode),
pl - фиксация в подрежиме знаков пунктуации (latch to punctuation sub-mode).
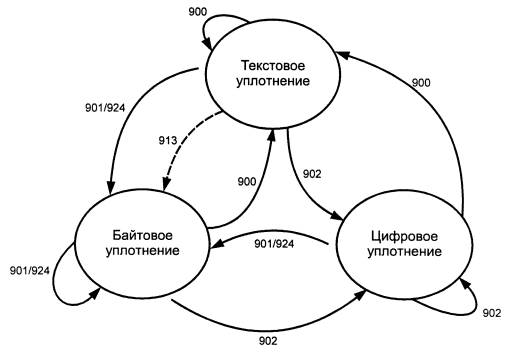
Внутри каждого подрежима режима текстового уплотнения допускается ограниченный набор функций фиксации в подрежиме и переключения регистра в подрежим (таблица 5). В таблице 7 представлены переключения подрежимов режима текстового уплотнения; на рисунке 6 приведена схема данного процесса.
Примечание - После знака фиксации в подрежиме может следовать другой знак фиксации в подрежиме или знак регистра в подрежиме; но после знака регистра в подрежиме не может следовать ни знак фиксации в подрежиме, ни знак регистра в подрежиме.
Таблица 7 - Переключения подрежимов в режиме текстового уплотнения
|
Знаки для переключения в требуемый подрежим |
||||
|
прописных букв |
строчных букв |
смешанных знаков |
знаков пунктуации |
|
|
Прописные буквы |
|
ll |
ml |
ps |
|
Строчные буквы |
as |
|
ml |
ps |
|
Смешанные знаки |
al |
ll |
|
ps pl |
|
Знаки пунктуации |
al |
|
|
|
Обозначения:
![]() - фиксация в
подрежиме;
- фиксация в
подрежиме;
![]() - переключение
регистра в подрежим;
- переключение
регистра в подрежим;
ll - знак фиксации в подрежиме строчных букв;
ps - знак регистра в подрежиме знаков пунктуации;
ml - знак фиксации в подрежиме смешанных знаков;
as - знак регистра в подрежиме прописных букв;
al - знак фиксации в подрежиме прописных букв;
pl - знак фиксации в подрежиме знаков пунктуации
Рисунок 6 - Переключения подрежимов в режиме текстового уплотнения
4.4.2.4 Методика применения знака-заполнителя в режиме текстового уплотнения
Если последовательность знаков из 30 базовых значений в режиме текстового уплотнения не является четным числом, то к окончанию последовательности знаков добавляют знак-заполнитель (пример в таблице 6). Поскольку в режиме текстового уплотнения нет специальных нулевых функций, знаки фиксации в подрежиме и регистра в подрежиме должны использоваться в соответствии с приведенной ниже методикой:
a) если последовательность знаков представляет собой окончание данных или за последовательностью знаков в режиме текстового уплотнения следует фиксация в другом режиме уплотнения, знаком-заполнителем может быть любой знак регистра в подрежиме или фиксации в подрежиме;
b) если за последовательностью знаков в режиме текстового уплотнения следует функция переключения регистра в режим байтового уплотнения (кодовое слово 913) для кодирования знака в режиме байтового уплотнения, можно применять два способа в зависимости от подрежима режима текстового уплотнения, использованного до переключения регистра в режим байтового уплотнения;
1) если подрежим режима текстового уплотнения не является подрежимом знаков пунктуации, то должен использоваться знак со значением 29 (ps) из 30 базовых значений при условии, что кодирование вернется к тому же подрежиму режима текстового уплотнения. Декодер должен игнорировать знак ps, который непосредственно предшествует кодовому слову 913,
2) если подрежимом режима текстового уплотнения является подрежим знаков пунктуации, используют знак со значением 29 (al) из 30 базовых значений. Декодер не должен игнорировать знак (al), и таким образом осуществится возврат в подрежим прописных букв.
4.4.2.5 Переключение из режима текстового уплотнения
Режим текстового уплотнения может завершиться с окончанием символа или любым из нижеперечисленных кодовых слов:
900 (фиксация в режиме текстового уплотнения);
901 (фиксация в режиме байтового уплотнения);
902 (фиксация в режиме цифрового уплотнения);
924 (фиксация в режиме байтового уплотнения);
928 (начало управляющего блока Макро);
923 (начало необязательного поля Макро PDF417);
922 (ограничитель Макро PDF417).
Последние три кодовых слова могут встречаться только внутри управляющего блока Макро PDF417 символа Макро PDF417 (4.13.1). На режим текстового уплотнения также влияет присутствие зарезервированного кодового слова (4.4.6).
Если декодер находится в режиме текстового уплотнения и встречается кодовое слово 913 (регистр в режиме байтового уплотнения), он декодирует кодовое слово, которое следует за кодовым словом 913, как отдельный двоичный байт, и затем возвращается к режиму текстового уплотнения. Подрежим, в который возвращается декодер, является самым последним фиксированным подрежимом, который действовал до кодового слова 913; знак регистра в подрежиме ps, непосредственно предшествующий кодовому слову 913, игнорируют.
Если декодер находится в режиме текстового уплотнения и встречает кодовое слово 900 (фиксация в режиме текстового уплотнения), декодер вернется в подрежим прописных букв.
4.4.3 Режим байтового уплотнения
Режим байтового уплотнения позволяет кодировать последовательность 8-битного набора байтов в последовательность кодовых слов преобразованием базы 256 в базу 900, при этом достигается коэффициент уплотнения, равный шести байтам на пять кодовых слов (1,2:1).
Набор знаков и их значения (от 0 до 255) приведены в приложении В. Они должны рассматриваться как заданная по умолчанию интерпретация графических и управляющих знаков. При вызове интерпретаций расширенного канала (ECI) (4.5) эта интерпретация может быть задана как ECI 000000 или ECI 000002 (4.5.2).
4.4.3.1 Переход в режим байтового уплотнения
Для режимов текстового или цифрового уплотнения при переходе в режим байтового уплотнения необходимо использовать одно из следующих кодовых слов:
- 924 (фиксация в режиме байтового уплотнения) - при общем числе знаков в режиме байтового уплотнения, подлежащих кодированию, кратном 6;
- 901 (фиксация в режиме байтового уплотнения) - при общем числе знаков в режиме байтового уплотнения, подлежащих кодированию, не кратном 6;
- 913 (регистр в режиме байтового уплотнения), которое может использоваться вместо кодового слова 901, когда в режиме байтового уплотнения подлежит кодированию одиночный знак.
4.4.3.2 Правила уплотнения для кодирования одиночного знака в режиме байтового уплотнения (с использованием кодового слова регистра в режиме байтового уплотнения 913)
Для кодирования одиночного знака в режиме байтового уплотнения значение кодового слова должно соответствовать десятичному значению (от 0 до 255) знака версии КОИ-8 (в соответствии с приложением В).
4.4.3.3 Правила уплотнения для кодирования протяженных цепочек знаков в режиме байтового уплотнения (с использованием кодовых слов фиксации в режиме байтового уплотнения 924 или 901)
Для кодирования знака данных режима байтового уплотнения используют следующую процедуру:
устанавливают общее число знаков режима байтового уплотнения;
при наличии числа, кратного 6, используют кодовое слово 924 (фиксация в режиме байтового уплотнения), в противном случае используют кодовое слово 901 (фиксация в режиме байтового уплотнения);
количество знаков в режиме байтового уплотнения разбивают на последовательности из 6 знаков слева направо (от позиций старших разрядов к младшим). Если количество знаков менее 6, следует перейти к шагу 7;
десятичные значения шести байтов данных, подлежащих кодированию в режиме байтового уплотнения, обозначают как ряд от b5 до b0 (где b5 является первым байтом данных);
преобразуют базу 256 в базу 900 для получения последовательности из 5 кодовых слов (в приложении С определен алгоритм и приведен пример);
при необходимости повторяют операцию на этапе 3;
для оставшихся знаков режима байтового уплотнения при использовании кодового слова фиксации в режиме байтового уплотнения 901 (т.е. когда количество знаков режима байтового уплотнения в последней группе менее 6) значением (значениями) кодового слова (слов) должно быть десятичное значение (десятичные значения) (от 0 до 255) знака (знаков) (в соответствии с примером кодирования, приведенным в приложении В) от позиций старших разрядов к младшим.
Примечание - Режим байтового уплотнения, следующий за кодовым словом 901 (фиксация в режиме байтового уплотнения), предполагает, что общее число байтов, подлежащих кодированию, не является кратным 6. Если число байтов, подлежащих кодированию в режиме байтового уплотнения, кратно 6, для соответствия настоящим правилам кодирования следует закодировать, разместить в любой точке символа кодовое слово фиксации в режиме байтового уплотнения 901 или 924. Например, кодовое слово 924, представленное в качестве первого или второго кодового слова, будет идентифицировать следующую за ним последовательность кодовых слов режима байтового уплотнения как кодируемое число байтов, кратное 6. В качестве альтернативы кодовое слово 901 может быть вставлено в любую позицию в пределах последовательности кодовых слов режима байтового уплотнения, что разделит эту последовательность на две части, из которых ни одна не кодирует число байтов, кратное 6.
Если в режимах текстового или цифрового уплотнения требуется дополнительное кодирование, следует использовать соответствующие знаки фиксации в режиме (4.4.1.1).
4.4.3.4 Переход из режима байтового уплотнения
Режим байтового уплотнения может быть завершен с окончанием символа или любым из указанных кодовых слов:
900 (фиксация в режиме текстового уплотнения);
901 (фиксация в режиме байтового уплотнения);
902 (фиксация в режиме цифрового уплотнения);
924 (фиксация в режиме байтового уплотнения);
928 (начало управляющего блока Макро PDF417);
923 (начало необязательного поля Макро PDF417);
922 (ограничитель Макро PDF417).
Три последних кодовых слова могут встречаться только внутри управляющего блока Макро PDF417 символа Макро PDF417 (в соответствии с 4.13.1). На режим байтового уплотнения также влияет присутствие зарезервированного кодового слова (в соответствии с 4.4.6).
Повторный вызов режима байтового уплотнения (посредством использования кодового слова 901 или 924 во время действия режима байтового уплотнения) служит для завершения предыдущего режима байтового уплотнения группирования в 6 знаках режима байтового уплотнения, как указано в 4.4.3.3, и затем для начала нового группирования. Эта процедура может быть необходима при кодировании номера назначения интерпретации расширенного канала (ECI assignment number) (в соответствии с 4.5.3.2).
В ходе процесса декодирования в режиме байтового уплотнения обработка последней группы кодовых слов различна в зависимости от того, каким кодовым словом (901 или 924) был вызван режим байтового уплотнения.
Если режим байтового уплотнения вызван кодовым словом 924, то общее число кодовых слов в пределах режима уплотнения должно быть кратным 5. В противном случае символ является дефектным. Все группы из 5 кодовых слов декодируют в виде групп из 6 байтов.
Если режим байтового уплотнения вызван кодовым словом 901, то последнюю группу кодовых слов четко интерпретируют как один байт на кодовое слово, без уплотнения. Следовательно, если последняя группа состоит из пяти кодовых слов, группу интерпретируют как 5 байтов, а не 6.
4.4.4 Режим цифрового уплотнения
Режим цифрового уплотнения является методом уплотнения данных с базы 10 в базу 900 и должен использоваться для кодирования протяженных цепочек последовательных цифровых разрядов. Режим цифрового уплотнения позволяет кодировать до 2,93 цифровых разрядов на кодовое слово.
4.4.4.1 Переключение в режим цифрового уплотнения
Вызов режима цифрового уплотнения может быть осуществлен из режимов байтового или текстового уплотнения с использованием кодового слова фиксации в режиме цифрового уплотнения 902.
4.4.4.2 Правила уплотнения для кодирования протяженных цепочек последовательных цифровых разрядов
Для уплотнения цифровых данных используют следующую процедуру.
Следует разделить цепочку цифр на группы из 44 цифр, за исключением последней группы, которая может содержать меньшее количество цифр.
В каждой группе к позиции старшего разряда должна быть добавлена цифра 1 для исключения потери начальных нулей.
ПРИМЕР: Исходные данные: 00246812345678
После выполнения этапа 2: 1 00246812345678
Примечание - Начальная цифра 1 исключается в алгоритме декодирования.
Следует провести преобразование базы 10 в базу 900. В приложении D установлен алгоритм преобразования и приведен пояснительный пример.
При необходимости повторяют операцию на этапе 2.
Для определения точного числа кодовых слов в режиме цифрового уплотнения могут использоваться следующие правила:
группы из 44 цифровых разрядов уплотнены в 15 кодовых словах;
для групп более коротких цифровых последовательностей число кодовых слов можно вычислить следующим образом:
кодовые слова = INT (количество цифровых разрядов/3) + 1
Для последовательности из 28 разрядов
INT (28/3) + 1
= 9 + 1
= 10 кодовых слов
4.4.4.3 Переход из режима цифрового уплотнения
Режим цифрового уплотнения может быть завершен с окончанием символа или с помощью любого из указанных кодовых слов:
900 (фиксация в режиме текстового уплотнения);
901 (фиксация в режиме байтового уплотнения);
902 (фиксация в режиме цифрового уплотнения);
924 (фиксация в режиме байтового уплотнения);
928 (начало управляющего блока Макро PDF417);
923 (начало необязательного поля Макро PDF417);
922 (ограничитель Макро PDF417).
Последние три кодовых слова могут встречаться только внутри управляющего блока Макро PDF417 символа Макро PDF417 (4.13.1). На режим цифрового уплотнения также влияет присутствие зарезервированного кодового слова (4.4.6).
Повторный вызов режима цифрового уплотнения (путем использования кодового слова 902 не выходя из режима цифрового уплотнения) служит для завершения группирования текущего режима цифрового уплотнения, как указано в 4.4.4.2, и для начала нового группирования. Эта процедура может быть необходима при кодировании номера назначения интерпретации расширенного канала (в соответствии с 4.5.3.4).
В ходе процесса декодирования для режима цифрового уплотнения результат преобразования базы 900 в базу 10 должен привести к числу, в котором разрядом старшего порядка является 1. Если преобразование базы 900 в базу 10 не имеет результатом число, начинающееся с 1, символ должен рассматриваться как дефектный. Начальная 1 исключается при получении исходного числа.
4.4.5 Рекомендации по выбору подходящего режима уплотнения
Все базовые разработки при печати и сканировании символов PDF417 должны предусматривать три режима: текстовое уплотнение, байтовое уплотнение, цифровое уплотнение. Набор знаков по умолчанию для режима текстового уплотнения должен соответствовать установленному в приложении В. Режим текстового уплотнения обычно эффективнее режима байтового уплотнения для кодирования текстовых файлов стандартной версии КОИ-7 в связи с большим уплотнением знаков КОИ-7 с десятичными значениями 9, 10, 13 и от 32 до 126.
Режим цифрового уплотнения должен использоваться для протяженных цепочек цифр.
Рекомендации по переключению между режимами для получения наименьшего числа кодовых слов приведены в виде алгоритма в приложении Р.
4.4.6 Обработка зарезервированных кодовых слов PDF417
4.4.6.1 Краткий обзор
Символы PDF417, предназначенные для использования в открытых системах, не должны использовать кодовые слова, которые обозначены как зарезервированные (4.4.1) в настоящем стандарте. Однако декодирующее оборудование должно поддерживать передачу зарезервированных кодовых слов, используя управляющие последовательности в соответствии с 4.17.4. Декодирующее оборудование также может поддерживать опцию обработки таких символов как дефектных, что может произойти при работе в режиме базового канала.
Системы приема должны отбрасывать данные, содержащие любые управляющие последовательности, использующие зарезервированные кодовые слова до тех пор, пока в систему не внесут новое определение для ранее зарезервированного кодового слова.
4.4.6.2 Создание будущего использования зарезервированных кодовых слов
Любые новые кодовые слова, подлежащие определению в будущих редакциях настоящего стандарта, должны иметь свои правила кодирования, направленные на обеспечение обратной совместимости с ранее установленным оборудованием. В частности:
- если новое сигнальное кодовое слово (отличное от кодового слова нового режима уплотнения) закодировано, непосредственно за ним должна следовать соответствующая функция фиксации в режиме уплотнения, чтобы последующие кодовые слова интерпретировались и передавались в качестве набора байтов, а не в качестве серий управляющих неинтерпретируемых кодовых слов. При использовании данного подхода будут достигнуты желаемые результаты при согласовании декодирующего оборудования, соответствующего исходному PDF417 и настоящему стандарту, вне зависимости от использования данным оборудованием исходного или нового протокола передачи;
- в системе приема декодер интерпретаций расширенного канала будет обрабатывать управляющие интерпретации расширенного канала (т.е. управляющие блоки Макро PDF417) и управляющие неинтерпретируемые кодовые слова) до интерпретируемых интерпретаций расширенного канала (таких, как схемы шифрования и наборы знаков). Поэтому схема декодирования должна учесть следующий порядок операций:
1) если присутствуют интерпретации расширенного канала - ECI управляющего блока Макро PDF417 (Macro PDF417 Control Block), то они будут использоваться для компоновки полного набора байтов в соответствующем порядке;
2) кодовые слова управления данными будут преобразованы декодером ECI в соответствии с правилами нового режима уплотнения или сигнальной ECI. Полученные в результате байты данных будут вставлены в соответствующие места внутри потока байтов;
3) к полученному в результате потоку байтов будет применяться набор знаков или другие интерпретируемые ECI.
4.5 Интерпретация расширенного канала
Протокол интерпретации расширенного канала (далее - протокол ECI) позволяет выходному потоку данных иметь интерпретации, отличные от интерпретаций набора знаков по умолчанию. Протокол ECI полностью определяется в ряде символик, включая PDF417.
Примечание - Первоначально для PDF417 была установлена особая схема символики, именуемая идентификаторами глобальной метки (Global Label Identifiers) (далее GLI). Процессы кодирования и декодирования интерпретации расширенного канала (далее ECI) идентичны ранее опубликованным спецификациям к GLI PDF417 ([2] и [3]). Однако протокол передачи для декодированных сообщений в соответствии с ранее опубликованными спецификациями PDF417 ([2] и [3]) в части GLI отличается от протокола передачи для ECI. Также имеются отличия по отношению к использованию ECI с Макро PDF417. Настоящий стандарт позволяет использовать ранние и современные протоколы таким образом, чтобы устаревшее и новое оборудование были совместимы.
В PDF417 поддерживаются пять основных типов интерпретаций:
a) наборы знаков (или кодовые страницы);
b) интерпретации общего назначения, например шифрование данных и уплотнение данных (в отличие от режимов уплотнения символики);
c) задаваемые пользователем интерпретации для замкнутых систем;
d) передача управляющей информации для Макро PDF417 (Macro PDF417);
e) передача неинтерпретируемых кодовых слов PDF417.
Передача протокола ECI представлена в полном объеме в [1]. Протокол обеспечивает согласованный метод точного определения отдельных интерпретаций или значений байтов перед печатью и после декодирования.
ECI идентифицируется 6-разрядным номером, который закодирован в символе PDF417 с помощью одного из трех специальных кодовых слов, за которым следует одно или два кодовых слова (4.5.1). Особая ECI может быть вызвана в любой точке закодированного сообщения в соответствии с правилами режимов уплотнения (в соответствии с 4.5.3).
Использование протокола ECI возможно только с декодерами, имеющими возможность передачи идентификатора символики (4.17.5). Декодеры, которые не имеют возможности передачи идентификатора символики, не могут точно передать управляющие последовательности из любого символа, в котором содержится интерпретация расширенного канала.
4.5.1 Кодирование номера назначения интерпретации расширенного канала
ECI можно вызвать в любом месте потока данных при соблюдении условий, установленных в 4.5.3. После совершения вызова ECI возможно переключение между любыми режимами уплотнения. Используемый режим уплотнения строго определяют закодированные 8-битные значения данных, не зависящие от действующей ECI. Например, кодирование последовательности со значениями от 48 до 57 (десятичные значения) будет иметь наибольшую эффективность в режиме цифрового уплотнения, даже если последовательность не будет интерпретироваться как цифры.
Номер назначения интерпретации расширенного канала (далее - номер назначения ECI) закодирован в одной из трех последовательностей кодовых слов ECI, которые начинаются с кодовых слов 927, 926 или 925. Для кодирования номера назначения ECI используется одно или два дополнительных кодовых слова. В таблице 8 представлены правила кодирования.
Таблица 8 - Кодирование номеров назначения ECI
|
Номер назначения ECI |
Последовательность кодовых слов |
Кодовые слова |
Область значений |
|
От 000000 до 000899 |
С0 C1 |
927 Номер ECI |
C1 = (0 to 899) |
|
От 000900 до 810899 |
С0 C1 C2 |
926 Номер ECI div 900 - 1 Номер ECI mod 900 |
С1 = (0 to 899) C2 = (0 to 899) |
|
От 810900 до 811799 |
С0 C1 |
925 Номер ECI - 810900 |
C1 = (0 to 899) |
В PDF417 доступно 811800 возможных номеров назначения ECI.
Примечание - Метод кодирования идентичен схеме GLI, поддерживаемой в фирменных исходных спецификациях PDF417 и включенной в [2] и [3].
Пример процесса кодирования:
ECI = 013579
Кодовые слова: [926] [(13579 div 900) - 1] [13579 mod 900]
= [926] [15 - 1] [79]
= [926] [14] [79]
4.5.2 Заранее назначенные интерпретации расширенного канала
Для обеспечения обратной совместимости с действующими спецификациями символик, включая PDF417, заранее назначены следующие интерпретации расширенного канала:
- ECI 000000 (приравниваемая к исходному GLI 0) - схема кодирования по умолчанию кодирующего устройства, соответствующая исходным стандартам PDF417. Набор знаков представлен в приложении А;
- ECI 000001 (приравниваемая к исходному GLI 1) - схема кодирования GLI ряда символик, где знаки с десятичными значениями от 0 до 127 идентичны знакам ИСО/МЭК 646* (или [4]), и знаки с десятичными значениями от 128 до 255 идентичны знакам ИСО 8859-1.
* 7-битный кодированный набор знаков по ИСО 646 соответствует набору ссылочной версии КОИ-7НО по ГОСТ 27463, за исключением двух знаков: в позиции 02/04 в ИСО 646 используют знак $ (ДЕНЕЖНЫЙ ЗНАК ДОЛЛАРА) (целочисленное значение 37) и в позиции 7/14 знак ~ (ТИЛЬДА) (целочисленное значение 111).
Примечание - Для ECI 000000 (эквивалентной GLI 0) и ИРК/ЕС1 000001 (эквивалентной GLI 1) требуется логическая схема с возвратом к GLI 0 в начале каждого закодированного символа комплекта символов Макро PDF417. Этот протокол не принят для других интерпретаций расширенного канала;
- ECI 000002 соответствует кодовой таблице (приложение В), эквивалентной ECI 000000, без логической схемы с возвратом к GLI 0. Она является схемой кодирования по умолчанию для кодирующих устройств, полностью соответствующей настоящему стандарту;
- ECI 000003 соответствует кодовой таблице, эквивалентной ECI 000001, без логической схемы с возвратом к GLI 0.
ECI 000000 и ECI 000001 не допускается кодировать в одном и том же символе PDF417 или наборе символов Макро PDF417, за исключением интерпретаций расширенного канала, заданных пользователем. ECI 000002 и ECI 000003 обеспечивают совместимые альтернативы ECI 000000 и ECI 000001 соответственно и являются предпочтительными для использования в новых применениях.
Дополнительные интерпретации расширенного канала присваиваются в соответствии с правилами, приведенными в [5].
4.5.3 Кодирование последовательностей интерпретаций расширенного канала в рамках режимов уплотнения
Основной принцип кодирования заключается в том, что интерпретации расширенного канала используют в исходном потоке байтов данных (для обозначения разных интерпретаций) путем формирования модифицированного потока данных, который кодируется в символах PDF417 с использованием для большей эффективности режимов уплотнения символики. Кодирование ECI и специальное уплотнение символики формируют два независимых логических слоя в этом процессе.
Несмотря на то, что назначения ECI и режимы уплотнения, как правило, могут перемежаться, некоторые их комбинации могут формировать нелогическую или неоднозначную ситуацию. В 4.5.3.1 - 4.5.3.5 определено, каким образом ECI могут быть встроены без появления неоднозначности путем установления надлежащего расположения управляющих последовательностей ECI.
4.5.3.1 Интерпретации расширенного канала и режим текстового уплотнения
Управляющая последовательность ECI может быть размещена в любом месте в рамках режима текстового уплотнения. Подрежим, вызванный непосредственно перед управляющей последовательностью ECI, сохраняется для кодирования сразу после этой последовательности. Поэтому функции фиксации в подрежиме и регистра в подрежиме сохраняются параллельно управляющей последовательности ECI и функция регистра в подрежиме непосредственно перед управляющей последовательностью кода ECI не игнорируется.
4.5.3.2 Интерпретации расширенного канала и режим байтового уплотнения, использующий кодовые слова 924 и 901 (фиксация в режиме байтового уплотнения)
При кодировании в режиме байтового уплотнения, использующего кодовое слово 924 (фиксация в режиме байтового уплотнения), управляющая последовательность ECI может быть размещена кодирующим устройством непосредственно после кодового слова 924 или соответственно на любой границе, отделяющей группы из пяти кодовых слов. Это необходимо для обеспечения однозначного расположения в декодированном потоке байтов для декодера, чтобы разместить управляющую последовательность.
Если декодер находится в версии 924 режима байтового уплотнения и обнаруживает управляющую последовательность ECI, которая следует за группой из пяти кодовых слов, он должен вывести шесть байтов данных, связанных с кодовыми словами перед управляющей последовательностью, вывести управляющую последовательность и затем продолжать сбор кодовых слов для декодирования в режиме байтового уплотнения. Если декодер обнаруживает управляющую последовательность ECI в иных, отличных от данных установленных местоположений, он должен рассматривать символ как дефектный.
При кодировании в режиме байтового уплотнения с использованием кодового слова 901 (фиксация в режиме байтового уплотнения) управляющая последовательность ECI может размещаться непосредственно:
- после кодового слова 901;
- после любого набора из пяти кодовых слов, кодирующих шесть байтов;
- после любых замыкающих однобайтовых кодовых слов в конце последовательности.
Примечание - Декодер не может допустить, чтобы из-за того, что управляющая последовательность ECI следует за набором из пяти кодовых слов, эти пять кодовых слов кодируют шесть байтов, а затем поток на входе длиной 6N + 5 (где N - целое число) будет иметь конечный набор из пяти кодовых слов, которые кодируют только пять байтов - один байт на одно кодовое слово. Следовательно, декодер должен в первом сканированном символе, минуя управляющую последовательность ECI, установить, где завершается режим 901 в соответствии с 4.4.3.4. На основе этой информации он может установить, каким образом была закодирована группа из пяти кодовых слов.
На рисунке 7 представлено допустимое расположение управляющих последовательностей ECI при кодировании в режиме байтового уплотнения. Если декодер встретит управляющую последовательность ECI внутри группы из пяти кодовых слов, он должен рассматривать символ как дефектный.

![]() - кодовое слово режима
байтового уплотнения;
- кодовое слово режима
байтового уплотнения;
![]() - допустимое
расположение управляющей последовательности ECI
- допустимое
расположение управляющей последовательности ECI
Рисунок 7 - Допустимые расположения управляющих последовательностей ECI при кодировании в режиме байтового уплотнения
4.5.3.3 Интерпретации расширенного канала и режим байтового уплотнения, использующий кодовое слово 913 (регистр в режиме байтового уплотнения)
При кодировании в режиме байтового уплотнения, использующего кодовое слово 913 (регистр в режиме байтового уплотнения), управляющая последовательность ECI может быть размещена непосредственно:
- перед кодовым словом 913,
- за кодовым словом 913,
- за кодовым словом, следующим после кодового слова 913.
В первых двух случаях управляющая последовательность ECI выводится до закодированных байтов, в то время как в последнем случае управляющая последовательность ECI выводится после закодированного байта.
4.5.3.4 Интерпретации расширенного канала и режим цифрового уплотнения
Управляющую последовательность ECI не следует размещать внутри группы кодовых слов, подлежащих обработке преобразованием базы 10 в базу 900 (4.4.4.2). Она может быть размещена только внутри области режима цифрового уплотнения (обычно) на границе между группами из 15 кодовых слов. Это необходимо для обеспечения однозначного позиционирования в декодированном потоке байтов при размещении декодером управляющей последовательности.
Поэтому управляющую последовательность ECI размещают непосредственно:
- после кодового слова со значением 902;
- после 15-го кодового слова;
- после 30-го кодового слова;
- и т.д.
Если кодирующему устройству необходимо расположить управляющую последовательность ECI в позиции, которая не является кратной 15 кодовым словам, то оно должно рассматривать цифровой блок до ECI как завершенный объект в соответствии со вторым этапом 4.4.4.2. Кодирующее устройство должно повторно ввести режим цифрового уплотнения путем расположения в потоке другого кодового слова со значением 902, за которым следует управляющая последовательность ECI.
Если декодер обнаруживает управляющую последовательность ECI на одной из вышеуказанных пограничных точек, он должен генерировать байты данных, связанные с кодовыми словами до управляющей последовательности (при наличии таковых), генерировать управляющую последовательность и затем продолжить сбор кодовых слов для декодирования в режиме цифрового уплотнения. Если декодер обнаруживает управляющую последовательность ECI в иных позициях, отличающихся от установленных, он должен рассматривать символ как дефектный.
4.5.3.5 Комбинирование интерпретаций расширенного канала
Две или более управляющие последовательности (т.е. номера назначения ECI) могут быть расположены в любой точке, где возможно размещение надлежащим образом одной ECI, при том условии, что между ними размещены только кодовые слова, которые используют для кодирования управляющей последовательности ECI.
4.5.4 Протокол после декодирования
Протокол для передачи данных ECI должен соответствовать представленному в 4.17.2. Во время передачи интерпретаций расширенного канала идентификаторы символики (4.17.5) должны быть полностью реализованы, и соответствующий идентификатор символики должен быть передан в качестве преамбулы.
4.6 Определение последовательности кодовых слов
В процессе кодирования генерируется последовательность кодовых слов в виде
dn-1 ... d0,
где d - кодовое слово данных, включая дескриптор длины символа и все кодовые слова функций;
n - общее количество кодовых слов данных, включая дескриптор длины символа, за исключением кодовых слов коррекции ошибки.
Дескриптор длины символа, обозначаемый dn-1, должен быть первым кодовым словом данных. Его значение должно быть равно общему количеству кодовых слов данных n; при этом подсчете должен учитываться непосредственно сам дескриптор длины символа и поэтому его значение должно быть от 1 до 926.
В процессе кодирования должны быть установлены последовательности кодовых слов. По аналогии с исходными данными сначала должны следовать данные позиций старших разрядов, например текстовые и цифровые данные, которые читаются слева направо. Последовательность кодовых слов должна быть представлена таким образом, чтобы кодовые слова данных позиций старших разрядов, содержащие закодированные данные, были обозначены dn-2. Последнее кодовое слово данных должно быть обозначено d0.
Процесс, используемый для определения матрицы строк и столбцов символа (4.9.2), может потребовать дополнения замыкающими кодовыми словами-заполнителями для завершения последовательности кодовых слов данных.
4.7 Обнаружение и коррекция ошибок
Каждый символ PDF417 содержит минимум два кодовых слова коррекции ошибок. Кодовые слова коррекции ошибок позволяют как обнаруживать, так и исправлять ошибки.
4.7.1 Уровень коррекции ошибок
Уровень коррекции ошибки в символе PDF417 в момент создания символа является выборочным. В таблице 9 показано число кодовых слов коррекции ошибок для каждого уровня коррекции ошибок.
Таблица 9 - Уровни коррекции ошибок и кодовые слова коррекции ошибок
|
Общее число кодовых слов коррекции ошибок |
|
|
0 |
2 |
|
1 |
4 |
|
2 |
8 |
|
3 |
16 |
|
4 |
32 |
|
5 |
64 |
|
6 |
128 |
|
7 |
256 |
|
8 |
512 |
4.7.2 Возможности для исправления ошибок
Исправление ошибок может использоваться для устранения дефектов на этикетке и ошибочного считывания в ходе процедуры декодирования. Для любого заданного уровня коррекции ошибок в символ PDF417 должно быть включено определенное количество кодовых слов коррекции ошибок. Используемый алгоритм кодовых слов коррекции ошибок должен позволять устранить два вида ошибок:
- стирание, обусловленное недостающим или не подлежащим декодированию кодовым словом,
- ошибку подстановки, обусловленную неправильно декодированным кодовым словом.
Схема коррекции ошибок требует наличия одного кодового слова коррекции ошибок для восстановления стирания и двух кодовых слов для устранения ошибки подстановки. Таким образом, заданный уровень коррекции ошибок может исправить любое сочетание ошибок подстановки и стираний, которое удовлетворяет уравнению
l + 2 f ≤ 2s+1 - 2,
где l, f и s - соответствуют определениям, приведенным в 3.2.
Если использована большая часть возможностей по коррекции ошибок для восстановления стираний, возрастает вероятность наличия необнаруженных ошибок. Если исправлено менее четырех ошибок (за исключением s = 0), возможность коррекции ошибок уменьшается по уравнению:
l + 2 f ≤ 2s+1 - 3,
где l, f и s соответствуют определениям, приведенным в 3.2.
Символ PDF417с уровнем коррекции ошибок 3 предусматривает наличие 16 кодовых слов коррекции ошибок, из которых 14 могут использоваться для исправления ошибок и стираний. С их помощью может быть восстановлено до 13 стираний или до семи ошибок подстановки или любое сочетание l стираний и f ошибок подстановки по условиям приведенного выше практического уравнения. В таблице 10 установлены возможные сочетания.
Таблица 10 - Возможные сочетания коррекции ошибок для уровня коррекции 3
|
Восстановленные ошибки подстановки |
Восстановленные стирания |
Определяющее уравнение |
|
0 |
13 или менее |
l + 2 f ≤ 2s+1 - 3 (количество ошибок < 4) |
|
1 |
11 или менее |
|
|
2 |
9 или менее |
|
|
3 |
7 или менее |
|
|
4 |
6 или менее |
l + 2 f ≤ 2s+1 - 2 (количество ошибок ≥ 4) |
|
5 |
4 или менее |
|
|
6 |
2 или менее |
|
|
7 |
0 |
4.7.3 Определение кодовых слов коррекции ошибок
Кодовые слова коррекции ошибок определяют в два этапа:
- выбор уровня коррекции ошибок - определяет пользователь или требования, установленные применением (приложение Е);
- формирование кодовых слов коррекции ошибок - в соответствии с перечнем правил, приведенным в 4.10. Процедуры не могут быть использованы до тех пор, пока не будут определены все кодовые слова данных, включая кодовые слова-заполнители (4.9.2).
Примечание - Процедуры в соответствии с 4.3 - 4.9, 4.13 и 4.14 определяются пользователями. Прочие технические процедуры согласно 4.10, 4.11 и 4.15 выполняются оборудованием и требуют решений со стороны пользователя.
4.8 Размеры
Символы PDF417 должны соответствовать размерам, указанным в 4.8.1 - 4.8.3.
4.8.1 Минимальная ширина модуля (X)
Минимальная ширина модуля подлежит определению в нормативных документах, устанавливающих требования по применению. Она учитывает наличие оборудования для производства и считывания символов и соответствует основным требованиям, установленным применением.
Размер X должен оставаться неизменным в пределах всего символа.
Примечание - Действующие стандарты оценки качества символа штрихового кода (например, ИСО/МЭК 15416) не требуют измерения абсолютных размеров для оценки качества символа. Поэтому несоответствие любому минимальному размеру не является поводом для оценки символа как не соответствующего настоящему стандарту.
4.8.2 Высота строки (Y)
Для символов с рекомендуемым наименьшим уровнем коррекции ошибок Y ≥ 3X.
Для символов с уровнем коррекции ошибок меньшим, чем рекомендуемый наименьший уровень, Y ≥ 4Х.
Рекомендуемый уровень коррекции ошибок приведен в приложении Е.
4.8.3 Свободные зоны
Наименьшая ширина горизонтальной свободной зоны (слева и справа от символа PDF417) - 2X.
Наименьший размер вертикальной свободной зоны (над и под символом PDF417) - 2Х.
4.9 Определение формата символа
Матрицу символа PDF417, общий размер и форму символа определяют следующие факторы:
ширина модуля и коэффициент сжатия;
число строк и столбцов в матрице символа.
При создании символа PDF417 эти параметры выбирают сочетанием установок пользователя, ограничений, определяемых применением, и установок по умолчанию. Процесс выбора может повторяться до получения пользователем требуемого формата.
4.9.1 Определение коэффициента сжатия модуля
Коэффициент сжатия печатаемого модуля (aspect ratio of the module) определяют два размера:
X - требуемая ширина самого узкого штриха и самого узкого пробела;
Y - требуемая высота каждой строки.
Эти размеры определяются пользователем или нормативными документами, регламентирующими применение штрихового кода. Основным фактором, определяющим эти параметры, является разрешение систем печати и считывания, используемых в рамках конкретного применения (4.14).
4.9.2 Определение матрицы строк и столбцов символа
Для определения матрицы символа, т.е. числа строк r и числа столбцов c, учитывают следующие факторы:
- объем и тип данных, подлежащих кодированию;
- основные правила символики, определяющие, например, предельное число строк и столбцов (4.2.1 и 4.2.2);
- фактическое пространство для нанесения символа;
- более длинные строки приводят к уменьшенной вспомогательной части символа (включающей знаки СТАРТ и СТОП, индикаторы строки и области свободных зон);
- длина строки (включая свободные поля) должна быть меньше длины линии сканирования, регламентируемой или подразумеваемой в рамках применения;
- тип сканера, который может определять общий коэффициент сжатия символа;
- выбранный уровень коррекции ошибок.
Во многих применениях допустимая длина символа является первичным ограничением и матрицу символа можно определить фиксированным числом столбцов. В приложении Q приведены рекомендации по определению матрицы символа.
После кодирования исходных данных с использованием выбранных режимов уплотнения известно число исходных кодовых слов данных m (до дополнения дескриптором длины символа и любыми кодовыми словами-заполнителями). После выбора числа строк и столбцов и уровня коррекции ошибок общее число кодовых слов данных n вычисляют по формуле
n = c × r - k
где c, k, n и r соответствуют определениям, приведенным в 3.2.
В матрице могут возникнуть ситуации, когда для достижения необходимого числа строк и столбцов требуется использование кодовых слов-заполнителей (условно используется кодовое слово со значением 900). Такая ситуация может произойти при
n > m + 1,
где m и n соответствуют определениям, приведенным в 3.2.
Дескриптору длины символа следует назначить значение n, определенное выше. Таким образом:
dn-1 = n = c × r - k.
Требуемое число кодовых слов-заполнителей равно (n - m) - 1.
Кодовые слова-заполнители должны иметь значение 900 и размещаться в позициях младших разрядов последовательности кодовых слов данных, т.е. справа от исходного кодового слова данных в позиции самого младшего разряда (но до управляющего блока Макро PDF417, при наличии). Пример такого преобразования приведен ниже. Независимо от включения дескриптора длины символа и каких-либо кодовых слов-заполнителей последовательность кодовых слов должна оставаться идентичной последовательности, изначально произведенной при кодировании данных.
Пусть m = 246, c = 12, r = 24 и k = 32, тогда n = (c × r) - k = (12 × 24) - 32 = 256.
Примечание - Обозначения соответствуют указанным выше.
Значение дескриптора длины символа n равно 256.
Число кодовых слов-заполнителей равно: (n - m) - 1 = 256 - 246 - 1 = 9.
В настоящем примере кодовые слова данных (до кодовых слов-заполнителей) начинаются с функции фиксации в режиме цифрового уплотнения (кодовое слово 902) и заканчиваются кодовым словом со значением 423. Все кодовые слова-заполнители являются кодовыми словами 900. Дополнение дескриптором длины символа и кодовыми словами-заполнителями представлено ниже:
|
|
dm-1 |
, ..., |
d0 |
|
|
|
|
|
Значения кодовых слов |
|
902 |
, ..., |
423 |
|
|
|
|
Дополненная последовательность кодовых слов данных |
dn-1 |
dn-2 |
, ..., |
d9 |
d8 |
, ..., |
d0 |
|
Значения кодовых слов |
256 |
902 |
, ..., |
423 |
900 |
, ..., |
900 |
4.10 Формирование кодовых слов коррекции ошибок
Кодовые слова коррекции ошибок формируют с помощью приведенной ниже процедуры и вычисляют на основе значений всех кодовых слов данных, включая дескриптор длины символа и все кодовые слова-заполнители. Последовательность кодовых слов должна быть представлена в виде
dn-1, dn-2, ..., d0,
где dn-1 - дескриптор длины символа.
Полином данных символа представляет собой
d(x) = dn-1xn-1 + dn-2xn-2 + , ..., + d1x + d0.
Ниже приведено математическое описание вычисления кодовых слов коррекции ошибок для конкретного потока данных и выбранного уровня коррекции ошибок. Все арифметические действия должны быть выполнены по модулю 929.
Кодовые слова коррекции ошибок являются дополнением коэффициентов остатка, получающегося в результате деления полинома данных символа d(x), умноженного на xk, на порождающий полином g(x). Отрицательные значения отражаются в поле Галуа GF (929) прибавлением 929 до получения значения ≥ 0.
Для вычисления коэффициентов для кодовых слов коррекции ошибок k, необходимых для уровня коррекции ошибок, используют порождающий полином:
gk(x) = (x - 3)(x - 32)(x - 33) , ..., (x - 3k) = α0 + α1x + α2x2 + , ..., αk-1xk-1 + xk,
где gk(x) - порождающий полином;
x - неизвестная переменная;
k - общее число кодовых слов коррекции ошибок;
αj - коэффициент показателей степеней x, образованный порождающим полиномом gk(x).
Пример вычисления коэффициентов приведен в приложении R.
В приложении F приведены все значения коэффициентов, необходимые для кодирования символа PDF417 для любого уровня коррекции ошибок.
Кодовые слова коррекции ошибок должны вычисляться в соответствии с приведенным ниже алгоритмом с использованием следующих обозначений:
di - кодовое слово данных dn-1, ..., d0;
Ej - кодовое слово коррекции ошибок Ek-1, ..., E0;
αj - коэффициент показателей степени числа x из порождающего полинома (пояснения приведены ниже, а значения - в приложении F);
t1, t2, t3 - временные переменные.
Алгоритм:
1. Обозначают последовательность кодовых слов данных
dn-1, dn-2, ..., d0
2. Устанавливают в исходное состояние кодовые слова коррекции ошибок E0, ..., Ek-1 для значения, равного нулю
3. Для каждого кодового слова данных (data) di = dn-1, ..., d0
t1 = (di + Ek-1) mod 929
для каждого кодового слова коррекции ошибок Ej = Ek-1, ..., E1:
t2 = (t1 × αj) mod 929
t3 = 929 - t2
Ej = (Ej-1 + t3) mod 929
t2 = (t1 × α0) mod 929
t3 = 929 - t2
E0 = t3 mod 929
4. Для каждого кодового слова коррекции ошибок Ej = Е0, ..., Ek-1 подсчитывают дополнение:
Если Ej не равно нулю
Ej = 929 - Ej
Пример вычисления кодовых слов коррекции ошибок приведен в приложении S.
Альтернативная процедура формирования кодовых слов коррекции ошибок с использованием схемы деления приведена в приложении Т.
4.11 Низкоуровневое кодирование
Низкоуровневое кодирование необходимо для преобразования значений кодовых слов в соответствующие знаки символа (последовательности штрихов и пробелов), при этом матрица символа должна быть фиксированной.
На рисунке 8 схематично представлены соответствующие позиции каждого кодового слова данных, кодового слова коррекции ошибок и индикаторов строк для символа PDF417.
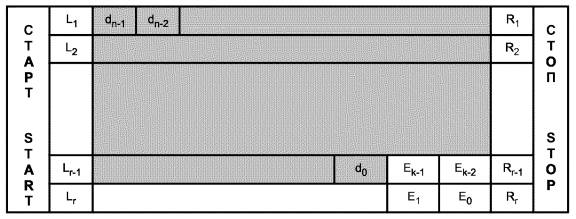
Обозначения: Lr - левый индикатор строки; Rr - правый индикатор строки;
Затененная область - область кодовых слов данных
Незатененная область под областью кодовых слов - предназначена для кодовых слов коррекции ошибок
Рисунок 8 - Схема размещения кодовых слов типового символа PDF417
4.11.1 Кластеры
В PDF417 используют систему распознавания локальной строки для определения перехода от одной строки к другой.
Наборы кодовых слов представлены в каждом из трех кластеров. Кластеры имеют номера 0, 3 и 6. В приложении А приведены соответствующие последовательности штрихов и пробелов для каждого знака символа, представляющие каждое кодовое слово и кластер.
Для кодирования индикаторов строк и других кодовых слов каждая строка должна содержать знаки символа (комбинации в виде штрихов и пробелов) только одного кластера. В первой строке используют знаки символа из кластера 0, во второй строке - из кластера 3, в третьей строке - из кластера 6, в четвертой строке - из кластера 0 и так далее. Последовательность кластеров 0, 3, 6 должна постоянно повторяться. Номер кластера К для любой строки вычисляют по формуле
K = ((номер строки - 1) mod 3) × 3,
где строки пронумерованы от 1 до r (в соответствии с 3.2).
Так как любые две смежные строки имеют разные кластеры, во время декодирования символа PDF417 декодер может использовать пути сканирования, пересекающие строки.
4.11.2 Определение матрицы символа
Матрицу строк и столбцов символа окончательно определяют в соответствии с процедурами, приведенными в 4.9.2. Они обеспечивают получение значений r и c.
4.11.3 Определение значений левого и правого индикаторов строк
Индикаторы строк в символе PDF417 - кодовые слова, которые должны кодировать несколько основных параметров: номер строки (F), число строк (r), число столбцов (c) и уровень коррекции ошибок (s). Эта информация должна быть отнесена к трем строкам и цикл должен повторяться непрерывно. Номер строки (F) должен быть закодирован в каждой строке.
4.11.3.1 Левый индикатор строк
Левый индикатор строк вычисляют по формулам:
при KF = 0; LF = 30 × ((F - 1) div 3) + (r - 1) div 3;
при KF = 3; LF = 30 × ((F - 1) div 3) + (s × 3) + (r - 1) mod 3;
при KF = 6; LF = 30 × ((F - 1) div 3) + (c - 1),
где c, F, r, s и K соответствуют определениям, приведенным в 3.2.
4.11.3.2 Правый индикатор строк
Правый индикатор строк вычисляют по формулам:
при KF = 0; RF = 30 × ((F - 1) div 3) + (c - 1);
при KF = 3; RF = 30 × ((F - 1) div 3) + (r - 1) div 3;
при KF = 6; RF = 30 × ((F - 1) div 3) + (s × 3) + (r - 1) mod 3,
где c, F, r, s, и K соответствуют определениям, приведенным в 3.2.
4.11.4 Кодирование строки
В каждой строке должны быть согласованы с номером кластера следующие знаки символа:
a) левый индикатор строки;
b) знаки символа, представляющие кодовые слова данных и (или) коррекции ошибок, в количестве, равном числу столбцов;
c) правый индикатор строки.
Знаки СТАРТ и СТОП должны быть одинаковыми для всех строк.
Символ должен кодироваться строка за строкой с включением числа c (числа столбцов) кодовых слов в каждой строке. Первая строка должна включать дескриптор длины символа в первом столбце. Последняя строка должна включать частично или полностью кодовые слова коррекции ошибок.
4.12 Компакт PDF417 (Compact PDF417)
Символы Компакт PDF417 являются возможным выбором. В случае использования Компакт PDF417 должен соответствовать требованиям приложения G.
4.13 Макро PDF417 (Macro PDF417)
Макро PDF417 (Macro PDF417) предусматривает механизм разделения данных в файлах на блоки и представления их более чем в одном символе PDF417. Данный механизм идентичен свойству структурированного соединения в других символиках.
Каждый символ Макро PDF417 (Macro PDF417) должен содержать дополнительную управляющую информацию для обеспечения надлежащего восстановления исходного файла данных независимо от последовательности, в которой отдельные символы PDF417 сканируются и декодируются.
Для кодирования данных в Макро PDF417 (Macro PDF417) можно использовать до 99999 отдельных символов PDF417.
Процедуры Макро PDF417 приведены в приложении G.
4.13.1 Режимы уплотнения и Макро PDF417
Управляющий блок Макро PDF417 имеет предопределенный метод кодирования, так что кодовое слово 928 вызывает завершение любой последовательности режима уплотнения в теле символа. Поле индекса сегмента должно быть закодировано в режиме цифрового уплотнения. Каждое определенное необязательное поле Макро PDF417 имеет особые, изначально подразумеваемые режим и подрежим уплотнения, и начало нового необязательного поля служит окончанием режима уплотнения предыдущего поля (в соответствии с H.2.3) и вызывает собственный режим по умолчанию. В частности, даже если два следующих друг за другом необязательных поля используют один и тот же режим текстового уплотнения, когда встречается кодовое слово 923, подрежим прописных букв сбрасывается.
4.13.2 Интерпретации расширенного канала и Макро PDF417
В зависимости от ограничений, приведенных в 4.5.3, ECI могут встречаться в сообщениях, закодированных в отдельном символе или в наборе символов Макро PDF417 (Macro PDF417). Любая вызванная ECI должна применяться до окончания закодированных данных или до тех пор, пока не встретится другая ECI. Таким образом, интерпретация ECI может охватить два символа или более.
Интерпретация (интерпретации) расширенного канала в теле потока кодовых слов данных не распространяется на управляющий блок Макро PDF417, но возобновляется автоматически в начале следующего символа. Данные управляющего блока интерпретируются с помощью значения ECI по умолчанию (000002) до тех пор, пока управляющие последовательности ECI не будут явно закодированы в необязательном поле в управляющем блоке. Действие любой ECI такого рода автоматически заканчивается при окончании поля, в котором она присутствует.
Примечание - При реализации в качестве идентификаторов глобальной метки в соответствии с прежними спецификациями (например, [2] и [3]) кодирование подразумевает возврат к GLI 0 (равнозначному ECI 000000) в начале каждого символа. Если подразумевается, что в следующем символе сохраняется GLI 1, тогда в начале этого следующего символа должен быть явно закодирован GLI 1. В связи с тем, что кодирующие устройства согласованы с этими ранее опубликованными стандартами, которые еще некоторое время будут в использовании, рекомендации по обеспечению совместимости с настоящими требованиями приведены в 4.17.6.
4.14 Рекомендации для пользователя
4.14.1 Визуальное представление
Символы PDF417 допускают кодирование больших объемов данных, в связи с этим печать визуальных представлений знаков данных может оказаться непрактичной. В качестве альтернативы символ может сопровождать описательный, а не дословный текст. Представление может быть отпечатано в любом месте вокруг символа, но без нарушения символа и свободных зон. Размеры знаков и шрифт не регламентированы настоящим стандартом, но могут устанавливаться в стандартах, регламентирующих требования по применению.
4.14.2 Возможность автоматического распознавания
PDF417 может использоваться в условиях автоматического распознавания с рядом других символик в соответствии с приложением U.
4.14.3 Параметры применения, устанавливаемые пользователем
Параметры символов PDF417 должны определять стандарты, регламентирующие требования по применению в соответствии с требованиями, указанными в 4.14.3.1, 4.14.3.2.
4.14.3.1 Символика и размеры
Стандарты, регламентирующие требования по применению, должны устанавливать следующие параметры данных и символики, включая размеры:
a) выбор и использование интерпретаций расширенного канала, при необходимости, для расширения кодирования данных за пределами интерпретаций по умолчанию базовых режимов,
b) объем данных в символе, который может быть фиксированным, переменным или переменным до определенного значения,
c) выбор уровня коррекции ошибок,
d) диапазон размеров X,
e) диапазон размеров Y,
f) параметры символа - диапазон допустимых коэффициентов сжатия и (или) соответствие длины или высоты символа (любой из двух) наибольшим размерам.
Примечание - Дополнительные факторы, которые следует учитывать при определении применений PDF417, приведены в приложениях Q и U.
4.14.3.2 Требования контроля
Параметры оценки символов определяют установлением класса качества в соответствии с ИСО/МЭК 15416 в стандарте, регламентирующем требования по применению.
Класс качества выражается в следующей форме:
класс/апертура/длина волны в максимуме интенсивности отраженного излучения.
Пример представления типов значений, которые необходимо отразить.
1,5/10/660,
где
- 1,5 - полный класс качества символа;
- 10 - ссылочный номер измерительной апертуры (в настоящем примере диаметр 0,25 мм);
- 660 - длина волн в максимуме интенсивности отраженного излучения в нанометрах.
Примечание - В ИСО/МЭК 15416 определены классы допустимых значений. Значения, соответствующие применению, должны быть установлены в стандарте, регламентирующем требования по применению.
4.14.4 Качество символа PDF417
Так как ИСО/МЭК 15416 не охватывает полностью испытания символов PDF417, в приложении J приведены процедуры соответствия.
4.15 Рекомендуемый алгоритм декодирования
Рекомендуемый алгоритм декодирования для PDF417 приведен в приложении K. Этот алгоритм должен быть основой для любых спецификаций оценки символов штрихового кода PDF417.
4.16 Процедура обнаружения ошибок и коррекции ошибок
В качестве составной части процедуры декодирования возможна реконструкция символа при наличии стираний и ошибок подстановки в пределах возможностей коррекции ошибок символа. Реконструкция может выполняться с помощью процедуры, описанной в приложении L.
4.17 Передаваемые данные
4.17.1 Передаваемые данные в базовой интерпретации (по умолчанию)
Все кодовые слова данных должны быть переведены в данные для пользователя и переданы в виде 8-битовых байтов независимо от того, находятся ли эти данные в режимах текстового, байтового или цифрового уплотнения. Не подлежат передаче знаки СТАРТ и СТОП, индикаторы строк, дескриптор длины символа, кодовые слова переключения режима, кодовые слова-заполнители и кодовые слова коррекции ошибок.
4.17.2 Протокол передачи для интерпретаций расширенного канала
В системах, поддерживающих ECI, в каждой передаче должен использоваться префикс идентификатора символики (4.17.5 и приложение М). Управляющие блоки Макро PDF417 (в случае, если они передаются) должны обрабатываться как управляющий набор управляющих последовательностей, который работает совместно с протоколом передачи ECI (4.17.3 и приложение Н).
Три кодовых слова (со значениями 925, 926 и 927) являются сигналом для кодирования значения ECI и декодируются как значения байтов следующим образом:
1) если последовательность ECI начинается с кодового слова 927:
a) кодовое слово 927 передается в качестве управляющего знака со значением 92, который представляет знак ОБРАТНАЯ ДРОБНАЯ ЧЕРТА (\) при кодировании по умолчанию,
b) следующее кодовое слово преобразовано в 6-разрядное значение путем размещения начальных нулей перед кодовым словом. 6-разрядное значение передается как шесть соответствующих значений байтов с десятичными значениями от 48 до 57.
Закодировано в символе - [927] [123]
Передача данных (десятичные значения байтов) - 92, 48, 48, 48, 49, 50, 51
Интерпретация в знаках КОИ-7 - \000123
2) если последовательность ECI начинается с кодового слова 926:
a) кодовое слово 926 передается как управляющий знак с десятичным значением 92,
b) следующие два кодовых слова преобразуются в 6-разрядное значение с начальными нулями при необходимости, используя следующую формулу:
([первое кодовое слово] + 1) × 900 + [второе кодовое слово])
6-разрядное значение передается как шесть соответствующих значений байтов с десятичными значениями от 48 до 57.
Закодировано в символе - [926] [136] [156]
Передача данных (десятичные значения байтов) - 92, 49, 50, 51, 52, 53, 54
Интерпретация в знаках КОИ-7 - \123456
3) если последовательность ECI начинается с кодового слова 925:
a) кодовое слово 925 передается в качестве управляющего знака со значением 92,
b) следующее кодовое слово преобразовано в 6-разрядное значение прибавлением к нему значения 810900. 6-разрядное значение передается как шесть соответствующих значений байтов с десятичными значениями от 48 до 57.
Закодировано в символе - [925] [456]
Передача данных (десятичные значения байтов) - 92, 56, 49, 49, 51, 53, 54
Интерпретация в знаках КОИ-7 - \811356
Процедура повторяется для каждого случая интерпретации расширенного канала.
Прикладное программное обеспечение, распознающее 7-байтовую управляющую последовательность по знаку со значением 92, при помощи 6 байтов (каждый из диапазона знаков со значениями от 48 до 47) должно интерпретировать все последовательные знаки до окончания закодированных данных или до тех пор, пока не встретится другой отдельный байт со значением 92 в качестве байта из интерпретации расширенного канала, определенной 6-разрядной последовательностью.
Если знак ОБРАТНАЯ ДРОБНАЯ ЧЕРТА или другой знак, представленный байтом со значением 92, необходимо использовать в качестве закодированных данных, передача должна происходить в соответствии с приведенным примером. Если байт со значением 92 появляется в качестве данных, должны быть переданы два байта этого значения; таким образом единичное появление всегда является управляющим знаком, а двоичное появление означает достоверные данные.
Закодированные данные - А\\В\С
Передача - A\\\\B\\C
4.17.3 Передача данных для Макро PDF417
Протокол передачи данных для Макро PDF417 (Macro PDF417) приведен в Н.6.
4.17.4 Передача зарезервированных кодовых слов с использованием протокола интерпретации расширенного канала
При работе под протоколом передачи ECI декодеры PDF417 должны передавать управляющую последовательность ECI из 6 байтов зарезервированных кодовых слов (интерпретируемых как \CnnnC), представляющую управляющий знак (со значением 92), за которым следует С (значение 67), три разряда, которые представляют десятичное значение зарезервированного кодового слова и за которыми следует другое С, завершающее управляющую последовательность ECI независимым от символики способом. Кодовые слова данных, следующие за зарезервированным кодовым словом, не интерпретируются декодером в соответствии с любым режимом уплотнения, но вместо этого передаются как серии управляющих последовательностей, представляющие кодовые слова с использованием той же 6-байтовой управляющей последовательности, указанной ранее. Все оставшиеся кодовые слова данных передаются этим же способом до тех пор, пока не будут достигнуты:
- окончание закодированных данных в символе;
- функция фиксации в распознанном режиме уплотнения;
- функциональное кодовое слово управляющего блока Макро PDF417 (928, 923, 922).
Кодовое слово 913 (регистр в режиме байтового уплотнения) разрешено только из режима текстового уплотнения, и, таким образом, не может быть частью потока кодовых слов в процессе отправки неинтерпретируемых управляющих кодовых слов.
Примечание - Этот протокол может правильно передавать синтаксис сообщения для любых зарезервированных кодовых слов, для которых будущие определения представляют собой обеспечение сигнальных функций или представления новых режимов уплотнения.
4.17.5 Идентификатор символики
После определения структуры данных (в виде Макро PDF417, ECI и т.д.) в качестве преамбулы к переданным декодером данным должен быть добавлен идентификатор символики. Идентификаторы символики для PDF417 приведены в приложении М.
4.17.6 Передача, использующая устаревшие протоколы
Введение системы интерпретаций расширенного канала в некоторые символики оказало воздействие на ранее существовавшие символики, включая PDF417. Основные правила кодирования и декодирования в настоящем стандарте остались теми же, что и в версиях PDF417 [2] и [3]. Передача для ECI и Макро PDF417 отличается по своему формату, но передает равнозначную информацию.
Новое оборудование и прикладное программное обеспечение, декодирующее PDF417, должно соответствовать настоящему стандарту. Однако соответствие оборудования ранее опубликованным стандартам будет действовать в течение нескольких лет. Пользователям, генерирующим символы PDF417, не придется вносить никаких изменений, так как закодированные символы имеют равнозначные значения вне зависимости от поколения используемого декодирующего оборудования. В приложении N приведены правила, которыми необходимо руководствоваться при использовании декодирующего оборудования и прикладного программного обеспечения, которые не соответствуют современным символам с ECI и Макро PDF417. Таким образом старое и новое оборудование могут сосуществовать.
ПРИЛОЖЕНИЕ А
(обязательное)
Кодирование/декодирование последовательностей штрихов и пробелов знаков символа PDF417
В таблице А.1 установлены значения каждого кодового слова и последовательности штрихов и пробелов для знаков символа в кластерах 0, 3 и 6.
Значения e, используемые на этапе декодирования, могут быть получены из последовательности штрихов и пробелов по формуле
ei = xi + xi+1.
Таблица А.1 - Последовательность штрихов и пробелов
|
Значение кодового слова |
Последовательность штрихов и пробелов для кластера |
||
|
0 ШПШПШПШП |
3 ШПШПШПШП |
6 ШПШПШПШП |
|
|
0 |
31111136 |
51111125 |
21111155 |
|
1 |
41111144 |
61111133 |
31111163 |
|
2 |
51111152 |
41111216 |
11111246 |
|
3 |
31111235 |
51111224 |
21111254 |
|
4 |
41111243 |
61111232 |
31111262 |
|
5 |
51111251 |
41111315 |
11111345 |
|
6 |
21111326 |
51111323 |
21111353 |
|
7 |
31111334 |
61111331 |
31111361 |
|
8 |
21111425 |
41111414 |
11111444 |
|
9 |
11111516 |
51111422 |
21111452 |
|
10 |
21111524 |
41111513 |
11111543 |
|
11 |
11111615 |
51111521 |
61112114 |
|
12 |
21112136 |
41111612 |
11112155 |
|
13 |
31112144 |
41112125 |
21112163 |
|
14 |
41112152 |
51112133 |
61112213 |
|
15 |
21112235 |
61112141 |
11112254 |
|
16 |
31112243 |
31112216 |
21112262 |
|
17 |
41112251 |
41112224 |
61112312 |
|
18 |
11112326 |
51112232 |
11112353 |
|
19 |
21112334 |
31112315 |
21112361 |
|
20 |
11112425 |
41112323 |
61112411 |
|
21 |
11113136 |
51112331 |
11112452 |
|
22 |
21113144 |
31112414 |
51113114 |
|
23 |
31113152 |
41112422 |
61113122 |
|
24 |
11113235 |
31112513 |
11113163 |
|
25 |
21113243 |
41112521 |
51113213 |
|
26 |
31113251 |
31112612 |
61113221 |
|
27 |
11113334 |
31113125 |
11113262 |
|
28 |
21113342 |
41113133 |
51113312 |
|
29 |
11114144 |
51113141 |
11113361 |
|
30 |
21114152 |
21113216 |
51113411 |
|
31 |
11114243 |
31113224 |
41114114 |
|
32 |
21114251 |
41113232 |
51114122 |
|
33 |
11115152 |
21113315 |
41114213 |
|
34 |
51116111 |
31113323 |
51114221 |
|
35 |
31121135 |
41113331 |
41114312 |
|
36 |
41121143 |
21113414 |
41114411 |
|
37 |
51121151 |
31113422 |
31115114 |
|
38 |
21121226 |
21113513 |
41115122 |
|
39 |
31121234 |
31113521 |
31115213 |
|
40 |
41121242 |
21113612 |
41115221 |
|
41 |
21121325 |
21114125 |
31115312 |
|
42 |
31121333 |
31114133 |
31115411 |
|
43 |
11121416 |
41114141 |
21116114 |
|
44 |
21121424 |
11114216 |
31116122 |
|
45 |
31121432 |
21114224 |
21116213 |
|
46 |
11121515 |
31114232 |
31116221 |
|
47 |
21121523 |
11114315 |
21116312 |
|
48 |
11121614 |
21114323 |
11121146 |
|
49 |
21122135 |
31114331 |
21121154 |
|
50 |
31122143 |
11114414 |
31121162 |
|
51 |
41122151 |
21114422 |
11121245 |
|
52 |
11122226 |
11114513 |
21121253 |
|
53 |
21122234 |
21114521 |
31121261 |
|
54 |
31122242 |
11115125 |
11121344 |
|
55 |
11122325 |
21115133 |
21121352 |
|
56 |
21122333 |
31115141 |
11121443 |
|
57 |
31122341 |
11115224 |
21121451 |
|
58 |
11122424 |
21115232 |
11121542 |
|
59 |
21122432 |
11115323 |
61122113 |
|
60 |
11123135 |
21115331 |
11122154 |
|
61 |
21123143 |
11115422 |
21122162 |
|
62 |
31123151 |
11116133 |
61122212 |
|
63 |
11123234 |
21116141 |
11122253 |
|
64 |
21123242 |
11116232 |
21122261 |
|
65 |
11123333 |
11116331 |
61122311 |
|
66 |
21123341 |
41121116 |
11122352 |
|
67 |
11124143 |
51121124 |
11122451 |
|
68 |
21124151 |
61121132 |
51123113 |
|
69 |
11124242 |
41121215 |
61123121 |
|
70 |
11124341 |
51121223 |
11123162 |
|
71 |
21131126 |
61121231 |
51123212 |
|
72 |
31131134 |
41121314 |
11123261 |
|
73 |
41131142 |
51121322 |
51123311 |
|
74 |
21131225 |
41121413 |
41124113 |
|
75 |
31131233 |
51121421 |
51124121 |
|
76 |
41131241 |
41121512 |
41124212 |
|
77 |
11131316 |
41121611 |
41124311 |
|
78 |
21131324 |
31122116 |
31125113 |
|
79 |
31131332 |
41122124 |
41125121 |
|
80 |
11131415 |
51122132 |
31125212 |
|
81 |
21131423 |
31122215 |
31125311 |
|
82 |
11131514 |
41122223 |
21126113 |
|
83 |
11131613 |
51122231 |
31126121 |
|
84 |
11132126 |
31122314 |
21126212 |
|
85 |
21132134 |
41122322 |
21126311 |
|
86 |
31132142 |
31122413 |
11131145 |
|
87 |
11132225 |
41122421 |
21131153 |
|
88 |
21132233 |
31122512 |
31131161 |
|
89 |
31132241 |
31122611 |
11131244 |
|
90 |
11132324 |
21123116 |
21131252 |
|
91 |
21132332 |
31123124 |
11131343 |
|
92 |
11132423 |
41123132 |
21131351 |
|
93 |
11132522 |
21123215 |
11131442 |
|
94 |
11133134 |
31123223 |
11131541 |
|
95 |
21133142 |
41123231 |
61132112 |
|
96 |
11133233 |
21123314 |
11132153 |
|
97 |
21133241 |
31123322 |
21132161 |
|
98 |
11133332 |
21123413 |
61132211 |
|
99 |
11134142 |
31123421 |
11132252 |
|
100 |
21141125 |
21123512 |
11132351 |
|
101 |
31141133 |
21123611 |
51133112 |
|
102 |
41141141 |
11124116 |
11133161 |
|
103 |
11141216 |
21124124 |
51133211 |
|
104 |
21141224 |
31124132 |
41134112 |
|
105 |
31141232 |
11124215 |
41134211 |
|
106 |
11141315 |
21124223 |
31135112 |
|
107 |
21141323 |
31124231 |
31135211 |
|
108 |
31141331 |
11124314 |
21136112 |
|
109 |
11141414 |
21124322 |
21136211 |
|
ПО |
21141422 |
11124413 |
11141144 |
|
111 |
11141513 |
21124421 |
21141152 |
|
112 |
21141521 |
11124512 |
11141243 |
|
113 |
11142125 |
11125124 |
21141251 |
|
114 |
21142133 |
21125132 |
11141342 |
|
115 |
31142141 |
11125223 |
11141441 |
|
116 |
11142224 |
21125231 |
61142111 |
|
117 |
21142232 |
11125322 |
11142152 |
|
118 |
11142323 |
11125421 |
11142251 |
|
119 |
21142331 |
11126132 |
51143111 |
|
120 |
11142422 |
11126231 |
41144111 |
|
121 |
11142521 |
41131115 |
31145111 |
|
122 |
21143141 |
51131123 |
11151143 |
|
123 |
11143331 |
61131131 |
21151151 |
|
124 |
11151116 |
41131214 |
11151242 |
|
125 |
21151124 |
51131222 |
11151341 |
|
126 |
31151132 |
41131313 |
11152151 |
|
127 |
11151215 |
51131321 |
11161142 |
|
128 |
21151223 |
41131412 |
11161241 |
|
129 |
31151231 |
41131511 |
12111146 |
|
130 |
11151314 |
31132115 |
22111154 |
|
131 |
21151322 |
41132123 |
32111162 |
|
132 |
11151413 |
51132131 |
12111245 |
|
133 |
21151421 |
31132214 |
22111253 |
|
134 |
11151512 |
41132222 |
32111261 |
|
135 |
11152124 |
31132313 |
12111344 |
|
136 |
11152223 |
41132321 |
22111352 |
|
137 |
11152322 |
31132412 |
12111443 |
|
138 |
11161115 |
31132511 |
22111451 |
|
139 |
31161131 |
21133115 |
12111542 |
|
140 |
21161222 |
31133123 |
62112113 |
|
141 |
21161321 |
41133131 |
12112154 |
|
142 |
11161511 |
21133214 |
22112162 |
|
143 |
32111135 |
31133222 |
62112212 |
|
144 |
42111143 |
21133313 |
12112253 |
|
145 |
52111151 |
31133321 |
22112261 |
|
146 |
22111226 |
21133412 |
62112311 |
|
147 |
32111234 |
21133511 |
12112352 |
|
148 |
42111242 |
11134115 |
12112451 |
|
149 |
22111325 |
21134123 |
52113113 |
|
150 |
32111333 |
31134131 |
62113121 |
|
151 |
42111341 |
11134214 |
12113162 |
|
152 |
12111416 |
21134222 |
52113212 |
|
153 |
22111424 |
11134313 |
12113261 |
|
154 |
12111515 |
21134321 |
52113311 |
|
155 |
22112135 |
11134412 |
42114113 |
|
156 |
32112143 |
11134511 |
52114121 |
|
157 |
42112151 |
11135123 |
42114212 |
|
158 |
12112226 |
21135131 |
42114311 |
|
159 |
22112234 |
11135222 |
32115113 |
|
160 |
32112242 |
11135321 |
42115121 |
|
161 |
12112325 |
11136131 |
32115212 |
|
162 |
22112333 |
41141114 |
32115311 |
|
163 |
12112424 |
51141122 |
22116113 |
|
164 |
12112523 |
41141213 |
32116121 |
|
165 |
12113135 |
51141221 |
22116212 |
|
166 |
22113143 |
41141312 |
22116311 |
|
167 |
32113151 |
41141411 |
21211145 |
|
168 |
12113234 |
31142114 |
31211153 |
|
169 |
22113242 |
41142122 |
41211161 |
|
170 |
12113333 |
31142213 |
11211236 |
|
171 |
12113432 |
41142221 |
21211244 |
|
172 |
12114143 |
31142312 |
31211252 |
|
173 |
22114151 |
31142411 |
11211335 |
|
174 |
12114242 |
21143114 |
21211343 |
|
175 |
12115151 |
31143122 |
31211351 |
|
176 |
31211126 |
21143213 |
11211434 |
|
177 |
41211134 |
31143221 |
21211442 |
|
178 |
51211142 |
21143312 |
11211533 |
|
179 |
31211225 |
21143411 |
21211541 |
|
180 |
41211233 |
11144114 |
11211632 |
|
181 |
51211241 |
21144122 |
12121145 |
|
182 |
21211316 |
11144213 |
22121153 |
|
183 |
31211324 |
21144221 |
32121161 |
|
184 |
41211332 |
11144312 |
11212145 |
|
185 |
21211415 |
11144411 |
12121244 |
|
186 |
31211423 |
11145122 |
22121252 |
|
187 |
41211431 |
11145221 |
11212244 |
|
188 |
21211514 |
41151113 |
21212252 |
|
189 |
31211522 |
51151121 |
22121351 |
|
190 |
22121126 |
41151212 |
11212343 |
|
191 |
32121134 |
41151311 |
12121442 |
|
192 |
42121142 |
31152113 |
11212442 |
|
193 |
21212126 |
41152121 |
12121541 |
|
194 |
22121225 |
31152212 |
11212541 |
|
195 |
32121233 |
31152311 |
62122112 |
|
196 |
42121241 |
21153113 |
12122153 |
|
197 |
21212225 |
31153121 |
22122161 |
|
198 |
31212233 |
21153212 |
61213112 |
|
199 |
41212241 |
21153311 |
62122211 |
|
200 |
11212316 |
11154113 |
11213153 |
|
201 |
12121415 |
21154121 |
12122252 |
|
202 |
22121423 |
11154212 |
61213211 |
|
203 |
32121431 |
11154311 |
11213252 |
|
204 |
11212415 |
41161112 |
12122351 |
|
205 |
21212423 |
41161211 |
11213351 |
|
206 |
11212514 |
31162112 |
52123112 |
|
207 |
12122126 |
31162211 |
12123161 |
|
208 |
22122134 |
21163112 |
51214112 |
|
209 |
32122142 |
21163211 |
52123211 |
|
210 |
11213126 |
42111116 |
11214161 |
|
211 |
12122225 |
52111124 |
51214211 |
|
212 |
22122233 |
62111132 |
42124112 |
|
213 |
32122241 |
42111215 |
41215112 |
|
214 |
11213225 |
52111223 |
42124211 |
|
215 |
21213233 |
62111231 |
41215211 |
|
216 |
31213241 |
42111314 |
32125112 |
|
217 |
11213324 |
52111322 |
31216112 |
|
218 |
12122423 |
42111413 |
32125211 |
|
219 |
11213423 |
52111421 |
31216211 |
|
220 |
12123134 |
42111512 |
22126112 |
|
221 |
22123142 |
42111611 |
22126211 |
|
222 |
11214134 |
32112116 |
11221136 |
|
223 |
12123233 |
42112124 |
21221144 |
|
224 |
22123241 |
52112132 |
31221152 |
|
225 |
11214233 |
32112215 |
11221235 |
|
226 |
21214241 |
42112223 |
21221243 |
|
227 |
11214332 |
52112231 |
31221251 |
|
228 |
12124142 |
32112314 |
11221334 |
|
229 |
11215142 |
42112322 |
21221342 |
|
230 |
12124241 |
32112413 |
11221433 |
|
231 |
11215241 |
42112421 |
21221441 |
|
232 |
31221125 |
32112512 |
11221532 |
|
233 |
41221133 |
32112611 |
11221631 |
|
234 |
51221141 |
22113116 |
12131144 |
|
235 |
21221216 |
32113124 |
22131152 |
|
236 |
31221224 |
42113132 |
11222144 |
|
237 |
41221232 |
22113215 |
12131243 |
|
238 |
21221315 |
32113223 |
22131251 |
|
239 |
31221323 |
42113231 |
11222243 |
|
240 |
41221331 |
22113314 |
21222251 |
|
241 |
21221414 |
32113322 |
11222342 |
|
242 |
31221422 |
22113413 |
12131441 |
|
243 |
21221513 |
32113421 |
11222441 |
|
244 |
21221612 |
22113512 |
62132111 |
|
245 |
22131125 |
22113611 |
12132152 |
|
246 |
32131133 |
12114116 |
61223111 |
|
247 |
42131141 |
22114124 |
11223152 |
|
248 |
21222125 |
32114132 |
12132251 |
|
249 |
22131224 |
12114215 |
11223251 |
|
250 |
32131232 |
22114223 |
52133111 |
|
251 |
11222216 |
32114231 |
51224111 |
|
252 |
12131315 |
12114314 |
42134111 |
|
253 |
31222232 |
22114322 |
41225111 |
|
254 |
32131331 |
12114413 |
32135111 |
|
255 |
11222315 |
22114421 |
31226111 |
|
256 |
12131414 |
12114512 |
22136111 |
|
257 |
22131422 |
12115124 |
11231135 |
|
258 |
11222414 |
22115132 |
21231143 |
|
259 |
21222422 |
12115223 |
31231151 |
|
260 |
22131521 |
22115231 |
11231234 |
|
261 |
12131612 |
12115322 |
21231242 |
|
262 |
12132125 |
12115421 |
11231333 |
|
263 |
22132133 |
12116132 |
21231341 |
|
264 |
32132141 |
12116231 |
11231432 |
|
265 |
11223125 |
51211115 |
11231531 |
|
266 |
12132224 |
61211123 |
12141143 |
|
267 |
22132232 |
11211164 |
22141151 |
|
268 |
11223224 |
51211214 |
11232143 |
|
269 |
21223232 |
61211222 |
12141242 |
|
270 |
22132331 |
11211263 |
11232242 |
|
271 |
11223323 |
51211313 |
12141341 |
|
272 |
12132422 |
61211321 |
11232341 |
|
273 |
12132521 |
11211362 |
12142151 |
|
274 |
12133133 |
51211412 |
11233151 |
|
275 |
22133141 |
51211511 |
11241134 |
|
276 |
11224133 |
42121115 |
21241142 |
|
277 |
12133232 |
52121123 |
11241233 |
|
278 |
11224232 |
62121131 |
21241241 |
|
279 |
12133331 |
41212115 |
11241332 |
|
280 |
11224331 |
42121214 |
11241431 |
|
281 |
11225141 |
61212131 |
12151142 |
|
282 |
21231116 |
41212214 |
11242142 |
|
283 |
31231124 |
51212222 |
12151241 |
|
284 |
41231132 |
52121321 |
11242241 |
|
285 |
21231215 |
41212313 |
11251133 |
|
286 |
31231223 |
42121412 |
21251141 |
|
287 |
41231231 |
41212412 |
11251232 |
|
288 |
21231314 |
42121511 |
11251331 |
|
289 |
31231322 |
41212511 |
12161141 |
|
290 |
21231413 |
32122115 |
11252141 |
|
291 |
31231421 |
42122123 |
11261132 |
|
292 |
21231512 |
52122131 |
11261231 |
|
293 |
21231611 |
31213115 |
13111145 |
|
294 |
12141116 |
32122214 |
23111153 |
|
295 |
22141124 |
42122222 |
33111161 |
|
296 |
32141132 |
31213214 |
13111244 |
|
297 |
11232116 |
41213222 |
23111252 |
|
298 |
12141215 |
42122321 |
13111343 |
|
299 |
22141223 |
31213313 |
23111351 |
|
300 |
32141231 |
32122412 |
13111442 |
|
301 |
11232215 |
31213412 |
13111541 |
|
302 |
21232223 |
32122511 |
63112112 |
|
303 |
31232231 |
31213511 |
13112153 |
|
304 |
11232314 |
22123115 |
23112161 |
|
305 |
12141413 |
32123123 |
63112211 |
|
306 |
22141421 |
42123131 |
13112252 |
|
307 |
11232413 |
21214115 |
13112351 |
|
308 |
21232421 |
22123214 |
53113112 |
|
309 |
11232512 |
32123222 |
13113161 |
|
310 |
12142124 |
21214214 |
53113211 |
|
311 |
22142132 |
31214222 |
43114112 |
|
312 |
11233124 |
32123321 |
43114211 |
|
313 |
12142223 |
21214313 |
33115112 |
|
314 |
22142231 |
22123412 |
33115211 |
|
315 |
11233223 |
21214412 |
23116112 |
|
316 |
21233231 |
22123511 |
23116211 |
|
317 |
11233322 |
21214511 |
12211136 |
|
318 |
12142421 |
12124115 |
22211144 |
|
319 |
11233421 |
22124123 |
32211152 |
|
320 |
11234132 |
32124131 |
12211235 |
|
321 |
11234231 |
11215115 |
22211243 |
|
322 |
21241115 |
12124214 |
32211251 |
|
323 |
31241123 |
22124222 |
12211334 |
|
324 |
41241131 |
11215214 |
22211342 |
|
325 |
21241214 |
21215222 |
12211433 |
|
326 |
31241222 |
22124321 |
22211441 |
|
327 |
21241313 |
11215313 |
12211532 |
|
328 |
31241321 |
12124412 |
12211631 |
|
329 |
21241412 |
11215412 |
13121144 |
|
330 |
21241511 |
12124511 |
23121152 |
|
331 |
12151115 |
12125123 |
12212144 |
|
332 |
22151123 |
22125131 |
13121243 |
|
333 |
32151131 |
11216123 |
23121251 |
|
334 |
11242115 |
12125222 |
12212243 |
|
335 |
12151214 |
11216222 |
22212251 |
|
336 |
22151222 |
12125321 |
12212342 |
|
337 |
11242214 |
11216321 |
13121441 |
|
338 |
21242222 |
12126131 |
12212441 |
|
339 |
22151321 |
51221114 |
63122111 |
|
340 |
11242313 |
61221122 |
13122152 |
|
341 |
12151412 |
11221163 |
62213111 |
|
342 |
11242412 |
51221213 |
12213152 |
|
343 |
12151511 |
61221221 |
13122251 |
|
344 |
12152123 |
11221262 |
12213251 |
|
345 |
11243123 |
51221312 |
53123111 |
|
346 |
11243222 |
11221361 |
52214111 |
|
347 |
11243321 |
51221411 |
43124111 |
|
348 |
31251122 |
42131114 |
42215111 |
|
349 |
31251221 |
52131122 |
33125111 |
|
350 |
21251411 |
41222114 |
32216111 |
|
351 |
22161122 |
42131213 |
23126111 |
|
352 |
12161213 |
52131221 |
21311135 |
|
353 |
11252213 |
41222213 |
31311143 |
|
354 |
11252312 |
51222221 |
41311151 |
|
355 |
11252411 |
41222312 |
11311226 |
|
356 |
23111126 |
42131411 |
21311234 |
|
357 |
33111134 |
41222411 |
31311242 |
|
358 |
43111142 |
32132114 |
11311325 |
|
359 |
23111225 |
42132122 |
21311333 |
|
360 |
33111233 |
31223114 |
31311341 |
|
361 |
13111316 |
32132213 |
11311424 |
|
362 |
23111324 |
42132221 |
21311432 |
|
363 |
33111332 |
31223213 |
11311523 |
|
364 |
13111415 |
41223221 |
21311531 |
|
365 |
23111423 |
31223312 |
11311622 |
|
366 |
13111514 |
32132411 |
12221135 |
|
367 |
13111613 |
31223411 |
22221143 |
|
368 |
13112126 |
22133114 |
32221151 |
|
369 |
23112134 |
32133122 |
11312135 |
|
370 |
33112142 |
21224114 |
12221234 |
|
371 |
13112225 |
22133213 |
22221242 |
|
372 |
23112233 |
32133221 |
11312234 |
|
373 |
33112241 |
21224213 |
21312242 |
|
374 |
13112324 |
31224221 |
22221341 |
|
375 |
23112332 |
21224312 |
11312333 |
|
376 |
13112423 |
22133411 |
12221432 |
|
377 |
13112522 |
21224411 |
11312432 |
|
378 |
13113134 |
12134114 |
12221531 |
|
379 |
23113142 |
22134122 |
11312531 |
|
380 |
13113233 |
11225114 |
13131143 |
|
381 |
23113241 |
12134213 |
23131151 |
|
382 |
13113332 |
22134221 |
12222143 |
|
383 |
13114142 |
11225213 |
13131242 |
|
384 |
13114241 |
21225221 |
11313143 |
|
385 |
32211125 |
11225312 |
12222242 |
|
386 |
42211133 |
12134411 |
13131341 |
|
387 |
52211141 |
11225411 |
11313242 |
|
388 |
22211216 |
12135122 |
12222341 |
|
389 |
32211224 |
11226122 |
11313341 |
|
390 |
42211232 |
12135221 |
13132151 |
|
391 |
22211315 |
11226221 |
12223151 |
|
392 |
32211323 |
51231113 |
11314151 |
|
393 |
42211331 |
61231121 |
11321126 |
|
394 |
22211414 |
11231162 |
21321134 |
|
395 |
32211422 |
51231212 |
31321142 |
|
396 |
22211513 |
11231261 |
11321225 |
|
397 |
32211521 |
51231311 |
21321233 |
|
398 |
23121125 |
42141113 |
31321241 |
|
399 |
33121133 |
52141121 |
11321324 |
|
400 |
43121141 |
41232113 |
21321332 |
|
401 |
22212125 |
51232121 |
11321423 |
|
402 |
23121224 |
41232212 |
21321431 |
|
403 |
33121232 |
42141311 |
11321522 |
|
404 |
12212216 |
41232311 |
11321621 |
|
405 |
13121315 |
32142113 |
12231134 |
|
406 |
32212232 |
42142121 |
22231142 |
|
407 |
33121331 |
31233113 |
11322134 |
|
408 |
12212315 |
32142212 |
12231233 |
|
409 |
22212323 |
31233212 |
22231241 |
|
410 |
23121422 |
32142311 |
11322233 |
|
411 |
12212414 |
31233311 |
21322241 |
|
412 |
13121513 |
22143113 |
11322332 |
|
413 |
12212513 |
32143121 |
12231431 |
|
414 |
13122125 |
21234113 |
11322431 |
|
415 |
23122133 |
31234121 |
13141142 |
|
416 |
33122141 |
21234212 |
12232142 |
|
417 |
12213125 |
22143311 |
13141241 |
|
418 |
13122224 |
21234311 |
11323142 |
|
419 |
32213141 |
12144113 |
12232241 |
|
420 |
12213224 |
22144121 |
11323241 |
|
421 |
22213232 |
11235113 |
11331125 |
|
422 |
23122331 |
12144212 |
21331133 |
|
423 |
12213323 |
11235212 |
31331141 |
|
424 |
13122422 |
12144311 |
11331224 |
|
425 |
12213422 |
11235311 |
21331232 |
|
426 |
13123133 |
12145121 |
11331323 |
|
427 |
23123141 |
11236121 |
21331331 |
|
428 |
12214133 |
51241112 |
11331422 |
|
429 |
13123232 |
11241161 |
11331521 |
|
430 |
12214232 |
51241211 |
12241133 |
|
431 |
13123331 |
42151112 |
22241141 |
|
432 |
13124141 |
41242112 |
11332133 |
|
433 |
12215141 |
42151211 |
12241232 |
|
434 |
31311116 |
41242211 |
11332232 |
|
435 |
41311124 |
32152112 |
12241331 |
|
436 |
51311132 |
31243112 |
11332331 |
|
437 |
31311215 |
32152211 |
13151141 |
|
438 |
41311223 |
31243211 |
12242141 |
|
439 |
51311231 |
22153112 |
11333141 |
|
440 |
31311314 |
21244112 |
11341124 |
|
441 |
41311322 |
22153211 |
21341132 |
|
442 |
31311413 |
21244211 |
11341223 |
|
443 |
41311421 |
12154112 |
21341231 |
|
444 |
31311512 |
11245112 |
11341322 |
|
445 |
22221116 |
12154211 |
11341421 |
|
446 |
32221124 |
11245211 |
12251132 |
|
447 |
42221132 |
51251111 |
11342132 |
|
448 |
21312116 |
42161111 |
12251231 |
|
449 |
22221215 |
41252111 |
11342231 |
|
450 |
41312132 |
32162111 |
11351123 |
|
451 |
42221231 |
31253111 |
21351131 |
|
452 |
21312215 |
22163111 |
11351222 |
|
453 |
31312223 |
21254111 |
11351321 |
|
454 |
41312231 |
43111115 |
12261131 |
|
455 |
21312314 |
53111123 |
11352131 |
|
456 |
22221413 |
63111131 |
11361122 |
|
457 |
32221421 |
43111214 |
11361221 |
|
458 |
21312413 |
53111222 |
14111144 |
|
459 |
31312421 |
43111313 |
24111152 |
|
460 |
22221611 |
53111321 |
14111243 |
|
461 |
13131116 |
43111412 |
24111251 |
|
462 |
23131124 |
43111511 |
14111342 |
|
463 |
33131132 |
33112115 |
14111441 |
|
464 |
12222116 |
43112123 |
14112152 |
|
465 |
13131215 |
53112131 |
14112251 |
|
466 |
23131223 |
33112214 |
54113111 |
|
467 |
33131231 |
43112222 |
44114111 |
|
468 |
11313116 |
33112313 |
34115111 |
|
469 |
12222215 |
43112321 |
24116111 |
|
470 |
22222223 |
33112412 |
13211135 |
|
471 |
32222231 |
33112511 |
23211143 |
|
472 |
11313215 |
23113115 |
33211151 |
|
473 |
21313223 |
33113123 |
13211234 |
|
474 |
31313231 |
43113131 |
23211242 |
|
475 |
23131421 |
23113214 |
13211333 |
|
476 |
11313314 |
33113222 |
23211341 |
|
477 |
12222413 |
23113313 |
13211432 |
|
478 |
22222421 |
33113321 |
13211531 |
|
479 |
11313413 |
23113412 |
14121143 |
|
480 |
13131611 |
23113511 |
24121151 |
|
481 |
13132124 |
13114115 |
13212143 |
|
482 |
23132132 |
23114123 |
14121242 |
|
483 |
12223124 |
33114131 |
13212242 |
|
484 |
13132223 |
13114214 |
14121341 |
|
485 |
23132231 |
23114222 |
13212341 |
|
486 |
11314124 |
13114313 |
14122151 |
|
487 |
12223223 |
23114321 |
13213151 |
|
488 |
22223231 |
13114412 |
12311126 |
|
489 |
11314223 |
13114511 |
22311134 |
|
490 |
21314231 |
13115123 |
32311142 |
|
491 |
13132421 |
23115131 |
12311225 |
|
492 |
12223421 |
13115222 |
22311233 |
|
493 |
13133132 |
13115321 |
32311241 |
|
494 |
12224132 |
13116131 |
12311324 |
|
495 |
13133231 |
52211114 |
22311332 |
|
496 |
11315132 |
62211122 |
12311423 |
|
497 |
12224231 |
12211163 |
22311431 |
|
498 |
31321115 |
52211213 |
12311522 |
|
499 |
41321123 |
62211221 |
12311621 |
|
500 |
51321131 |
12211262 |
13221134 |
|
501 |
31321214 |
52211312 |
23221142 |
|
502 |
41321222 |
12211361 |
12312134 |
|
503 |
31321313 |
52211411 |
13221233 |
|
504 |
41321321 |
43121114 |
23221241 |
|
505 |
31321412 |
53121122 |
12312233 |
|
506 |
31321511 |
42212114 |
13221332 |
|
507 |
22231115 |
43121213 |
12312332 |
|
508 |
32231123 |
53121221 |
13221431 |
|
509 |
42231131 |
42212213 |
12312431 |
|
510 |
21322115 |
52212221 |
14131142 |
|
511 |
22231214 |
42212312 |
13222142 |
|
512 |
41322131 |
43121411 |
14131241 |
|
513 |
21322214 |
42212411 |
12313142 |
|
514 |
31322222 |
33122114 |
13222241 |
|
515 |
32231321 |
43122122 |
12313241 |
|
516 |
21322313 |
32213114 |
21411125 |
|
517 |
22231412 |
33122213 |
31411133 |
|
518 |
21322412 |
43122221 |
41411141 |
|
519 |
22231511 |
32213213 |
11411216 |
|
520 |
21322511 |
42213221 |
21411224 |
|
521 |
13141115 |
32213312 |
31411232 |
|
522 |
23141123 |
33122411 |
11411315 |
|
523 |
33141131 |
32213411 |
21411323 |
|
524 |
12232115 |
23123114 |
31411331 |
|
525 |
13141214 |
33123122 |
11411414 |
|
526 |
23141222 |
22214114 |
21411422 |
|
527 |
11323115 |
23123213 |
11411513 |
|
528 |
12232214 |
33123221 |
21411521 |
|
529 |
22232222 |
22214213 |
11411612 |
|
530 |
23141321 |
32214221 |
12321125 |
|
531 |
11323214 |
22214312 |
22321133 |
|
532 |
21323222 |
23123411 |
32321141 |
|
533 |
13141412 |
22214411 |
11412125 |
|
534 |
11323313 |
13124114 |
12321224 |
|
535 |
12232412 |
23124122 |
22321232 |
|
536 |
13141511 |
12215114 |
11412224 |
|
537 |
12232511 |
13124213 |
21412232 |
|
538 |
13142123 |
23124221 |
22321331 |
|
539 |
23142131 |
12215213 |
11412323 |
|
540 |
12233123 |
22215221 |
12321422 |
|
541 |
13142222 |
12215312 |
11412422 |
|
542 |
11324123 |
13124411 |
12321521 |
|
543 |
12233222 |
12215411 |
11412521 |
|
544 |
13142321 |
13125122 |
13231133 |
|
545 |
11324222 |
12216122 |
23231141 |
|
546 |
12233321 |
13125221 |
12322133 |
|
547 |
13143131 |
12216221 |
13231232 |
|
548 |
11325131 |
61311113 |
11413133 |
|
549 |
31331114 |
11311154 |
12322232 |
|
550 |
41331122 |
21311162 |
13231331 |
|
551 |
31331213 |
61311212 |
11413232 |
|
552 |
41331221 |
11311253 |
12322331 |
|
553 |
31331312 |
21311261 |
11413331 |
|
554 |
31331411 |
61311311 |
14141141 |
|
555 |
22241114 |
11311352 |
13232141 |
|
556 |
32241122 |
11311451 |
12323141 |
|
557 |
21332114 |
52221113 |
11414141 |
|
558 |
22241213 |
62221121 |
11421116 |
|
559 |
32241221 |
12221162 |
21421124 |
|
560 |
21332213 |
51312113 |
31421132 |
|
561 |
31332221 |
61312121 |
11421215 |
|
562 |
21332312 |
11312162 |
21421223 |
|
563 |
22241411 |
12221261 |
31421231 |
|
564 |
21332411 |
51312212 |
11421314 |
|
565 |
13151114 |
52221311 |
21421322 |
|
566 |
23151122 |
11312261 |
11421413 |
|
567 |
12242114 |
51312311 |
21421421 |
|
568 |
13151213 |
43131113 |
11421512 |
|
569 |
23151221 |
53131121 |
11421611 |
|
570 |
11333114 |
42222113 |
12331124 |
|
571 |
12242213 |
43131212 |
22331132 |
|
572 |
22242221 |
41313113 |
11422124 |
|
573 |
11333213 |
51313121 |
12331223 |
|
574 |
21333221 |
43131311 |
22331231 |
|
575 |
13151411 |
41313212 |
11422223 |
|
576 |
11333312 |
42222311 |
21422231 |
|
577 |
12242411 |
41313311 |
11422322 |
|
578 |
11333411 |
33132113 |
12331421 |
|
579 |
12243122 |
43132121 |
11422421 |
|
580 |
11334122 |
32223113 |
13241132 |
|
581 |
11334221 |
33132212 |
12332132 |
|
582 |
41341121 |
31314113 |
13241231 |
|
583 |
31341311 |
32223212 |
11423132 |
|
584 |
32251121 |
33132311 |
12332231 |
|
585 |
22251212 |
31314212 |
11423231 |
|
586 |
22251311 |
32223311 |
11431115 |
|
587 |
13161113 |
31314311 |
21431123 |
|
588 |
12252113 |
23133113 |
31431131 |
|
589 |
11343113 |
33133121 |
11431214 |
|
590 |
13161311 |
22224113 |
21431222 |
|
591 |
12252311 |
23133212 |
11431313 |
|
592 |
24111125 |
21315113 |
21431321 |
|
593 |
14111216 |
22224212 |
11431412 |
|
594 |
24111224 |
23133311 |
11431511 |
|
595 |
14111315 |
21315212 |
12341123 |
|
596 |
24111323 |
22224311 |
22341131 |
|
597 |
34111331 |
21315311 |
11432123 |
|
598 |
14111414 |
13134113 |
12341222 |
|
599 |
24111422 |
23134121 |
11432222 |
|
600 |
14111513 |
12225113 |
12341321 |
|
601 |
24111521 |
13134212 |
11432321 |
|
602 |
14112125 |
11316113 |
13251131 |
|
603 |
24112133 |
12225212 |
12342131 |
|
604 |
34112141 |
13134311 |
11433131 |
|
605 |
14112224 |
11316212 |
11441114 |
|
606 |
24112232 |
12225311 |
21441122 |
|
607 |
14112323 |
11316311 |
11441213 |
|
608 |
24112331 |
13135121 |
21441221 |
|
609 |
14112422 |
12226121 |
11441312 |
|
610 |
14112521 |
61321112 |
11441411 |
|
611 |
14113133 |
11321153 |
12351122 |
|
612 |
24113141 |
21321161 |
11442122 |
|
613 |
14113232 |
61321211 |
12351221 |
|
614 |
14113331 |
11321252 |
11442221 |
|
615 |
14114141 |
11321351 |
11451113 |
|
616 |
23211116 |
52231112 |
21451121 |
|
617 |
33211124 |
12231161 |
11451212 |
|
618 |
43211132 |
51322112 |
11451311 |
|
619 |
23211215 |
52231211 |
12361121 |
|
620 |
33211223 |
11322161 |
11452121 |
|
621 |
23211314 |
51322211 |
15111143 |
|
622 |
33211322 |
43141112 |
25111151 |
|
623 |
23211413 |
42232112 |
15111242 |
|
624 |
33211421 |
43141211 |
15111341 |
|
625 |
23211512 |
41323112 |
15112151 |
|
626 |
14121116 |
42232211 |
14211134 |
|
627 |
24121124 |
41323211 |
24211142 |
|
628 |
34121132 |
33142112 |
14211233 |
|
629 |
13212116 |
32233112 |
24211241 |
|
630 |
14121215 |
33142211 |
14211332 |
|
631 |
33212132 |
31324112 |
14211431 |
|
632 |
34121231 |
32233211 |
15121142 |
|
633 |
13212215 |
31324211 |
14212142 |
|
634 |
23212223 |
23143112 |
15121241 |
|
635 |
33212231 |
22234112 |
14212241 |
|
636 |
13212314 |
23143211 |
13311125 |
|
637 |
14121413 |
21325112 |
23311133 |
|
638 |
24121421 |
22234211 |
33311141 |
|
639 |
13212413 |
21325211 |
13311224 |
|
640 |
23212421 |
13144112 |
23311232 |
|
641 |
14121611 |
12235112 |
13311323 |
|
642 |
14122124 |
13144211 |
23311331 |
|
643 |
24122132 |
11326112 |
13311422 |
|
644 |
13213124 |
12235211 |
13311521 |
|
645 |
14122223 |
11326211 |
14221133 |
|
646 |
24122231 |
61331111 |
24221141 |
|
647 |
13213223 |
11331152 |
13312133 |
|
648 |
23213231 |
11331251 |
14221232 |
|
649 |
13213322 |
52241111 |
13312232 |
|
650 |
14122421 |
51332111 |
14221331 |
|
651 |
14123132 |
43151111 |
13312331 |
|
652 |
13214132 |
42242111 |
15131141 |
|
653 |
14123231 |
41333111 |
14222141 |
|
654 |
13214231 |
33152111 |
13313141 |
|
655 |
32311115 |
32243111 |
12411116 |
|
656 |
42311123 |
31334111 |
22411124 |
|
657 |
52311131 |
23153111 |
32411132 |
|
658 |
32311214 |
22244111 |
12411215 |
|
659 |
42311222 |
21335111 |
22411223 |
|
660 |
32311313 |
13154111 |
32411231 |
|
661 |
42311321 |
12245111 |
12411314 |
|
662 |
32311412 |
11336111 |
22411322 |
|
663 |
32311511 |
11341151 |
12411413 |
|
664 |
23221115 |
44111114 |
22411421 |
|
665 |
33221123 |
54111122 |
12411512 |
|
666 |
22312115 |
44111213 |
12411611 |
|
667 |
23221214 |
54111221 |
13321124 |
|
668 |
33221222 |
44111312 |
23321132 |
|
669 |
22312214 |
44111411 |
12412124 |
|
670 |
32312222 |
34112114 |
13321223 |
|
671 |
33221321 |
44112122 |
23321231 |
|
672 |
22312313 |
34112213 |
12412223 |
|
673 |
23221412 |
44112221 |
22412231 |
|
674 |
22312412 |
34112312 |
12412322 |
|
675 |
23221511 |
34112411 |
13321421 |
|
676 |
22312511 |
24113114 |
12412421 |
|
677 |
14131115 |
34113122 |
14231132 |
|
678 |
24131123 |
24113213 |
13322132 |
|
679 |
13222115 |
34113221 |
14231231 |
|
680 |
14131214 |
24113312 |
12413132 |
|
681 |
33222131 |
24113411 |
13322231 |
|
682 |
12313115 |
14114114 |
12413231 |
|
683 |
13222214 |
24114122 |
21511115 |
|
684 |
23222222 |
14114213 |
31511123 |
|
685 |
24131321 |
24114221 |
41511131 |
|
686 |
12313214 |
14114312 |
21511214 |
|
687 |
22313222 |
14114411 |
31511222 |
|
688 |
14131412 |
14115122 |
21511313 |
|
689 |
12313313 |
14115221 |
31511321 |
|
690 |
13222412 |
53211113 |
21511412 |
|
691 |
14131511 |
63211121 |
21511511 |
|
692 |
13222511 |
13211162 |
12421115 |
|
693 |
14132123 |
53211212 |
22421123 |
|
694 |
24132131 |
13211261 |
32421131 |
|
695 |
13223123 |
53211311 |
11512115 |
|
696 |
14132222 |
44121113 |
12421214 |
|
697 |
12314123 |
54121121 |
22421222 |
|
698 |
13223222 |
43212113 |
11512214 |
|
699 |
14132321 |
44121212 |
21512222 |
|
700 |
12314222 |
43212212 |
22421321 |
|
701 |
13223321 |
44121311 |
11512313 |
|
702 |
14133131 |
43212311 |
12421412 |
|
703 |
13224131 |
34122113 |
11512412 |
|
704 |
12315131 |
44122121 |
12421511 |
|
705 |
41411114 |
33213113 |
11512511 |
|
706 |
51411122 |
34122212 |
13331123 |
|
707 |
41411213 |
33213212 |
23331131 |
|
708 |
51411221 |
34122311 |
12422123 |
|
709 |
41411312 |
33213311 |
13331222 |
|
710 |
41411411 |
24123113 |
11513123 |
|
711 |
32321114 |
34123121 |
12422222 |
|
712 |
42321122 |
23214113 |
13331321 |
|
713 |
31412114 |
24123212 |
11513222 |
|
714 |
41412122 |
23214212 |
12422321 |
|
715 |
42321221 |
24123311 |
11513321 |
|
716 |
31412213 |
23214311 |
14241131 |
|
717 |
41412221 |
14124113 |
13332131 |
|
718 |
31412312 |
24124121 |
12423131 |
|
719 |
32321411 |
13215113 |
11514131 |
|
720 |
31412411 |
14124212 |
21521114 |
|
721 |
23231114 |
13215212 |
31521122 |
|
722 |
33231122 |
14124311 |
21521213 |
|
723 |
22322114 |
13215311 |
31521221 |
|
724 |
23231213 |
14125121 |
21521312 |
|
725 |
33231221 |
13216121 |
21521411 |
|
726 |
21413114 |
62311112 |
12431114 |
|
727 |
22322213 |
12311153 |
22431122 |
|
728 |
32322221 |
22311161 |
11522114 |
|
729 |
21413213 |
62311211 |
12431213 |
|
730 |
31413221 |
12311252 |
22431221 |
|
731 |
23231411 |
12311351 |
11522213 |
|
732 |
21413312 |
53221112 |
21522221 |
|
733 |
22322411 |
13221161 |
11522312 |
|
734 |
21413411 |
52312112 |
12431411 |
|
735 |
14141114 |
53221211 |
11522411 |
|
736 |
24141122 |
12312161 |
13341122 |
|
737 |
13232114 |
52312211 |
12432122 |
|
738 |
14141213 |
44131112 |
13341221 |
|
739 |
24141221 |
43222112 |
11523122 |
|
740 |
12323114 |
44131211 |
12432221 |
|
741 |
13232213 |
42313112 |
11523221 |
|
742 |
23232221 |
43222211 |
21531113 |
|
743 |
11414114 |
42313211 |
31531121 |
|
744 |
12323213 |
34132112 |
21531212 |
|
745 |
22323221 |
33223112 |
21531311 |
|
746 |
14141411 |
34132211 |
12441113 |
|
747 |
11414213 |
32314112 |
22441121 |
|
748 |
21414221 |
33223211 |
11532113 |
|
749 |
13232411 |
32314211 |
12441212 |
|
750 |
11414312 |
24133112 |
11532212 |
|
751 |
14142122 |
23224112 |
12441311 |
|
752 |
13233122 |
24133211 |
11532311 |
|
753 |
14142221 |
22315112 |
13351121 |
|
754 |
12324122 |
23224211 |
12442121 |
|
755 |
13233221 |
22315211 |
11533121 |
|
756 |
11415122 |
14134112 |
21541112 |
|
757 |
12324221 |
13225112 |
21541211 |
|
758 |
11415221 |
14134211 |
12451112 |
|
759 |
41421113 |
12316112 |
11542112 |
|
760 |
51421121 |
13225211 |
12451211 |
|
761 |
41421212 |
12316211 |
11542211 |
|
762 |
41421311 |
11411144 |
16111142 |
|
763 |
32331113 |
21411152 |
16111241 |
|
764 |
42331121 |
11411243 |
15211133 |
|
765 |
31422113 |
21411251 |
25211141 |
|
766 |
41422121 |
11411342 |
15211232 |
|
767 |
31422212 |
11411441 |
15211331 |
|
768 |
32331311 |
62321111 |
16121141 |
|
769 |
31422311 |
12321152 |
15212141 |
|
770 |
23241113 |
61412111 |
14311124 |
|
771 |
33241121 |
11412152 |
24311132 |
|
772 |
22332113 |
12321251 |
14311223 |
|
773 |
23241212 |
11412251 |
24311231 |
|
774 |
21423113 |
53231111 |
14311322 |
|
775 |
22332212 |
52322111 |
14311421 |
|
776 |
23241311 |
51413111 |
15221132 |
|
777 |
21423212 |
44141111 |
14312132 |
|
778 |
22332311 |
43232111 |
15221231 |
|
779 |
21423311 |
42323111 |
14312231 |
|
780 |
14151113 |
41414111 |
13411115 |
|
781 |
24151121 |
34142111 |
23411123 |
|
782 |
13242113 |
33233111 |
33411131 |
|
783 |
23242121 |
32324111 |
13411214 |
|
784 |
12333113 |
31415111 |
23411222 |
|
785 |
13242212 |
24143111 |
13411313 |
|
786 |
14151311 |
23234111 |
23411321 |
|
787 |
11424113 |
22325111 |
13411412 |
|
788 |
12333212 |
21416111 |
13411511 |
|
789 |
13242311 |
14144111 |
14321123 |
|
790 |
11424212 |
13235111 |
24321131 |
|
791 |
12333311 |
12326111 |
13412123 |
|
792 |
11424311 |
11421143 |
23412131 |
|
793 |
13243121 |
21421151 |
13412222 |
|
794 |
11425121 |
11421242 |
14321321 |
|
795 |
41431211 |
11421341 |
13412321 |
|
796 |
31432112 |
12331151 |
15231131 |
|
797 |
31432211 |
11422151 |
14322131 |
|
798 |
22342112 |
11431142 |
13413131 |
|
799 |
21433112 |
11431241 |
22511114 |
|
800 |
21433211 |
11441141 |
32511122 |
|
801 |
13252112 |
45111113 |
22511213 |
|
802 |
12343112 |
45111212 |
32511221 |
|
803 |
11434112 |
45111311 |
22511312 |
|
804 |
11434211 |
35112113 |
22511411 |
|
805 |
15111116 |
45112121 |
13421114 |
|
806 |
15111215 |
35112212 |
23421122 |
|
807 |
25111223 |
35112311 |
12512114 |
|
808 |
15111314 |
25113113 |
22512122 |
|
809 |
15111413 |
35113121 |
23421221 |
|
810 |
15111512 |
25113212 |
12512213 |
|
811 |
15112124 |
25113311 |
13421312 |
|
812 |
15112223 |
15114113 |
12512312 |
|
813 |
15112322 |
25114121 |
13421411 |
|
814 |
15112421 |
15114212 |
12512411 |
|
815 |
15113132 |
15114311 |
14331122 |
|
816 |
15113231 |
15115121 |
13422122 |
|
817 |
24211115 |
54211112 |
14331221 |
|
818 |
24211214 |
14211161 |
12513122 |
|
819 |
34211222 |
54211211 |
13422221 |
|
820 |
24211313 |
45121112 |
12513221 |
|
821 |
34211321 |
44212112 |
31611113 |
|
822 |
24211412 |
45121211 |
41611121 |
|
823 |
24211511 |
44212211 |
31611212 |
|
824 |
15121115 |
35122112 |
31611311 |
|
825 |
25121123 |
34213112 |
22521113 |
|
826 |
14212115 |
35122211 |
32521121 |
|
827 |
24212123 |
34213211 |
21612113 |
|
828 |
25121222 |
25123112 |
22521212 |
|
829 |
14212214 |
24214112 |
21612212 |
|
830 |
24212222 |
25123211 |
22521311 |
|
831 |
14212313 |
24214211 |
21612311 |
|
832 |
24212321 |
15124112 |
13431113 |
|
833 |
14212412 |
14215112 |
23431121 |
|
834 |
15121511 |
15124211 |
12522113 |
|
835 |
14212511 |
14215211 |
13431212 |
|
836 |
15122123 |
63311111 |
11613113 |
|
837 |
25122131 |
13311152 |
12522212 |
|
838 |
14213123 |
13311251 |
13431311 |
|
839 |
24213131 |
54221111 |
11613212 |
|
840 |
14213222 |
53312111 |
12522311 |
|
841 |
15122321 |
45131111 |
11613311 |
|
842 |
14213321 |
44222111 |
14341121 |
|
843 |
15123131 |
43313111 |
13432121 |
|
844 |
14214131 |
35132111 |
12523121 |
|
845 |
33311114 |
34223111 |
11614121 |
|
846 |
33311213 |
33314111 |
31621112 |
|
847 |
33311312 |
25133111 |
31621211 |
|
848 |
33311411 |
24224111 |
22531112 |
|
849 |
24221114 |
23315111 |
21622112 |
|
850 |
23312114 |
15134111 |
22531211 |
|
851 |
33312122 |
14225111 |
21622211 |
|
852 |
34221221 |
13316111 |
13441112 |
|
853 |
23312213 |
12411143 |
12532112 |
|
854 |
33312221 |
22411151 |
13441211 |
|
855 |
23312312 |
12411242 |
11623112 |
|
856 |
24221411 |
12411341 |
12532211 |
|
857 |
23312411 |
13321151 |
11623211 |
|
858 |
15131114 |
12412151 |
31631111 |
|
859 |
14222114 |
11511134 |
22541111 |
|
860 |
15131213 |
21511142 |
21632111 |
|
861 |
25131221 |
11511233 |
13451111 |
|
862 |
13313114 |
21511241 |
12542111 |
|
863 |
14222213 |
11511332 |
11633111 |
|
864 |
15131312 |
11511431 |
16211132 |
|
865 |
13313213 |
12421142 |
16211231 |
|
866 |
14222312 |
11512142 |
15311123 |
|
867 |
15131411 |
12421241 |
25311131 |
|
868 |
13313312 |
11512241 |
15311222 |
|
869 |
14222411 |
11521133 |
15311321 |
|
870 |
15132122 |
21521141 |
16221131 |
|
871 |
14223122 |
11521232 |
15312131 |
|
872 |
15132221 |
11521331 |
14411114 |
|
873 |
13314122 |
12431141 |
24411122 |
|
874 |
14223221 |
11522141 |
14411213 |
|
875 |
13314221 |
11531132 |
24411221 |
|
876 |
42411113 |
11531231 |
14411312 |
|
877 |
42411212 |
11541131 |
14411411 |
|
878 |
42411311 |
36112112 |
15321122 |
|
879 |
33321113 |
36112211 |
14412122 |
|
880 |
32412113 |
26113112 |
15321221 |
|
881 |
42412121 |
26113211 |
14412221 |
|
882 |
32412212 |
16114112 |
23511113 |
|
883 |
33321311 |
16114211 |
33511121 |
|
884 |
32412311 |
45212111 |
23511212 |
|
885 |
24231113 |
36122111 |
23511311 |
|
886 |
34231121 |
35213111 |
14421113 |
|
887 |
23322113 |
26123111 |
24421121 |
|
888 |
33322121 |
25214111 |
13512113 |
|
889 |
22413113 |
16124111 |
23512121 |
|
890 |
23322212 |
15215111 |
13512212 |
|
891 |
24231311 |
14311151 |
14421311 |
|
892 |
22413212 |
13411142 |
13512311 |
|
893 |
23322311 |
13411241 |
15331121 |
|
894 |
22413311 |
12511133 |
14422121 |
|
895 |
15141113 |
22511141 |
13513121 |
|
896 |
25141121 |
12511232 |
32611112 |
|
897 |
14232113 |
12511331 |
32611211 |
|
898 |
24232121 |
13421141 |
23521112 |
|
899 |
13323113 |
12512141 |
22612112 |
|
900 |
14232212 |
11611124 |
23521211 |
|
901 |
15141311 |
21611132 |
22612211 |
|
902 |
12414113 |
11611223 |
14431112 |
|
903 |
13323212 |
21611231 |
13522112 |
|
904 |
14232311 |
11611322 |
14431211 |
|
905 |
12414212 |
11611421 |
12613112 |
|
906 |
13323311 |
12521132 |
13522211 |
|
907 |
15142121 |
11612132 |
12613211 |
|
908 |
14233121 |
12521231 |
32621111 |
|
909 |
13324121 |
11612231 |
23531111 |
|
910 |
12415121 |
11621123 |
22622111 |
|
911 |
51511112 |
21621131 |
14441111 |
|
912 |
51511211 |
11621222 |
13532111 |
|
913 |
42421112 |
11621321 |
12623111 |
|
914 |
41512112 |
12531131 |
16311122 |
|
915 |
42421211 |
11622131 |
16311221 |
|
916 |
41512211 |
11631122 |
15411113 |
|
917 |
33331112 |
11631221 |
25411121 |
|
918 |
32422112 |
14411141 |
15411212 |
|
919 |
33331211 |
13511132 |
15411311 |
|
920 |
31513112 |
13511231 |
16321121 |
|
921 |
32422211 |
12611123 |
15412121 |
|
922 |
31513211 |
22611131 |
24511112 |
|
923 |
24241112 |
12611222 |
24511211 |
|
924 |
23332112 |
12611321 |
15421112 |
|
925 |
24241211 |
13521131 |
14512112 |
|
926 |
22423112 |
12612131 |
15421211 |
|
927 |
23332211 |
12621122 |
14512211 |
|
928 |
21514112 |
12621221 |
33611111 |
ПРИЛОЖЕНИЕ B
(обязательное)
Набор знаков по умолчанию для режима байтового уплотнения
Набор знаков по умолчанию для режима байтового уплотнения приведен в таблице B.1.
Таблица B.1 - Набор знаков по умолчанию для режима байтового уплотнения
|
д.з. |
знак |
д.з. |
знак |
д.з. |
знак |
д.з. |
знак |
д.з. |
знак |
д.з. |
знак |
д.з. |
знак |
д.з. |
знак |
|
0 |
NUL |
32 |
space |
64 |
@ |
96 |
` |
128 |
Ç |
160 |
á |
192 |
└ |
224 |
α |
|
1 |
SOH |
33 |
! |
65 |
A |
97 |
a |
129 |
ü |
161 |
í |
193 |
┴ |
225 |
β |
|
2 |
STX |
34 |
“ |
66 |
В |
98 |
b |
130 |
é |
162 |
ó |
194 |
┬ |
226 |
Γ |
|
3 |
ЕТХ |
35 |
# |
67 |
С |
99 |
с |
131 |
â |
163 |
ú |
195 |
├ |
227 |
π |
|
4 |
EOT |
36 |
$ |
68 |
D |
100 |
d |
132 |
ä |
164 |
ñ |
196 |
─ |
228 |
Σ |
|
5 |
ENQ |
37 |
% |
69 |
E |
101 |
e |
133 |
à |
165 |
Ñ |
197 |
┼ |
229 |
σ |
|
6 |
ACK |
38 |
& |
70 |
F |
102 |
f |
134 |
å |
166 |
ª |
198 |
╞ |
230 |
μ |
|
7 |
BEL |
39 |
‘ |
71 |
G |
103 |
g |
135 |
ç |
167 |
º |
199 |
╟ |
231 |
τ |
|
8 |
BS |
40 |
( |
72 |
H |
104 |
h |
136 |
ê |
168 |
¿ |
200 |
╚ |
232 |
Φ |
|
9 |
НТ |
41 |
) |
73 |
I |
105 |
i |
137 |
ë |
169 |
⌐ |
201 |
╔ |
233 |
Θ |
|
10 |
LF |
42 |
* |
74 |
J |
106 |
j |
138 |
è |
170 |
¬ |
202 |
╩ |
234 |
Ω |
|
И |
VT |
43 |
+ |
75 |
К |
107 |
k |
139 |
ï |
171 |
½ |
203 |
╦ |
235 |
δ |
|
12 |
FF |
44 |
, |
76 |
L |
108 |
l |
140 |
î |
172 |
¼ |
204 |
╠ |
236 |
∞ |
|
13 |
CR |
45 |
- |
77 |
M |
109 |
m |
141 |
ì |
173 |
¡ |
205 |
═ |
237 |
ø |
|
14 |
SO |
46 |
. |
78 |
N |
110 |
n |
142 |
Ä |
174 |
« |
206 |
╬ |
238 |
ε |
|
15 |
SI |
47 |
/ |
79 |
О |
111 |
o |
143 |
Å |
175 |
» |
207 |
╧ |
239 |
∩ |
|
16 |
DLE |
48 |
0 |
80 |
P |
112 |
p |
144 |
É |
176 |
░ |
208 |
╨ |
240 |
≡ |
|
17 |
DC1 |
49 |
1 |
81 |
Q |
113 |
q |
145 |
æ |
177 |
▒ |
209 |
╤ |
241 |
± |
|
18 |
DC2 |
50 |
2 |
82 |
R |
114 |
r |
146 |
Æ |
178 |
▓ |
210 |
╥ |
242 |
≥ |
|
19 |
DC3 |
51 |
3 |
83 |
S |
115 |
s |
147 |
ô |
179 |
│ |
211 |
╙ |
243 |
≤ |
|
20 |
DC4 |
52 |
4 |
84 |
T |
116 |
t |
148 |
ö |
180 |
┤ |
212 |
╘ |
244 |
⌠ |
|
21 |
NAK |
53 |
5 |
85 |
U |
117 |
u |
149 |
ò |
181 |
╡ |
213 |
╒ |
245 |
⌡ |
|
22 |
SYN |
54 |
6 |
86 |
V |
118 |
v |
150 |
û |
182 |
╢ |
214 |
╓ |
246 |
÷ |
|
23 |
ETB |
55 |
7 |
87 |
W |
119 |
w |
151 |
ù |
183 |
╖ |
215 |
╫ |
247 |
≈ |
|
24 |
CAN |
56 |
8 |
88 |
X |
120 |
x |
152 |
ÿ |
184 |
╕ |
216 |
╪ |
248 |
◦ |
|
25 |
EM |
57 |
9 |
89 |
Y |
121 |
y |
153 |
Ö |
185 |
╣ |
217 |
┘ |
249 |
• |
|
26 |
SUB |
58 |
: |
90 |
Z |
122 |
z |
154 |
Ü |
186 |
║ |
218 |
┌ |
250 |
∙ |
|
27 |
ESC |
59 |
; |
91 |
[ |
123 |
{ |
155 |
¢ |
187 |
╗ |
219 |
█ |
251 |
√ |
|
28 |
FS |
60 |
< |
92 |
\ |
124 |
| |
156 |
£ |
188 |
╝ |
220 |
▄ |
252 |
ⁿ |
|
29 |
GS |
61 |
= |
93 |
] |
125 |
} |
157 |
¥ |
189 |
╜ |
221 |
▌ |
253 |
² |
|
30 |
RS |
62 |
> |
94 |
^ |
126 |
~ |
158 |
₧ |
190 |
╛ |
222 |
▐ |
254 |
■ |
|
31 |
US |
63 |
? |
95 |
_ |
127 |
DEL |
159 |
ƒ |
191 |
┐ |
223 |
▀ |
255 |
NBSP |
Примечания
1 д.з. - десятичное значение знака версии КОИ-8.
2 Первая половина набора знаков (с десятичными значениями от 0 до 127) соответствует ИСО/МЭК 646 (соответствует [4]). Вторая половина (с десятичными значениями от 128 до 255) соответствует кодовой странице РС437.
ПРИЛОЖЕНИЕ С
(обязательное)
Алгоритм кодирования режима байтового уплотнения
Это преобразование следует использовать в режиме байтового уплотнения. С его помощью могут быть преобразованы шесть байтов данных в пять кодовых слов данных PDF417 по уравнению
b5 × 2565 + b4 × 2564 + b3 × 2563 + b2 × 2562 + b1 × 2561 + b0 × 2560 = d4 × 9004 + d3 × 9003 + d2 × 9002 + d1 × 9001 + d0 × 9000,
где b - десятичное значение байта данных (от 0 до 255);
d - кодовое слово данных.
Для преобразования базы 256 в базу 900 может быть использован следующий алгоритм:
1. принимают t в качестве временной переменной
2. вычисляют t = b5 × 2565 + b4 × 2564 + b3 × 2563 + b2 × 2562 + b1 × 2561 + b0 × 2560
3. каждое кодовое слово вычисляют следующим образом:
для каждого кодового слова данных di = d0 ... d4
di = t mod 900
t = t div 900
Требуется закодировать знаки данных в режиме байтового уплотнения b5, ..., b0 {231, 101, 11, 97, 205, 2}
Вычисляют сумму t с использованием десятичных значений шести знаков в режиме байтового уплотнения: t = 231 × 2565 + 101 × 2564 + 11 × 2563 + 97 × 2562 + 205 × 2561 + 2 × 2560 = 254421168672002
Вычисляют кодовое слово 0
d0 = 254421168672002 mod 900 = 302
t = 254421168672002 div 900 = 282690187413
Вычисляют кодовое слово 1
d1 = 282690187413 mod 900 = 213
t = 282690187413 div 900 = 314100208
Вычисляют кодовое слово 2
d2 = 314100208 mod 900 = 208
t = 314100208 div 900 = 349000
Вычисляют кодовое слово 3
d3 = 349000 mod 900 = 700
t = 349000 div 900 = 387
Вычисляют кодовое слово 4
d4 = 387 mod 900 = 387
t = 387 div 900 = 0
Последовательность кодовых слов d4, ..., d0 представляет собой 387, 700, 208, 213, 302
ПРИЛОЖЕНИЕ D
(обязательное)
Алгоритм кодирования режима цифрового уплотнения
Это преобразование должно использоваться в режиме цифрового уплотнения. С его помощью могут быть преобразованы группы, содержащие до 44 последовательных цифровых разрядов включительно, в 15 (или менее) кодовых слов данных PDF417.
Для преобразования базы 10 в базу 900 может быть использован следующий алгоритм:
a) принимают t в качестве временной переменной
b) устанавливают начальное значение t в виде группы последовательных цифровых разрядов, количество которых доходит до 44, которой предшествует единица
c) каждое кодовое слово вычисляют в следующем порядке:
Для каждого кодового слова данных di = d0, ..., dn-1
di = t mod 900
t = t div 900
Если t = 0, то кодирование прекращается
Требуется закодировать числовую цепочку из 15 цифр 000213298174000.
В начале числовой цепочки ставят 1 и устанавливают исходное значение в виде:
t = 1000213298174000
Вычисляют кодовое слово 0
d0 = 1000213298174000 mod 900 = 200
t = 1000213298174000 div 900 = 1111348109082
Вычисляют кодовое слово 1
d1 = 1111348109082 mod 900 = 282
t = 1111348109082 div 900= 1234831232
Вычисляют кодовое слово 2
d2 = 1234831232 mod 900 = 632
t = 1234831232 div 900 = 1372034
Вычисляют кодовое слово 3
d3 = 1372034 mod 900 = 434
t = 1372034 div 900 = 1524
Вычисляют кодовое слово 4
d4 = 1524 mod 900 = 624
t = 1524 div 900 = 1
Вычисляют кодовое слово 5
d5 = 1 mod 900 = 1
t = 1 div 900 = 0
Последовательность кодовых слов d5, ..., d0 представляют в виде: 1, 624, 434, 632, 282, 200
ПРИЛОЖЕНИЕ Е
(обязательное)
Выбор пользователем уровня коррекции ошибок
E.1 Рекомендуемый минимальный уровень коррекции ошибок
Минимальный уровень коррекции ошибки должен соответствовать приведенному в таблице Е.1.
Таблица Е.1 - Рекомендуемый уровень коррекции ошибок
|
Минимальный уровень коррекции ошибок |
|
|
От 1 до 40 |
2 |
|
« 41 « 160 |
3 |
|
« 161 « 320 |
4 |
|
« 321 « 863 |
5 |
Для приблизительного подсчета количества кодовых слов данных из содержания данных при использовании таблицы Е.1 следует использовать 1,8 текстовых знаков на кодовое слово данных в режиме текстового уплотнения, 2,9 цифры на кодовое слово данных в режиме цифрового уплотнения и 1,2 байта на кодовое слово данных в режиме байтового уплотнения.
Если возможны значительные повреждения изображения символа, следует использовать более высокие уровни коррекции ошибок. В замкнутых системах применений могут использоваться уровни коррекции ошибок ниже рекомендуемых.
E.2 Прочие факторы, принимаемые во внимание пользователем при выборе уровня коррекции ошибок
Целью прикладного стандарта, регламентирующего требования по применению, должно быть использование особенностей исправления ошибок без уменьшения емкости для данных.
При выборе уровня коррекции ошибок пользователь должен учитывать следующие факторы:
1) должен выбираться рекомендуемый уровень коррекции ошибок (в соответствии с таблицей Е.1);
2) в связи с тем, что наибольшее количество кодовых слов данных в символе составляет 925, большое количество кодовых слов данных ограничивает наивысший уровень коррекции ошибок, который может быть использован. Количество кодовых слов данных более 415 исключает применение уровня коррекции ошибок 8. Количество кодовых слов данных более 799 исключает применение уровней 6, 7 и 8. Количество кодовых слов данных более 863, исключает уровень коррекции ошибок 5. Следовательно, не рекомендуется увеличивать число кодовых слов до 863;
3) при высокой вероятности того, что в символах PDF417 возможны недостающие или полностью стертые кодовые слова, уровень коррекции ошибок может быть увеличен до уровня 8 или более высокого уровня, при котором количество кодовых слов коррекции ошибок заполняет матрицу максимального размера, допустимого применением;
4) более предпочтительным является поддержка высокого качества печати символа, по сравнению с компенсацией низкого качества печати увеличением уровня коррекции ошибки. Вместо выбора наивысшего уровня коррекции ошибок рекомендуется установить больший размер X или специальную подложку и материалы, способные обеспечить высокое качество печати символа PDF417.
ПРИЛОЖЕНИЕ F
(обязательное)
Таблицы коэффициентов для вычисления кодовых слов коррекции ошибок PDF417
В таблицах F.1 - F.9 приведены коэффициенты для вычисления кодовых слов коррекции ошибок для уровней коррекции ошибок от 0 до 8.
Таблица F.1 - Коэффициенты для уровня коррекции ошибок 0
|
0 |
1 |
|
|
αj |
27 |
917 |
Таблица F.2 - Коэффициенты для уровня коррекции ошибок 1
|
0 |
1 |
2 |
3 |
|
|
αj |
522 |
568 |
723 |
809 |
Таблица F.3 - Коэффициенты для уровня коррекции ошибок 2
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
|
αj |
237 |
308 |
436 |
284 |
646 |
653 |
428 |
379 |
Таблица F.4 - Коэффициенты для уровня коррекции ошибок 3
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
|
|
αj |
274 |
562 |
232 |
755 |
599 |
524 |
801 |
132 |
295 |
116 |
442 |
428 |
295 |
42 |
176 |
65 |
Таблица F.5 - Коэффициенты для уровня коррекции ошибок 4
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
|
|
αj |
361 |
575 |
922 |
525 |
176 |
586 |
640 |
321 |
536 |
742 |
677 |
742 |
687 |
284 |
193 |
517 |
|
j |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
|
αj |
273 |
494 |
263 |
147 |
593 |
800 |
571 |
320 |
803 |
133 |
231 |
390 |
685 |
330 |
63 |
410 |
Таблица F.6 - Коэффициенты для уровня коррекции ошибок 5
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
|
|
αj |
539 |
422 |
6 |
93 |
862 |
771 |
453 |
106 |
610 |
287 |
107 |
505 |
733 |
877 |
381 |
612 |
|
j |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
|
αj |
723 |
476 |
462 |
172 |
430 |
609 |
858 |
822 |
543 |
376 |
511 |
400 |
672 |
762 |
283 |
184 |
|
j |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
|
αj |
440 |
35 |
519 |
31 |
460 |
594 |
225 |
535 |
517 |
352 |
605 |
158 |
651 |
201 |
488 |
502 |
|
j |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
|
αj |
648 |
733 |
717 |
83 |
404 |
97 |
280 |
771 |
840 |
629 |
4 |
381 |
843 |
623 |
264 |
543 |
Таблица F.7 - Коэффициенты для уровня коррекции ошибок 6
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
|
|
αj |
521 |
310 |
864 |
547 |
858 |
580 |
296 |
379 |
53 |
779 |
897 |
444 |
400 |
925 |
749 |
415 |
|
j |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
|
αj |
822 |
93 |
217 |
208 |
928 |
244 |
583 |
620 |
246 |
148 |
447 |
631 |
292 |
908 |
490 |
704 |
|
j |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
|
αj |
516 |
258 |
457 |
907 |
594 |
723 |
674 |
292 |
272 |
96 |
684 |
432 |
686 |
606 |
860 |
569 |
|
j |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
|
αj |
193 |
219 |
129 |
186 |
236 |
287 |
192 |
775 |
278 |
173 |
40 |
379 |
712 |
463 |
646 |
776 |
|
j |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
|
αj |
171 |
491 |
297 |
763 |
156 |
732 |
95 |
270 |
447 |
90 |
507 |
48 |
228 |
821 |
808 |
898 |
|
j |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
93 |
94 |
95 |
|
αj |
784 |
663 |
627 |
378 |
382 |
262 |
380 |
602 |
754 |
336 |
89 |
614 |
87 |
432 |
670 |
616 |
|
j |
96 |
97 |
98 |
99 |
100 |
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
|
αj |
157 |
374 |
242 |
726 |
600 |
269 |
375 |
898 |
845 |
454 |
354 |
130 |
814 |
587 |
804 |
34 |
|
j |
112 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
|
αj |
211 |
330 |
539 |
297 |
827 |
865 |
37 |
517 |
834 |
315 |
550 |
86 |
801 |
4 |
108 |
539 |
Таблица F.8 - Коэффициенты для уровня коррекции ошибок 7
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
|
|
αj |
524 |
894 |
75 |
766 |
882 |
857 |
74 |
204 |
82 |
586 |
708 |
250 |
905 |
786 |
138 |
720 |
|
j |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
|
αj |
858 |
194 |
311 |
913 |
275 |
190 |
375 |
850 |
438 |
733 |
194 |
280 |
201 |
280 |
828 |
757 |
|
j |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
|
αj |
710 |
814 |
919 |
89 |
68 |
569 |
11 |
204 |
796 |
605 |
540 |
913 |
801 |
700 |
799 |
137 |
|
j |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
|
αj |
439 |
418 |
592 |
668 |
353 |
859 |
370 |
694 |
325 |
240 |
216 |
257 |
284 |
549 |
209 |
884 |
|
j |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
|
αj |
315 |
70 |
329 |
793 |
490 |
274 |
877 |
162 |
749 |
812 |
684 |
461 |
334 |
376 |
849 |
521 |
|
j |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
93 |
94 |
95 |
|
αj |
307 |
291 |
803 |
712 |
19 |
358 |
399 |
908 |
103 |
511 |
51 |
8 |
517 |
225 |
289 |
470 |
|
j |
96 |
97 |
98 |
99 |
100 |
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
|
αj |
637 |
731 |
66 |
255 |
917 |
269 |
463 |
830 |
730 |
433 |
848 |
585 |
136 |
538 |
906 |
90 |
|
j |
112 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
|
αj |
2 |
290 |
743 |
199 |
655 |
903 |
329 |
49 |
802 |
580 |
355 |
588 |
188 |
462 |
10 |
134 |
|
j |
128 |
129 |
130 |
131 |
132 |
133 |
134 |
135 |
136 |
137 |
138 |
139 |
140 |
141 |
142 |
143 |
|
αj |
628 |
320 |
479 |
130 |
739 |
71 |
263 |
318 |
374 |
601 |
192 |
605 |
142 |
673 |
687 |
234 |
|
j |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
157 |
158 |
159 |
|
αj |
722 |
384 |
177 |
752 |
607 |
640 |
455 |
193 |
689 |
707 |
805 |
641 |
48 |
60 |
732 |
621 |
|
j |
160 |
161 |
162 |
163 |
164 |
165 |
166 |
167 |
168 |
169 |
170 |
171 |
172 |
173 |
174 |
175 |
|
αj |
895 |
544 |
261 |
852 |
655 |
309 |
697 |
755 |
756 |
60 |
231 |
773 |
434 |
421 |
726 |
528 |
|
j |
176 |
177 |
178 |
179 |
180 |
181 |
182 |
183 |
184 |
185 |
186 |
187 |
188 |
189 |
190 |
191 |
|
αj |
503 |
118 |
49 |
795 |
32 |
144 |
500 |
238 |
836 |
394 |
280 |
566 |
319 |
9 |
647 |
550 |
|
j |
192 |
193 |
194 |
195 |
196 |
197 |
198 |
199 |
200 |
201 |
202 |
203 |
204 |
205 |
206 |
207 |
|
αj |
73 |
914 |
342 |
126 |
32 |
681 |
331 |
792 |
620 |
60 |
609 |
441 |
180 |
791 |
893 |
754 |
|
j |
208 |
209 |
210 |
211 |
212 |
213 |
214 |
215 |
216 |
217 |
218 |
219 |
220 |
221 |
222 |
223 |
|
αj |
605 |
383 |
228 |
749 |
760 |
213 |
54 |
297 |
134 |
54 |
834 |
299 |
922 |
191 |
910 |
532 |
|
j |
224 |
225 |
226 |
227 |
228 |
229 |
230 |
231 |
232 |
233 |
234 |
235 |
236 |
237 |
238 |
239 |
|
αj |
609 |
829 |
189 |
20 |
167 |
29 |
872 |
449 |
83 |
402 |
41 |
656 |
505 |
579 |
481 |
173 |
|
j |
240 |
241 |
242 |
243 |
244 |
245 |
246 |
247 |
248 |
249 |
250 |
251 |
252 |
253 |
254 |
255 |
|
αj |
404 |
251 |
688 |
95 |
497 |
555 |
642 |
543 |
307 |
159 |
924 |
558 |
648 |
55 |
497 |
10 |
Таблица F.9 - Коэффициенты для уровня коррекции ошибок 8
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
|
|
αj |
352 |
77 |
373 |
504 |
35 |
599 |
428 |
207 |
409 |
574 |
118 |
498 |
285 |
380 |
350 |
492 |
|
j |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
|
αj |
197 |
265 |
920 |
155 |
914 |
299 |
229 |
643 |
294 |
871 |
306 |
88 |
87 |
193 |
352 |
781 |
|
j |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
|
αj |
846 |
75 |
327 |
520 |
435 |
543 |
203 |
666 |
249 |
346 |
781 |
621 |
640 |
268 |
794 |
534 |
|
j |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
|
αj |
539 |
781 |
408 |
390 |
644 |
102 |
476 |
499 |
290 |
632 |
545 |
37 |
858 |
916 |
552 |
41 |
|
j |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
|
αj |
542 |
289 |
122 |
272 |
383 |
800 |
485 |
98 |
752 |
472 |
761 |
107 |
784 |
860 |
658 |
741 |
|
j |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
93 |
94 |
95 |
|
αj |
290 |
204 |
681 |
407 |
855 |
85 |
99 |
62 |
482 |
180 |
20 |
297 |
451 |
593 |
913 |
142 |
|
j |
96 |
97 |
98 |
99 |
100 |
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
|
αj |
808 |
684 |
287 |
536 |
561 |
76 |
653 |
899 |
729 |
567 |
744 |
390 |
513 |
192 |
516 |
258 |
|
j |
112 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
|
αj |
240 |
518 |
794 |
395 |
768 |
848 |
51 |
610 |
384 |
168 |
190 |
826 |
328 |
596 |
786 |
303 |
|
j |
128 |
129 |
130 |
131 |
132 |
133 |
134 |
135 |
136 |
137 |
138 |
139 |
140 |
141 |
142 |
143 |
|
αj |
570 |
381 |
415 |
641 |
156 |
237 |
151 |
429 |
531 |
207 |
676 |
710 |
89 |
168 |
304 |
402 |
|
j |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
157 |
158 |
159 |
|
αj |
40 |
708 |
575 |
162 |
864 |
229 |
65 |
861 |
841 |
512 |
164 |
477 |
221 |
92 |
358 |
785 |
|
j |
160 |
161 |
162 |
163 |
164 |
165 |
166 |
167 |
168 |
169 |
170 |
171 |
172 |
173 |
174 |
175 |
|
αj |
288 |
357 |
850 |
836 |
827 |
736 |
707 |
94 |
8 |
494 |
114 |
521 |
2 |
499 |
851 |
543 |
|
j |
176 |
177 |
178 |
179 |
180 |
181 |
182 |
183 |
184 |
185 |
186 |
187 |
188 |
189 |
190 |
191 |
|
αj |
152 |
729 |
771 |
95 |
248 |
361 |
578 |
323 |
856 |
797 |
289 |
51 |
684 |
466 |
533 |
820 |
|
j |
192 |
193 |
194 |
195 |
196 |
197 |
198 |
199 |
200 |
201 |
202 |
203 |
204 |
205 |
206 |
207 |
|
αj |
669 |
45 |
902 |
452 |
167 |
342 |
244 |
173 |
35 |
463 |
651 |
51 |
699 |
591 |
452 |
578 |
|
j |
208 |
209 |
210 |
211 |
212 |
213 |
214 |
215 |
216 |
217 |
218 |
219 |
220 |
221 |
222 |
223 |
|
αj |
37 |
124 |
298 |
332 |
552 |
43 |
427 |
119 |
662 |
777 |
475 |
850 |
764 |
364 |
578 |
911 |
|
j |
224 |
225 |
226 |
227 |
228 |
229 |
230 |
231 |
232 |
233 |
234 |
235 |
236 |
237 |
238 |
239 |
|
αj |
283 |
711 |
472 |
420 |
245 |
288 |
594 |
394 |
511 |
327 |
589 |
777 |
699 |
688 |
43 |
408 |
|
j |
240 |
241 |
242 |
243 |
244 |
245 |
246 |
247 |
248 |
249 |
250 |
251 |
252 |
253 |
254 |
255 |
|
αj |
842 |
383 |
721 |
521 |
560 |
644 |
714 |
559 |
62 |
145 |
873 |
663 |
713 |
159 |
672 |
729 |
|
j |
256 |
257 |
258 |
259 |
260 |
261 |
262 |
263 |
264 |
265 |
266 |
267 |
268 |
269 |
270 |
271 |
|
αj |
624 |
59 |
193 |
417 |
158 |
209 |
563 |
564 |
343 |
693 |
109 |
608 |
563 |
365 |
181 |
772 |
|
j |
272 |
273 |
274 |
275 |
276 |
277 |
278 |
279 |
280 |
281 |
282 |
283 |
284 |
285 |
286 |
287 |
|
αj |
677 |
310 |
248 |
353 |
708 |
410 |
579 |
870 |
617 |
841 |
632 |
860 |
289 |
536 |
35 |
777 |
|
j |
288 |
289 |
290 |
291 |
292 |
293 |
294 |
295 |
296 |
297 |
298 |
299 |
300 |
301 |
302 |
303 |
|
αj |
618 |
586 |
424 |
833 |
77 |
597 |
346 |
269 |
757 |
632 |
695 |
751 |
331 |
247 |
184 |
45 |
|
j |
304 |
305 |
306 |
307 |
308 |
309 |
310 |
311 |
312 |
313 |
314 |
315 |
316 |
317 |
318 |
319 |
|
αj |
787 |
680 |
18 |
66 |
407 |
369 |
54 |
492 |
228 |
613 |
830 |
922 |
437 |
519 |
644 |
905 |
|
j |
320 |
321 |
322 |
323 |
324 |
325 |
326 |
327 |
328 |
329 |
330 |
331 |
332 |
333 |
334 |
335 |
|
αj |
789 |
420 |
305 |
441 |
207 |
300 |
892 |
827 |
141 |
537 |
381 |
662 |
513 |
56 |
252 |
341 |
|
j |
336 |
337 |
338 |
339 |
340 |
341 |
342 |
343 |
344 |
345 |
346 |
347 |
348 |
349 |
350 |
351 |
|
αj |
242 |
797 |
838 |
837 |
720 |
224 |
307 |
631 |
61 |
87 |
560 |
310 |
756 |
665 |
397 |
808 |
|
j |
352 |
353 |
354 |
355 |
356 |
357 |
358 |
359 |
360 |
361 |
362 |
363 |
364 |
365 |
366 |
367 |
|
αj |
851 |
309 |
473 |
795 |
378 |
31 |
647 |
915 |
459 |
806 |
590 |
731 |
425 |
216 |
548 |
249 |
|
j |
368 |
369 |
370 |
371 |
372 |
373 |
374 |
375 |
376 |
377 |
378 |
379 |
380 |
381 |
382 |
383 |
|
αj |
321 |
881 |
699 |
535 |
673 |
782 |
210 |
815 |
905 |
303 |
843 |
922 |
281 |
73 |
469 |
791 |
|
j |
384 |
385 |
386 |
387 |
388 |
389 |
390 |
391 |
392 |
393 |
394 |
395 |
396 |
397 |
398 |
399 |
|
αj |
660 |
162 |
498 |
308 |
155 |
422 |
907 |
817 |
187 |
62 |
16 |
425 |
535 |
336 |
286 |
437 |
|
j |
400 |
401 |
402 |
403 |
404 |
405 |
406 |
407 |
408 |
409 |
410 |
411 |
412 |
413 |
414 |
415 |
|
αj |
375 |
273 |
610 |
296 |
183 |
923 |
116 |
667 |
751 |
353 |
62 |
366 |
691 |
379 |
687 |
842 |
|
j |
416 |
417 |
418 |
419 |
420 |
421 |
422 |
423 |
424 |
425 |
426 |
427 |
428 |
429 |
430 |
431 |
|
αj |
37 |
357 |
720 |
742 |
330 |
5 |
39 |
923 |
311 |
424 |
242 |
749 |
321 |
54 |
669 |
316 |
|
j |
432 |
433 |
434 |
435 |
436 |
437 |
438 |
439 |
440 |
441 |
442 |
443 |
444 |
445 |
446 |
447 |
|
αj |
342 |
299 |
534 |
105 |
667 |
488 |
640 |
672 |
576 |
540 |
316 |
486 |
721 |
610 |
46 |
656 |
|
j |
448 |
449 |
450 |
451 |
452 |
453 |
454 |
455 |
456 |
457 |
458 |
459 |
460 |
461 |
462 |
463 |
|
αj |
447 |
171 |
616 |
464 |
190 |
531 |
297 |
321 |
762 |
752 |
533 |
175 |
134 |
14 |
381 |
433 |
|
j |
464 |
465 |
466 |
467 |
468 |
469 |
470 |
471 |
472 |
473 |
474 |
475 |
476 |
477 |
478 |
479 |
|
αj |
717 |
45 |
111 |
20 |
596 |
284 |
736 |
138 |
646 |
411 |
877 |
669 |
141 |
919 |
45 |
780 |
|
j |
480 |
481 |
482 |
483 |
484 |
485 |
486 |
487 |
488 |
489 |
490 |
491 |
492 |
493 |
494 |
495 |
|
αj |
407 |
164 |
332 |
899 |
165 |
726 |
600 |
325 |
498 |
655 |
357 |
752 |
768 |
223 |
849 |
647 |
|
j |
496 |
497 |
498 |
499 |
500 |
501 |
502 |
503 |
504 |
505 |
506 |
507 |
508 |
509 |
510 |
511 |
|
αj |
63 |
310 |
863 |
251 |
366 |
304 |
282 |
738 |
675 |
410 |
389 |
244 |
31 |
121 |
303 |
263 |
ПРИЛОЖЕНИЕ G
(обязательное)
Компакт PDF417
Компакт PDF417 (Compact PDF417) можно использовать в тех случаях, когда обеспечение поверхности соответствующего размера для нанесения символа является предметом первостепенной важности и маловероятно повреждение символа. Если повреждение символа маловероятно (например, в условиях офиса), можно исключить правые индикаторы строк и сократить комбинацию штрихов и пробелов знака СТОП до штриха шириной в один модуль в соответствии с рисунком G.1. Эта процедура сокращает объем кодовых слов, не относящихся к данным, с четырех кодовых слов на строку до двух, с некоторым компромиссом в части выполнения декодирования и устойчивости или способности противостоять помехам, повреждениям, пыли и т.д.

Рисунок G.1 - Компакт PDF417
Эта версия уменьшения кодовых слов, не относящихся к данным, именуется Компакт PDF417, символ которого полностью совместим в процессе декодирования с типовым PDF417.
Символ Компакт PDF417, имеющий менее 6 строк, кодирует число столбцов только в одном кодовом слове, которое не учитывается при коррекции ошибок и, поэтому он особенно уязвим при плохом качестве печати или повреждении.
Примечание - В предыдущих версиях PDF417 (например, в [2] и [3]), использовался термин «Сжатый PDF417» (Truncated PDF417). Термин Компакт PDF417 (Compact PDF417) является более предпочтительным во избежание путаницы с общим использованием термина «сжатый» (‘truncated’).
ПРИЛОЖЕНИЕ H
(обязательное)
Макро PDF417
H.1 Обзор Макро PDF417
Макро PDF417 (Macro PDF417) предусматривает стандартный механизм создания распределенного представления файлов, слишком больших для того, чтобы быть представленными в отдельном символе PDF417. Символы Макро PDF417 отличаются от обычных символов PDF417 тем, что они содержат дополнительную управляющую информацию в управляющем блоке Макро PDF417.
При использовании Макро PDF417 большие файлы данных разделяются на несколько сегментов файла и кодируются в отдельных символах. Управляющий блок определяет идентификацию файла, последовательность соединения, а также иную нестандартную информацию о файле. Декодер Макро PDF417 использует информацию управляющего блока для точного восстановления файла независимо от того, в каком порядке был отсканирован символ.
H.2 Синтаксис Макро PDF417
Каждый символ Макро PDF417 должен кодировать управляющий блок Макро PDF417, в котором содержится управляющая информация. Управляющий блок начинается с кодового слова Макро маркера (Macro marker) (значение 928). Управляющий блок следует за блоком данных, с которым он связан; число кодовых слов в управляющем блоке Макро PDF417 учитывают как данные и включают в значение дескриптора длины символа. Окончание управляющего блока Макро PDF417 идентифицируется началом кодовых слов коррекции ошибок.
Примечание - Символ, не содержащий данных пользователя, отличных от управляющего блока Макро PDF417, является действительным символом.
Управляющий блок Макро PDF417 должен содержать не менее двух обязательных полей: индекса сегмента (segment index) и идентификации файла (file ID). Он также может содержать ряд необязательных полей (H.2.3).
На рисунке H.1 показано расположение управляющего блока в символе Макро PDF417.
Схема стандартного символа PDF417
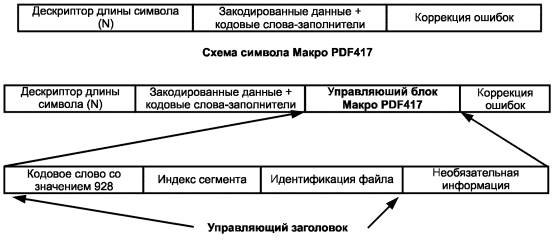
Рисунок Н.1 Схемы символов PDF417
H.2.1 Индекс сегмента
В Макро PDF417 каждый символ представляет сегмент целого файла. Для восстановления целого файла сегменты необходимо разместить в определенном порядке. Этот процесс облегчает управляющая информация, содержащаяся в управляющем блоке Макро PDF417. Для файла, разделенного на множество j символов Макро PDF417, поле индекса сегмента (segment index) в каждом управляющем блоке Макро PDF417 символа содержит значения от 0 до j - 1, соответствующие относительной позиции содержимого этого символа внутри распределенного представления.
Поле индекса сегмента состоит из поля длиной в два кодовых слова и кодируется с помощью режима цифрового уплотнения в соответствии с 4.4.4. Значение индекса сегмента должно быть дополнено начальными нулями до пяти разрядов до применения режима цифрового уплотнения. Переключение в режим цифрового уплотнения не требует явной фиксации в режиме (кодового слова 902). Самое большое допустимое значение в поле индекса сегмента равно 99998. Таким образом, распределенное представление файла данных может содержать до 99999 символов Макро PDF417.
Примечание - При переводе в объем информации 99999 символов составят примерно 110 млн байтов данных в режиме байтового уплотнения, или 184 млн знаков в режиме текстового уплотнения, или около 300 млн знаков в режиме цифрового уплотнения.
H.2.2 Поле идентификации файла
Для каждого связанного символа Макро PDF417 поле идентификации файла (file ID) содержит одно и то же значение. Оно обеспечивает соответствие всех воссоединенных данных символов одному распределенному представлению файла. Идентификация файла имеет поле переменной длины, которое начинается с первого кодового слова, следующего за индексом сегмента, и продолжается до начала необязательных полей (если таковые присутствуют) или до окончания управляющего блока Макро PDF417 (в случае отсутствия необязательных полей).
Каждое кодовое слово в идентификации файла может иметь значение от 0 до 899, эффективно создавая серии идентификации файла для номеров базы 900. Каждое кодовое слово серии передается в качестве 3-разрядного десятичного значения представления КОИ-7.
Примечание - На эффективность схемы идентификации файла влияет длина поля идентификации файла и соответствие алгоритма, используемого для генерирования значения идентификации файла.
Необязательные поля (optional field) могут следовать после идентификации файла. Каждое необязательное поле начинается со специальной последовательности-указателя (tag sequence) и продолжается до начала следующего необязательного поля (если таковое присутствует) или окончания управляющего блока (если отсутствует следующее необязательное поле). Последовательность-указатель состоит из кодового слова 923, за которым следует отдельное кодовое слово указателя поля (field designator). В каждом необязательном поле данные, следующие за последовательностью-указателем, имеют интерпретацию, обусловленную спецификой поля. Не следует использовать пустые необязательные поля. В таблице H.1 представлено соответствие между текущими заданными указателями полей и необязательным содержимым полей. Каждое необязательное поле начинается с подразумеваемого возврата к режиму уплотнения, представленному в таблице H.1, и с подразумеваемого возвращения к ECI 000002 (или GLI 0 для кодирующих устройств, соответствующих ранее опубликованным стандартам PDF417). Управляющая последовательность ECI и функции фиксации в режиме и регистра в режиме могут быть использованы, но только в необязательных полях, изначально находящихся в режиме текстового уплотнения.
Таблица H.1 - Указатели необязательных полей Макро PDF417
|
Указатель поля (field designator) |
Переданное значение байтов |
Содержимое |
Исходный режим уплотнения |
Фиксированный режим уплотнения |
Общее число кодовых слов |
|
0 |
48 |
Имя файла (File Name) |
Текстовое уплотнение |
N |
Переменное |
|
1 |
49 |
Число сегментов (Segment Count) |
Цифровое уплотнение |
Y |
4 |
|
2 |
50 |
Отметка времени (Time Stamp) |
Цифровое уплотнение |
Y |
6 |
|
3 |
51 |
Отправитель (Sender) |
Текстовое уплотнение |
N |
Переменное |
|
4 |
52 |
Получатель (Addressee) |
Текстовое уплотнение |
N |
Переменное |
|
5 |
53 |
Размер файла (File Size) |
Цифровое уплотнение |
Y |
Переменное |
|
6 |
54 |
Контрольная сумма (Checksum) |
Цифровое уплотнение |
Y |
4 |
Примечания
1 Y в графе «Фиксированный режим уплотнения» означает, что в этом поле не допускается использовать никакие функции фиксации в режиме и регистра в режиме.
2 В последней графе «Общее число кодовых слов» учитывают последовательность-указатель из двух кодовых слов.
Эти поля всегда представляют параметры глобального файла и поэтому не нуждаются в представлении в управляющем блоке более чем в одном символе Макро PDF417 в пределах распределенного представления файла, за исключением поля числа сегментов (segment count), в соответствии с представленным ниже. Сегмент, который содержит эти поля, задается специальной реализацией кодирующего устройства. Если особое поле подлежит появлению более чем в одном сегменте, оно должно идентично появиться в каждом сегменте. Не существует определенного порядка для необязательных полей.
В соответствии с таблицей H.1 все необязательные поля используют стандарт высокоуровневого кодирования PDF417. Действующий режим по умолчанию в начале каждого поля должен быть задан в таблице H.1 безотносительно к функциям фиксации в режиме и регистра в режиме, ранее присутствующим в символе.
Особое построение необязательного поля должно соответствовать нижеследующему:
- поле числа сегментов (segment count) (идентифицирующее общее количество символов PDF417 в распределенном файле) может содержать значения от 1 до 99999 и должно быть закодировано как два кодовых слова. Если используют необязательное поле числа сегментов, то оно должно быть представлено в каждом сегменте;
- поле отметки времени подлежит интерпретации в режиме цифрового уплотнения. Оно указывает отметку времени в исходном файле, и выглядит как астрономическое время работы в секундах, начиная с 1970:01:01:00:00:00 по Гринвичу (т.е. 00:00:00 среднего времени по Гринвичу на 1 января 1970 г.). Используя данный формат, четыре кодовых слова могут закодировать любую дату в пределах следующих 200 столетий;
- поле размера файла (file size) содержит размер в байтах исходного единого файла;
- поле контрольной суммы (checksum) содержит значение контрольной суммы 16-битного (2 байта) циклически избыточного кода (CRC), использующей полином CCITT - 16 x16 + x12 + x5 + 1, вычисленный по всему исходному единому файлу.
Примечания
1 Размер файла и контрольную сумму следует вычислять из исходного файла до прибавления любых управляющих последовательностей ECI, используемых для кодирования интерпретаций расширенного канала. Имеется в виду, что если приемное устройство проверяет контрольную сумму после осуществления приема, исходный файл должен быть дословно восстановлен. Это требуется исключительно для проверки данной необязательной контрольной суммы, чтобы не проводились никакие задаваемые пользователем или необязательные преобразования потока байтов даже в том случае, когда проверка может быть выполнена в процессе декодирования ECI.
2 Если используют CRC, вычисление может быть выполнено до отправки данных к принтеру или в самом принтере на основе возможностей принтера.
Значения указателя поля больше 6 в настоящее время не заданы. Однако оборудование, декодирующее PDF417, должно декодировать и передавать любые встречающиеся необязательные поля со значением указателя поля от 7 до 9 (значение байта от 55 до 57) или от A до Z (значения байта от 65 до 90) путем обработки данных поля в качестве данных, исходно находящихся в режиме текстового уплотнения и имеющих переменную длину.
H.2.4 Ограничитель Макро PDF417
Управляющий блок в символе, представляющем последний сегмент файла Макро PDF417, содержит особый маркер (называемый ограничителем Макро PDF417 - Macro PDF417 terminator), состоящий из кодового слова 922 в конце управляющего блока. Управляющий блок любого иного символа должен оканчиваться после любых необязательных полей, не имеющих специального ограничителя.
H.3 Рассмотрение высокоуровневого кодирования
Несмотря на то, что Макро PDF417 подразумевает механизм логического связывания множества символов, при высокоуровневом кодировании PDF417 каждый символ должен оставаться отдельным объектом. Таким образом сфера действия переключения режима должна ограничиваться рамками символа, в котором она возникла. Каждый символ должен обязательно начинаться в подрежиме прописных букв режима текстового уплотнения.
Два обязательных поля закодированы следующим образом: поле индекса сегмента закодировано в режиме цифрового уплотнения, а поле идентификации файла кодируется как последовательность чисел базы 900.
В контексте необязательного поля управляющего блока режимы уплотнения, указанные в таблице H.1, должны замещать текущие режимы, заданные кодовыми словами идентификатора режима в пределах области кодовых слов данных символа. Однако сфера действия текущей интерпретации расширенного канала переходит через управляющий блок Макро PDF417 к началу следующего символа Макро PDF417. Каждое поле управляющего блока Макро начинается с подразумеваемого возврата к ECI 000002 (или GLI 0 для устройств кодирования, совместимых с ранее опубликованными стандартами PDF417). Также должна быть возможность установить другую ECI внутри необязательного поля управляющего блока в режиме текстового уплотнения, например, для правильного представления греческого имени получателя. Управляющую последовательность ECI можно разместить в любой допустимой позиции (4.5.3) после кодового слова 923 (начало необязательного поля Макро PDF417 - Beginning of Macro PDF417 Optional Field).
H.4 Пример кодирования
Приведенный пример показывает кодирование управляющего блока Макро PDF417:
Комплект Макро PDF417 кодирует в общей сложности 4567 байт, заданных пользователем данных в четырех символах PDF417 (или сегментах файлов).
Другие «заголовки» данных, подлежащие кодированию:
- идентификация файла = 17база 900 53база 900,
- число сегментов, подлежащих использованию,
- отправитель: CEN BE,
- получатель: ISO CH.
Примечание - Поля: число сегментов, отправитель и получатель - являются тремя необязательными полями, выбираемыми пользователем.
При условии, что кодирующее устройство располагает необязательные поля в первом символе, кодирование управляющего блока Макро PDF417 в этом символе должно соответствовать приведенному ниже:
[последнее кодовое слово данных] [928]A [111] [100]B [017] [053]C [923] [001]D [111] [104]E [923] [003]F [064] [416] [034]G [923] [004]H [258] [446] [067]I [первое кодовое слово коррекции ошибок] ...
В последнем из четырех символов будет следующий управляющий блок Макро PDF417:
[последнее кодовое слово данных] [928]A [111] [103]В [017] [053]C [923] [001]D [111] [104]E [922]J [первое слово коррекции ошибок],
где A - кодовое слово макро-маркера (Macro marker),
B - идентификация сегмента файла (File Segment ID).
Сегменты файла пронумерованы от 0 до j - 1 и закодированы с использованием режима цифрового уплотнения.
1-й сегмент = 00000 = кодовые слова со значениями 111, 100
4-й сегмент = 00003 = кодовые слова со значениями 111, 103
C - идентификация файла по базе 900
D - признак поля числа сегментов
E - число сегментов
F - признак поля отправителя
G - поле отправителя, кодирующее CEN BE
H - признак поля получателя
I - поле получателя, кодирующее ИСО СН
J - ограничитель Макро PDF417.
H.5 Макро PDF417 и протокол интерпретации расширенного канала
Независимый от символики протокол интерпретации расширенного канала (протокол ECI) был разработан после того, как PDF417 был регламентирован как символика. PDF417 поддерживал собственную систему идентификаторов глобальной метки (GLI), предшественницу и базу протокола ECI, с самой первой публикации спецификаций символики в 1994 г. ([2] и [3]). Поэтому следует принять во внимание ранние внедрения GLI. Существуют два обстоятельства, которые следует учитывать:
- GLI 0 и GLI 1 (равнозначные ECI 000000 и ECI 000001) были только интерпретациями, установленными в исходных спецификациях PDF417 ([2] и [3]). Прежние правила для Макро PDF417 приведены в H.5.1;
- иные назначения ECI, использование которых совместно с Макро PDF417 приведено в H.5.2.
H.5.1 Макро PDF417 с интерпретациями расширенного канала 000000 и 000001 (GLI 0 и GLI 1)
Так как GLI были действительной частью исходной спецификации PDF417 ([2] и [3]), является логичным наличие кодирующих устройств GLI и Макро PDF417, объединенных в одну единицу. Исходная спецификация ([2] и [3]) к символике PDF417 вызывала обязательную логическую схему с возвратом к GLI в начале второго и последующего символов Макро PDF417; таким образом, каждый символ должен начинаться с интерпретации по умолчанию. В случае GLI 0 и GLI 1 (эквивалентным ECI 000000 и ECI 000001) это не оказывает никакого внутреннего воздействия на кодирование. Однако для некоторых сложных интерпретаций расширенного канала логическую схему с возвратом к GLI 0 трудно реализовать независимым от символики способом.
Кодирующее программное обеспечение, соответствующее исходной спецификации для Макро PDF417 и GLI 0 и GLI 1, полностью подходит для ранее существовавших применений, а также применений GLI, задаваемых пользователем (теперь именуемых ECI), так как сфера действия системы по определению является ограниченной.
Все ECI, имеющие нумерацию 000002 или выше, не должны быть заданы логической схемой с возвратом к GLI 0. Следовательно, символы PDF417 не должны смешивать ECI 000000 и ECI 000001 с интерпретациями расширенного канала, имеющими более высокую нумерацию (за исключением закрытых систем).
H.5.2 Макро PDF417 и прочие интерпретации расширенного канала
Кодирующее устройство ECI может быть независимым от символики и генерировать поток байтов для ввода данных в кодирующее устройство символики PDF417. Кодирующее устройство ECI должно работать так, как если бы имелся отдельный поток данных независимо от размера файла. Таким образом, после вызова ECI должна сохраняться через сегменты до появления другой ECI или окончания закодированных данных. Это необходимо, например, в случае, где назначение ECI представляет схему шифрования, в которой не приемлем возврат в GLI 0.
Кодирующим устройствам Макро PDF417, соответствующим настоящему стандарту, нет необходимости кодировать преобладающую ECI в начале следующих символов PDF417.
Примечание - Может понадобиться проведение нескольких итераций для генерации логической схемы кодирования окончания символа, например режим цифрового уплотнения не должен растягиваться на два сегмента, но два отдельных блока режима цифрового уплотнения могут быть закодированы в окончании одного символа и в начале следующего. Эти условия относятся к Макро PDF417 и высокоуровневому кодированию (в соответствии с H.3), а не относятся к Макро PDF417 и ECI.
H.6 Передача данных Макро PDF417
Передача информации управляющего блока Макро PDF417 должна трактоваться так же, как интерпретируемые ECI. Независимый от символики протокол ECI приведен ниже; исходный протокол PDF417 приведен в приложении N. Несмотря на то, что управляющий блок Макро PDF417 кодируется в конце данных символа, при использовании протокола ECI он передается перед данными символа.
Три кодовых слова (922, 923 и 928) отмечают кодирование управляющего блока Макро PDF417 или одной из его составных частей. Декодирование происходит следующим образом:
1) если последовательность начинается с кодового слова 928 (макро-маркер):
a) кодовое слово 928 передается в качестве управляющей последовательности 92, 77, 73, которую представляет \MI в интерпретации по умолчанию;
b) следующие два кодовых слова идентифицируют индекс сегмента. Они закодированы в режиме цифрового уплотнения и декодируются как 5-разрядное число в диапазоне от 00000 до 99998;
c) следующие кодовые слова кодируют поле идентификации файла, которое должно быть одинаковым для всех связанных символов Макро PDF417. Поле идентификации файла оканчивается кодовым словом 922 или 923, или завершается с окончанием закодированных данных в символе. Каждое кодовое слово преобразуется в 3-разрядное число в диапазоне 000 - 899 (т.е. номер кодового слова) и передается как три значения байтов (с десятичными значениями в диапазоне от 48 до 57) после управляющего заголовка: 92, 77, 70, который представлен \MF в интерпретации по умолчанию;
2) если последовательность начинается с кодового слова 923 (начало необязательного поля Макро PDF417):
a) кодовое слово 923 передается как управляющая последовательность 92, 77, 79, которая представлена \МО в интерпретации по умолчанию;
b) следующее кодовое слово представляет один из указателей необязательного поля (field designator), приведенных в таблице H.1, передается как отдельный байт, представляющий значение знака КОИ для указателя;
c) следующие кодовые слова несут содержимое данных указателя необязательного поля. Необязательное поле оканчивается кодовым словом 922 или 923, или с окончанием закодированных данных в символе. Промежуточные кодовые слова следует преобразовывать в соответствии с правилами декодирования соответствующего режима уплотнения, приведенными в таблице H.1. Полученные в результате данные могут иметь переменную длину;
3) при идентификации ограничителя Макро PDF417 (кодовое слово 922) следует передать управляющую последовательность 92, 77, 90, которая представлена \MZ в интерпретации по умолчанию;
4) в конце управляющего блока Макро PDF417, как определено для окончания кодируемых данных в символе, следует передать управляющую последовательность 92, 77 89, которая представлена \MZ в интерпретации по умолчанию.
Примечание - Эта управляющая последовательность не является явно закодированной в символе.
Все поля управляющего блока Макро PDF417 для символа (сегмента) должны быть переданы как единый блок, начинающийся с \МI... и оканчивающийся \MY. Передача управляющего блока Макро PDF417 должна предварять передачу остатка закодированного сегмента файла даже в том случае, если управляющий блок Макро PDF417 закодирован в конце символа.
Управляющий блок Макро PDF417 для первого символа, индекс сегмента = 0 и идентификация файла (100, 200, 300) будут закодированы в символе как последовательность кодовых слов:
[928] [111] [100] [100] [200] [300]
Она будет передаваться следующим образом:
передача данных (байты):
92, 77, 73, 48, 48, 48, 48, 48, 92, 77, 70, 49, 48, 48, 50, 48, 48, 51, 48, 48, 92, 77, 89
интерпретация в знаках КОИ-7:
\MI00000\MF100200300\МY
После сканирования символов Макро PDF417 функция депакетирования восстановит исходное сообщение с учетом того, что символы могли быть сканированы не по порядку. Если система работает в буферизованном режиме, функция депакетирования находится в декодере; при работе в небуферизованном режиме эта функция находится в системе приема.
Декодеры должны предусматривать специфичный для каждого декодера метод, посредством которого обработка заданной идентификации файла Макро PDF417 (Macro PDF417) может быть отменена таким образом, чтобы позволить декодеру начать обработку новой идентификации файла. Это необходимо для предотвращения условий блокировки, которая может возникнуть при потере или невозможности декодирования одного или более символов заданной идентификации файла.
H.6.1 Работа в буферизованном режиме
При работе в буферизованном режиме (buffered mode) депакетизация должна выполняться в декодере/считывающем устройстве. В зависимости от конфигурации оборудования он будет отправлять:
- восстановленные данные, без управляющего блока Макро PDF417
или
- один управляющий блок Макро PDF417 (который сам по себе может быть восстановлен для включения всех необязательных полей, присутствующих в любых символах) для нахождения в начале всего закодированного сообщения. Полученный в результате управляющий блок Макро PDF417 должен иметь свое поле индекса Макро (Macro Index) со значением, равным 0, и должен включать в себя поле окончания файла Макро (Macro-end-of-file) (в сущности, для обозначения всего восстановленного сообщения как первый и единственный Макро сегмент псевдосерий).
H.6.2 Работа в небуферизованном режиме
В небуферизованном режиме (unbuffered mode) депакетирование должно быть выполнено в системе приема. Каждый переданный управляющий блок Макро PDF417 должен представлять все обязательные и необязательные поля, которые в действительности закодированы в символе.
При конфигурировании в небуферизованном режиме декодер может иметь необязательную конфигурацию, допускающую, чтобы последовательные символы имели одну идентификацию файла (File ID). Эта процедура может быть целесообразной только в том случае, если декодер сконфигурирован для передачи управляющего блока Макро PDF417 в систему приема, и эта система приема разработана для отслеживания идентификации файла управляющего блока Макро PDF417 с целью определения, когда был обработан весь файл. Символы с разной идентификацией файлов или без нее (например, отдельный символ, не являющийся частью комплекта символов Макро PDF417) должны рассматриваться в соответствии с установками системы приема.
Для облегчения контроля того, что все символы набора символов Макро PDF417 (Macro PDF417) были получены в небуферизованном режиме, следует всякий раз, когда возможно, использовать необязательное поле числа сегментов как часть закодированного Управляющего блока Макро PDF417.
H.6.3 Передача с возвратом к нулю
В связи с тем, что в [2] и [3] были определены правила для GLI 0 и GLI 1, которые незначительно отличаются от правил для ECI, считывающее устройство, соответствующее этому международному стандарту, должно эмитировать особые управляющие последовательности при передаче символов, содержащих явные вызовы GLI 1, в двух ситуациях:
1) декодер должен передавать управляющую последовательность GLI 0 или управляющую последовательность ECI 000000 (в зависимости от того, какой протокол передачи запрограммирован для использования) после передачи данных любого символа Макро PDF417, данные которого заканчиваются в интерпретации GLI 1 (ECI 000001);
2) декодер должен передавать GLI 1 (ECI 000001) в начале каждого необязательного поля переменной длины, закодированного в режиме текстового уплотнения в управляющем блоке Макро PDF417, если данные, предваряющие это поле, заканчиваются в интерпретации GLI 1 (ECI 000001).
Это требование применяется вне зависимости от режима (буферизованного или небуферизованного) и вне зависимости от того, использование какого из двух протоколов для передачи запрограммировано в декодере (протокола ECI или исходного протокола PDF417).
ПРИЛОЖЕНИЕ J
(обязательное)
Испытание качества символа PDF417
Поскольку в настоящее время ИСО/МЭК 15416 еще не полностью регламентирует испытание символов PDF417, для оценки символов PDF417 следует использовать процедуры, приведенные в J.1 - J.3.
J.1 Класс, основанный на знаках СТАРТ и СТОП
Знаки СТАРТ и СТОП PDF417 подлежат оценке в соответствии с ИСО/МЭК 15416 с использованием размера апертуры, указанного в соответствующем стандарте по применению. Следует использовать рекомендуемый алгоритм декодирования (в соответствии с K.2) для оценки параметров «декодирование» и «декодируемость» знаков СТАРТ и СТОП. Контрольные сканирования PDF417 должны быть классифицированы с использованием этих алгоритмов.
Примечание - Этот метод не обеспечивает полной классификации качества символов PDF417 (J.2).
При выполнении измерения линии сканирования должны быть перпендикулярны к знакам СТАРТ и СТОП. Это измерение для знака СТАРТ и СТОП может использоваться для целей управления процессом. Этот метод не должен быть чувствительным к отклонениям при печати, параллельным знакам СТАРТ и СТОП. Если требуется полный анализ процесса нанесения, то символы PDF417 должны быть напечатаны и проконтролированы при двух ориентациях.
J.2 Класс, основанный на знаках символа
Эта оценка основана на анализе всего символа PDF417, отсканированного с помощью подходящей апертуры, указанной в соответствующем стандарте по применению. Контрольные сканирования должны быть выполнены под небольшим углом к линии, перпендикулярной к знакам СТАРТ и СТОП, подобно тому, как используется перекрестное сканирование строк во всех сканированиях.
1) Необходимо определить значения глобального порога (global threshold) для каждого сканирования, равного (Rmax + Rmin)/2, где Rmax - наибольший коэффициент отражения при сканировании и Rmin - наименьший коэффициент отражения. Все элементы с коэффициентами отражения выше глобального порога (global threshold) считают пробелами, а те, в которых они ниже, - штрихами. Измерения E должны определяться в соответствии с рисунком K.1 и использованием положения края, определяемого в точке с коэффициентом отражения, являющимся средним арифметическим значением для соседних штриха и пробела. Обработка сканирований должна продолжаться до тех пор, пока не будет стабилизировано число декодированных кодовых слов.
2) Необходимо декодировать символ и для уровней коррекции ошибок от 1 до 8 вычислить содержание неиспользованных коррекций ошибок по формуле 1,0 - ((1 + 2f)/(2s+1 - p)), где p = 2 или 3 (в соответствии с формулами в 4.7.2). Для уровня коррекции ошибок, равного 0, при декодировании символа неиспользованная коррекция ошибок будет равна 1,0. Затем следует сравнить этот результат со значениями, указанными в таблице J.1, для определения класса, основанного на знаках символа штрихового кода.
Таблица J.1 - Класс символа в зависимости от неиспользованной коррекции ошибок
|
Класс |
|
|
≥ 0,62 |
4 |
|
≥ 0,50 |
3 |
|
≥ 0,37 |
2 |
|
≥ 0,25 |
1 |
|
< 0,25 |
0 |
J.3 Полный класс символа PDF417
За полный класс символа принимают меньшее значение класса, основанного на знаках СТАРТ и СТОП в соответствии с J.1, либо оценку, основанную на знаках символа в соответствии с J.2.
ПРИЛОЖЕНИЕ K
(обязательное)
Рекомендуемый алгоритм декодирования для PDF417
Рекомендуемый алгоритм декодирования применяют для вычисления декодируемости при оценке качества символа с использованием методов, приведенных в ИСО/МЭК 15416.
При оценке качества символа с помощью настоящего рекомендуемого алгоритма декодирования символ PDF417 должен декодироваться в виде серии линий сканирования вдоль этого символа до знаков СТАРТ или СТОП, но необязательно строка за строкой. Символ может быть декодирован с помощью номера кластера и в том случае, если линия сканирования проходит через две или более строк. Последовательности штрихов и пробелов знаков символа PDF417 (е) декодируют с использованием измерений «от края до края».
Символ PDF417 подлежит декодированию в четыре этапа:
1) инициализация для установки матрицы символа;
2) декодирование линии с использованием рекомендуемого алгоритма декодирования;
3) заполнение матрицы;
4) интерпретация.
K.1 Инициализация
В начале процесса декодирования для установления параметров структуры символа (числа строк r, числа столбцов c) и уровней коррекции ошибок должно быть выполнено достаточное количество декодирований вдоль линии сканирования (K.2). Эта информация кодируется в левом и нравом индикаторах строки, примыкающих соответственно к знакам СТАРТ и СТОП.
После проведения инициализации параметров структуры символа должна быть установлена матрица, отражающая размер (число строк со столбцов) декодируемого символа. Матрица должна исключать знаки СТАРТ и СТОП и индикаторы строк.
K.2 Рекомендуемый алгоритм декодирования для декодирования линии
Декодируемая линия сканирования должна содержать свободную зону, знак СТАРТ и/или СТОП, один индикатор строки и один или более знаков символа в области данных. Линия сканирования может пересекать более чем одну строку. Алгоритм должен включать следующие этапы по декодированию линии:
1) подтверждают наличие свободной зоны;
2) для каждой последовательности штрихов и пробелов знака символа (включая знак СТАРТ и СТОП) подсчитывают ширину в соответствии с рисунком K.1:
p,
e1, e2, e3, e4, e5 и e6
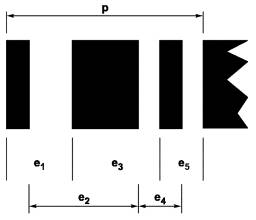
Рисунок K.1 - Размеры для декодирования
3) преобразуют размеры e1, е2, е3, е4, е5 и е6 в нормализованные значения Е1, Е2, Е3, Е4, Е5 и Е6, которые должны представлять полную ширину этих размеров в модулях. Используют следующий способ для определения i-го значения:
при 1,5p/17 ≤ еi < 2,5p/17 Еi = 2;
при 2,5p/17 ≤ еi < 3,5p/17 Еi = 3;
при 3,5p/17 ≤ еi < 4,5p/17 Еi = 4;
при 4,5p/17 ≤ еi < 5,5p/17 Еi = 5;
при 5,5p/17 ≤ еi < 6,5p/17 Еi = 6;
при 6,5p/17 ≤ еi < 7,5p/17 Еi = 7;
при 7,5p/17 ≤ еi < 8,5p/17 Еi = 8;
при 8,5p/17 ≤ еi < 9,5p/17 Еi = 9.
В противном случае последовательность штрихов и пробелов знака символа должна считаться ошибочной.
4) после нахождения знаков СТАРТ и СТОП предпринимают попытку декодировать индикатор строки и знаки символа в количестве, соответствующем числу столбцов матрицы в направлении, выведенном из декодированных знаков СТАРТ и СТОП. Последовательности штрихов и пробелов знаков символа декодируют в соответствии с этапом 5;
5) вычисляют номер кластера K знака символа по формуле
K = (Е1 - Е2 + Е5 - Е6 + 9) mod 9.
Примечание - Формула дает результаты, идентичные результатам уравнения, приведенного в 4.3.1.
Номер кластера K должен быть равен 0, 3 или 6; в противном случае знак символа и связанное с ним кодовое слово должны считаться ошибочными;
6) восстанавливают значение кодового слова по таблице декодирования (приложение А) с использованием семи значений (значения кластера K и значений E1, E2, Е3, Е4, Е5 и Е6) в качестве ключевых. Эти значения можно вычислить из последовательностей штрихов и пробелов, приведенных в приложении А.
Примечание - В вычислении неявно используют номер кластера для обнаружения всех ошибок декодирования, вызванных отдельными несистематическими ошибками положения края на величину одного модуля;
7) как только будут установлены знаки СТАРТ и СТОП, должны использоваться значения кодового слова левого индикатора строки и/или правого индикатора строки для установления параметров структуры символа. Применяют обращенные уравнения, приведенные в 4.11.3.1 и 4.11.3.2 для установления номера строки (F), числа строк (r), числа столбцов (c) и уровня коррекции ошибок (s);
8) выполнение вторичных проверок (ускорение сканирования, абсолютные синхронизированные размеры, свободные зоны и т.д.), результаты которых должны быть приемлемы для отдельных характеристик считывающего устройства.
K.3 Заполнение матрицы
Для заполнения матрицы строк (r) и столбцов (c), установленных с помощью процедуры инициализации, должна использоваться следующая процедура:
1) устанавливают начальное значение подсчета стираний r × c;
2) для каждого сканирования следует декодировать число кодовых слов, равное числу столбцов в матрице;
3) действительные результаты декодирования размещают в матрице на соответствующих местах, определенных по номеру строки (из индикаторов строк) и значению кластера.
Если происходит пересечение строк, линия сканирования будет характеризоваться разными номерами строк, определяемыми левым и правым индикаторами строк. Номер кластера следует использовать для интерполяции правильного номера строки для каждого отдельного действительного кодового слова.
Сканирование с декодированием характеризуется знаками СТАРТ и СТОП, в нем присутствует левый индикатор строки с номером строки 7 и правый индикатор строки с номером строки 10. В матрице присутствуют 10 столбцов. Линия сканирования при декодировании не охватила три кодовых слова, поскольку она не оставалась полностью в одной строке для полного перехода, однако на основании синхронизации элементов известно положение этих «неустановленных» кодовых слов.

Рисунок K.2 - Схема, представляющая линию сканирования, пересекающую строки
Кластеры расположены в следующей последовательности: «неустановленный», 6, 6, 6, «неустановленный», 0, 0, «неустановленный», 3, 3.
Используя систему обозначений матрицы для строки (r) и столбца (c), кодовые слова подлежат заполнению согласно позициям: «неустановленная», (8,2), (8,3), (8,4), «неустановленная», (9,6), (9,7), «неустановленная», (10,9) и (10,10).
Примечание - Этот пример является крайним случаем в связи с тем, что линия сканирования пересекает 4 строки, но с его помощью достигается декодирование 70 % кодовых слов;
4) по мере заполнения матрицы подсчет стираний V должен быть уменьшен на одно значение для каждого действительного кодового слова;
5) если уровень коррекции ошибок не равен 0, может быть предпринято исправление ошибок, когда число неустановленных кодовых слов (число стираний V) будет удовлетворять уравнениям, приведенным в 4.7.2 (при V = I и f = 0). Если устранить ошибки не удается, то должны быть собраны дополнительные кодовые слова;
6) если уровень коррекции ошибок равен 0, то следует ввести два кодовых слова коррекции ошибок.
Дальнейшие подробности обнаружения и коррекции ошибок приведены в приложении L.
K.4 Интерпретация
Начиная с первоначального состояния подрежима прописные буквы режима текстового уплотнения, кодовые слова данных следует интерпретировать в соответствии с режимами уплотнения.
ПРИЛОЖЕНИЕ L
(обязательное)
Процедуры коррекции ошибок
Схема восстановления может быть вызвана при общем числе неустановленных кодовых слов v менее или равном заданному соответствующим уравнением в 4.7.2 (v = l, f = 0). Неустановленные кодовые слова подлежат замещению нулями, и позицией неустановленного кодового слова 1 является jl при l = 1, 2, ..., v. Составляют полином знака символа:
C(x) = Cn-1xn-1 + Cn-2xn-2 + , ..., + C1x1 + C0,
где показатели n являются считанными кодовыми словами с первым кодовым словом Cn-1;
n - общее количество кодовых слов.
Рассчитывают значения синдрома k (от S1 до Sk) путем следующих вычислений:
C(x) при x = 3i
для i = 1 до i = k,
где k - число знаков коррекции ошибок в символе = 2s+1.
Схема генерации синдромов приведена на рисунке L.1.
Рисунок L.1 - Делитель синдрома символа
Так как позиции неустановленных кодовых слов известны из jl при l = 1, 2, ..., v, полином местонахождения ошибок σ(x) для этих известных позиций можно вычислить по формуле
σ(x) = (1 - β1x)(1 - β2x), ..., (1 - βvx) = 1 + σ1x + , ..., + σvxv,
где βl = 3j.
Полином местонахождения ошибок σ(x) можно корректировать, чтобы включить позиции ошибок. Это можно выполнить с помощью алгоритма Берлекампа-Массе (Berlekamp-Massey). Исходный текст приведен в [6].
Далее следует удостовериться, что количество стираний и ошибок удовлетворяет соответствующему уравнению, вычисляющему возможности исправления ошибок, приведенному в 4.7.2.
Решение σ(x) = 0 дает позицию для t ошибок, где t ≥ 0; если t = 0, то ошибки отсутствуют. Далее рассчитывают значение ошибок ejl для позиции jl, l = 1, ..., v + t. Для вычисления ошибок требуется вспомогательный полином Z(x), который определяют следующим образом:
Z(x) = 1 + (s1 + σ1)x + (s2 + σ1s1 + σ2)x2 + ... + (sη + σ1sη-1 + σ2sη-2 + ... + ση) xη,
где η = v + t.
Значение ошибок в позиции jl таким образом задается через
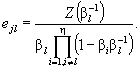
После успешного решения для ошибок дополнения значений ошибок добавляются к кодовым словам в соответствующих позициях.
ПРИЛОЖЕНИЕ М
(обязательное)
Идентификатор символики
ИСО/МЭК 15424 предусматривает унифицированную методику формирования сообщения о считываемой символике, наборе вариантов обработки в устройстве считывания и других особых свойствах символики.
Идентификатор символики (symbology identifier) PDF417 должен быть представлен в виде
]Lm,
где ] - знак флага идентификатора символики (десятичное значение КОИ-793);
L - знак кода для символики PDF417;
М - знак-модификатор, имеющий одно из значений, приведенных в таблице М.1.
Таблица М.1 - Значения модификаторов идентификатора символики для PDF417
|
Вариант обработки |
|
|
0 |
Устройство считывания установлено в соответствии с протоколом, приведенным в спецификациях символики [2] и [3], опубликованных в 1994 (приложение N). Примечание - Во время передачи этого варианта устройство приема не может точно определить, были ли вызваны ECI или в передаче повторились байты данных со значением 92 |
|
1 |
Устройство считывания установлено в соответствии с протоколом настоящего стандарта для интерпретации расширенного канала (в соответствии с 4.17.2). Все знаки данных со значением 92 дублируются |
|
2 |
Устройство считывания установлено в соответствии с протоколом настоящего стандарта для операций базового канала (4.17.1). Знаки данных со значением 92 не дублируются. Примечание - Когда декодер установлен на этот режим, небуферизованные символы Макро PDF417 и символы, вынуждающие декодер передавать управляющие последовательности ECI, не могут быть переданы |
Эта информация не должна кодироваться в символе штрихового кода, однако должна генерироваться декодером после декодирования и передаваться как преамбула к данным сообщения.
ПРИЛОЖЕНИЕ N
(обязательное)
Протокол передачи для декодеров, соответствующий первоначальным спецификациям PDF417
Ранее опубликованные спецификации символики PDF417 ([2] и [3]) поддерживают режим базового канала, идентификаторы глобальной метки - GLI (предшествующие независимой от символики интерпретации расширенного канала - ECI) и Макро PDF417 (но без интегрирования с протоколом ECI). Настоящее приложение определяет протокол передачи, соответствующий первоначальной спецификации ([2] и [3]), который все еще может находиться в эксплуатации, и направлено на обеспечение совместимости.
N.1 Режим базового канала
В режиме базового канала (Basic Channel mode) все знаки данных символа передаются в соответствии с действующими режимами уплотнения и включаются в передачу данных как последовательность 8-битных байтов. Знаки СТАРТ и СТОП, индикаторы строк, дескриптор длины символа, кодовые слова переключения режима и кодовые слова коррекции ошибок не передаются.
Примечание - Передача идентична процедуре, приведенной в 4.17.1. Ранние декодеры должны выдавать идентификатор символики ]L0, однако могут и не передавать префикс идентификатора символики.
N.2 Символы, кодирующие GLI
Ранее были установлены только GLI 1 и GLI 0, но исходным протоколом поддерживается передача всех управляющих последовательностей GLI/ECI. Три кодовых слова (925, 926 и 927) отмечают кодирование значения GLI и декодируются как значения байтов в соответствии с приведенной ниже процедурой:
1) если управляющая последовательность GLI начинается кодовым словом 927 (идентификатор ECI для набора знаков или кодовой страницы):
a) кодовое слово со значением 927 передается как 4-байтовая управляющая последовательность 92, 57, 50, 55, которая представлена \927 в интерпретации знаков КОИ-7
b) следующее кодовое слово представляет номер GLI в области значений от 000 до 899. Кодовое слово преобразовывается в 3-разрядное значение. 3-разрядное значение передается как соответствующие значения байтов (с десятичными значениями от 48 до 57), которым предшествует байт со значением 92
В символе закодировано: [927] [001]
Передача данных (байты): 92, 57, 50, 55, 92, 48, 48, 49
Интерпретация знаков КОИ-7: \927\001;
2) если управляющая последовательность GLI начинается кодовым словом 926 (идентификатор общего назначения формата ECI):
a) кодовое слово 926 передается как 4-байтовая управляющая последовательность 92, 57, 50, 54, которая представлена \926 в интерпретации знаков КОИ-7
b) следующие два кодовых слова (допускаются кодовые слова со значениями от 000 до 899) представляют номер ECI следующим способом:
Кодовое слово 1: Номер_ ECI div 900 - 1
Кодовое слово 2: Номер_ ECI mod 900.
Каждое кодовое слово преобразовывается в 3-разрядное значение. 3-разрядное значение передается как соответствующие значения байтов (от 48 до 57), которым предшествует байт со значением 92.
В символе закодировано: [926] [136] [156]
Передача данных (байты): 92, 57, 50, 54, 92, 49, 51, 54, 92, 49, 53, 54
Интерпретация знаков КОИ-7: \926\136\156;
3) если управляющая последовательность GLI начинается кодовым словом 925 (идентификатор ECI, задаваемый пользователем):
a) кодовое слово 925 передается как 4-байтовая управляющая последовательность 92, 57, 50, 53, которая представлена \925 в интерпретации в знаках КОИ-7
b) следующее кодовое слово представляет номер задаваемого пользователем GLI минус 810900 (допускаются кодовые слова со значениями от 000 до 899). Кодовое слово преобразуется в 3-разрядное значение. 3-разрядное значение передается как соответствующие значения байтов (от 48 до 57), которым предшествует байт со значением 92.
В символе закодировано: [925] [456]
Передача данных (байты): 92, 57, 50, 53, 92, 52, 53, 54
Интерпретация в знаках КОИ-7: \925\456
Эта процедура повторяется для каждого случая появления GLI.
Примечание - Объяснения примеров с соответствующими ECI, но использующие протокол передачи ECI, приведены в 4.17.2
Если знак ОБРАТНАЯ ДРОБНАЯ ЧЕРТА или другой знак, представленный байтом со значением 92, необходимо использовать в качестве закодированных данных, передача должна происходить в соответствии с нижеуказанным примером. Всякий раз, когда байт со значением 92 появляется в качестве данных, должны быть переданы два байта этого значения; таким образом, единичное появление всегда является управляющим знаком, а двоичное появление означает достоверные данные.
Закодированные данные: A\\B\C
Передача: A\\\\B\\C
Управляющий знак по умолчанию может быть изменен в декодере (в таком случае система получения должна быть соответственно сконфигурирована), но тогда не должны использоваться значения байтов от 47 до 58 (в основном интерпретируемые как цифровые разряды).
Примечание - В протоколе для передачи ECI (4.17.2) значение 92 управляющего знака является фиксированным.
В качестве варианта декодеры могут иметь режим работы, при котором управляющие знаки не определены; такие устройства считывания не могут ни передавать управляющие последовательности, ни дублировать любые знаки данных. Таким образом, этот режим не может поддерживать передачу ни управляющих последовательностей ECI, ни управляющих блоков Макро PDF417.
N.3 Символы Макро PDF417
При работе по первоначальному протоколу передачи данных PDF417 после того как декодер PDF417 обработал символ Макро PDF417 с заданной идентификацией файла, он должен декодировать и передать все символы с той же идентификацией файла до передачи любых иных символов. Это требование применяется для каждого из нижеуказанных режимов передачи.
N.3.1 Передача в буферизованном режиме
Буферизованная система передачи требует, чтобы декодер собрал весь комплект символов до его передачи. Обработка обязательных полей управляющего блока Макро PDF417 проводится в рамках декодера. Передача необязательных полей в декодере может быть индивидуально разрешена или запрещена. Необязательные поля, если таковые присутствуют, должны единовременно передаваться в конце полного комплекта данных. Передача каждого поля должна начинаться с передачи соответствующей последовательности-указателя необязательного поля Макро PDF417. Последовательность-указатель состоит из кодового слова 923 (начало необязательного поля Макро PDF417), за которым следует значение указателя в соответствии с таблицей H.1; эта последовательность должна передаваться с помощью управляющего знака в соответствии с N.2. Декодированное высокоуровневое содержимое поля должно передаваться после этой последовательности-указателя.
N.3.2 Передача в небуферизованном режиме
Система небуферизованной передачи позволяет декодеру передавать отдельные символы по мере их декодирования.
При использовании небуферизованной схемы должна быть разрешена передача управляющего заголовка Макро PDF417 (Macro PDF417 Control Header), поскольку символы в небуферизованной схеме не подлежат внутреннему упорядочиванию устройством считывания. Это позволяет системе сервера производить соответствующую систематизацию поступающих данных.
Передача управляющего заголовка Макро PDF417 может быть разрешена или запрещена. Управляющий заголовок Макро PDF417 является частью управляющего блока Макро PDF417 (рисунок H.1), который состоит из кодового слова 928 (Макро-маркер), индекса сегмента (в режиме цифрового уплотнения) и последовательности кодовых слов идентификации файла. В случае, когда передача управляющего заголовка Макро PDF417 разрешена, кодовое слово Макро-маркера и кодовые слова идентификации файла следует передавать, используя управляющий знак в соответствии с N.2. Например, управляющий заголовок Макро PDF417 первого символа, индекс сегмента равный 0 и идентификация файла (значения кодовых слов 100, 200, 300) должны быть закодированы в символе как последовательность кодовых слов:
[928] [111] [100] [100] [200] [300]
и (принимая управляющий знак со значением 92 по умолчанию) переданы следующим образом:
Передача данных (байты): 92, 57, 50, 56, 48, 48, 48, 48, 48, 92, 49, 48, 48, 92, 50, 48, 48, 92, 51, 48, 48
Интерпретация в знаках КОИ-7: \92800000\100\200\300.
Управляющий заголовок Макро PDF417 (если разрешен) следует передавать после данных, закодированных в символе.
Если последняя последовательность GLI, переданная считывающим устройством, не является GLI 0, тогда переданные данные из этого сегмента должны оканчиваться последовательностью байтов 92, 57, 50, 55, 92, 48, 48, 48 (эквивалент в знаках КОИ-7 \927\000), как если бы данные символа оканчивались последовательностью кодовых слов [927][000]. Это возвращает интерпретацию следующего блока к GLI 0.
Передача необязательных полей может быть индивидуально разрешена или запрещена в декодере. Разрешенные необязательные поля должны передаваться вместе с каждым символом Макро PDF417, в котором они были закодированы. Каждое поле должно начинаться с передачи соответствующей последовательности-указателя необязательного поля Макро PDF417. Последовательность-указатель состоит из кодового слова 923, за которым следует значение указателя в соответствии с таблицей H.1; эта последовательность должна передаваться с использованием управляющего знака в соответствии с N.2. Декодированное высокоуровневое содержимое поля должно передаваться после этой последовательности-указателя.
Базируясь только на передаче закодированного потока данных, могут возникнуть трудности или невозможность определения наличия границы между окончанием управляющего блока Макро PDF417 (особенно если он содержит необязательные поля) и началом содержимого данных следующего символа. Протокол передачи системы (например, использующий типовую передачу управляющих знаков STX (НТ)* и ЕТХ (КТ)* или другие процедуры установления связи) может использоваться для определения границ между переданными символами Макро PDF417.
* В скобках приведены русские обозначения управляющих знаков по ГОСТ 27465.
С целью облегчения контроля получения всех символов Макро PDF417 в небуферизованном режиме всякий раз, когда это возможно, следует использовать необязательное поле числа сегментов как часть закодированного управляющего блока Макро PDF417.
N.4 Передача зарезервированных кодовых слов с использованием исходного протокола PDF417
При работе по исходному протоколу передачи PDF417 декодер должен передавать зарезервированное кодовое слово как управляющий знак (со значением 92 по умолчанию), за которым следуют 3 разряда, представляющие десятичное значение зарезервированного кодового слова. Кодовые слова данных, которые следуют после зарезервированного кодового слова, интерпретируются и передаются в соответствии с режимом уплотнения, действующим до зарезервированного кодового слова. В частности, будет установлена интерпретация, как если бы зарезервированное кодовое слово ввело кодовое слово фиксации в режиме в уже действующем режиме уплотнения.
Такая функция фиксации в режиме байтового или цифрового уплотнения заново устанавливает новое «группирование» кодовых слов. Если доминирующим режимом является режим текстового уплотнения, то осуществляется повторный вызов в подрежим прописных букв режима текстового уплотнения.
Примечание - Несмотря на то, что протокол может соответствующим образом передавать синтаксис сообщения любых зарезервированных кодовых слов, будущие определения которых заключаются в сигнальных функциях, он не будет предусматривать однозначного выхода данных для нового режима уплотнения. Следовательно, при использовании исходного протокола передачи PDF417 устройство приема не должно учитывать любые данные, которые следуют за управляющей последовательностью, представляющей вновь определенное кодовое слово режима уплотнения.
N.5 Достижение согласованности между старым и новым оборудованием PDF417
N.5.1 Устройства кодирования
Введение интерпретаций расширенного канала, которые не зависят от символики, подразумевает отделение функций кодирования ECI от кодирования символики. Кодирование GLI де-факто является внутренне связанным с символикой PDF417. Закодированный поток кодовых слов будет равнозначным независимо от того, какое кодирующее оборудование использовалось для его кодирования: существующее или новое. Возможно кодирование, например, данных в соответствии с интерпретацией ECI 000123 (которая еще не задана на момент публикации настоящего стандарта) с помощью кодирующего устройства, способного устанавливать GLI для PDF417; или, на первом этапе, кодирование с помощью кодирующего устройства для независимой от символики ECI, за которым, на втором этапе, следует кодирующее устройство для символики PDF417.
Имеются два ограничения:
- логическая схема с возвратом к GLI 0 должна применяться только для GLI 0 (ECI 000000) и GLI 1 (ECI 000001),
- GLI 0 и GLI 1 не должны смешиваться с другими ECI в одном символе или комплекте символов Макро PDF417.
N.5.2 Декодеры
Ключом к взаимодействию декодеров, использующих исходный и новый протокол PDF417, является обязательная передача префикса идентификатора символики всякий раз, когда декодер сконфигурирован для работы в новом режиме расширенного канала (Extended Channel Mode) и требует обязательного использования префикса, когда старое и новое оборудование PDF417 используется в одной системе, т.е. декодер, имеющий разрешение для работы в режиме расширенного канала (даже при считывании разнородных символов режима базового канала и режима расширенного канала), будет отправлять идентификатор символики с каждой передачей.
Примечание - Исходный стандарт PDF417 ([2] и [3]) не обязывает использовать идентификатор символики даже при дублировании управляющего знака (со значением 92 по умолчанию). Соответствие протоколу ECI, представленное в настоящем стандарте, обязывает использовать идентификатор символики.
Декодеры подлежат проверке на соответствие по одному из следующих условий:
A. Полностью соответствуют протоколу ECI и настоящему стандарту:
1) передают соответствующие идентификаторы символики;
2) имеют возможность установки или переключения на работу в режиме базового канала или режиме расширенного канала;
3) передают протокол ECI в соответствии с настоящим стандартом (4.17.2);
4) обрабатывают Макро PDF417 в соответствии с настоящим стандартом;
B. Соответствуют стандартам 1994 года [2] и [3]:
B.1 и имеют возможности взаимодействия с новым оборудованием и символами, кодирующими ECI:
1) передают идентификатор символики [L0;
2) имеют возможность установки или переключения на работу в режиме базового канала или в режиме расширенного канала;
3) передают протокол GLI в соответствии с N.2;
4) обрабатывают Макро PDF417 в соответствии с N.3,
B.2 но не имеют возможности взаимодействия с новым оборудованием и символами, кодирующими ECI:
1) не передают идентификатор символики;
2) имеют возможность установки или переключения на работу в режиме базового канала или в режиме расширенного канала;
3) передают протокол GLI в соответствии с N.2;
4) обрабатывают Макро PDF417 в соответствии с N.3.
C. Соответствуют только режиму базового канала:
1) передают идентификатор символики [L0 (старое оборудование) или [L2 (новое оборудование) или не передают идентификатор символики;
2) рассматривают символы, содержащие кодовые слова ECI, как ошибочные;
3) рассматривают символы Макро PDF417 как ошибочные, за исключением случая, когда устройство считывания работает в буферизованном режиме и передача управляющего заголовка Макро PDF417 запрещена.
Допустим, что оборудование настроено в соответствии с вышеуказанным, что предоставит устройству считывания возможность обнаруживать и соответствующим образом реагировать на следующие условия:
1) идентификатор символики [L1 присутствует в начале передачи:
В данном случае устройство приема достоверно информируется, что декодер работает в режиме расширенного канала для сканированного символа. Следовательно, все байты со значением 92, когда они появляются в качестве данных, были дублированы независимо от того, содержит ли символ ECI или является частью комплекта Макро PDF 417. Отдельные появления байта со значением 92 указывают начало управляющей последовательности. Все остальные свойства соответствуют настоящему стандарту.
2) идентификатор символики [L2 присутствует в начале передачи:
В данном случае устройство приема информируется, что декодер работает в режиме базового канала для отсканированного символа. Следовательно, байт со значением 92 будет представлять отдельный байт данных.
Символы с управляющими последовательностями ECI должны рассматриваться как ошибочные. Символы Макро PDF417 должны быть рассмотрены как ошибочные, за исключением случая, если устройство считывания работает в буферизованном режиме и передача управляющих заголовков Макро PDF417 запрещена.
3) идентификатор символики [L0 присутствует в начале передачи, указывая версию PDF417 1994 года:
Этот случай является исключением по причине того, что стандарт PDF417 1994 г. ([2] и [3]), несмотря на то, что он подразумевает явную поддержку режима расширенного канала, определяет 0 (т.е. набор вариантов отсутствует) как единственное значение варианта обработки для идентификатора символики PDF417. Таким образом, существующее оборудование PDF417 при полном соответствии стандарту 1994 г. ([2] и [3]) не будет использовать новые значения вариантов, чтобы указать, действует ли режим расширенного канала или режим базового канала. Следовательно, если устройство приема встречает [L0, тогда оно должно ожидать режим, соответствующий стандарту 1994 г. В частности:
- устройство приема не может распознать из передачи, в каком из режимов находится декодер: в режиме расширенного канала (всегда дублирует байт, задаваемый в качестве управляющего знака в соответствии с N.2) или в режиме базового канала (никогда не дублирует байтов); декодер должен быть конфигурирован таким образом, чтобы соответствовать данным, ожидаемым устройством приема;
- если декодер установлен в режим расширенного канала и в символе закодированы ECI, декодер будет скорее передавать управляющие последовательности GLI в формате PDF417 1994 г. (в соответствии с N.2), чем управляющую последовательность ECI, как указано в 4.17.2.
- при использовании исходного протокола, если присутствует управляющий блок Макро PDF417, содержимое управляющего блока Макро PDF417 скорее следует после байтов данных символа, чем предваряет их.
4) в начале передачи нет идентификатора символики:
В этом случае:
a) декодер соответствующим образом сконфигурирован для поддержки только символов режима базового канала. Система приема настроена на то, что декодер не дублировал ни одного значения байта и л0юбые очевидные ECI в потоке байтов являются случайными комбинациями знаков
b) декодер неправильно сконфигурирован для возможности взаимодействия в открытой системе, где могут встречаться символы, кодирующие ECI.
ПРИЛОЖЕНИЕ P
(справочное)
Алгоритм минимизации числа кодовых слов
Одни и те же данные могут быть представлены в виде различных последовательностей кодовых слов PDF417 использованием разных режимов уплотнения и процедур перехода. Не существует предписанной процедуры для минимизации числа требуемых кодовых слов, но для этих целей можно использовать следующий алгоритм:
1) принимают, что P указывает начало потока данных;
2) устанавливают текущий режим кодирования в режим текстового уплотнения;
3) принимают, что N - число последовательных разрядов, начинающихся от P;
4) если N ≥ 13, тогда:
5) фиксируют режим цифрового уплотнения;
6) кодируют N знаков с использованием цифрового уплотнения;
7) передвигают вперед указатель P на N;
8) переходят к шагу 3;
9) в противном случае, если N < 13, тогда:
10) принимают T длиной последовательности знаков в режиме текстового уплотнения, начинающейся с P. Последовательность заканчивается в том случае, если будут обнаружены либо знак, не находящийся в режиме текстового уплотнения, либо цифровая последовательность длиной 13 и более разрядов;
11) если T ≥ 5, тогда:
12) фиксируют режим текстового уплотнения;
13) кодируют T знаков с использованием режима текстового уплотнения;
14) перемещают вперед указатель P на T;
15) переходят к шагу 3
16) в случае, если T < 5, тогда:
17) принимают B в качестве длины кодируемой в двоичном виде последовательности, начинающейся с P. Последовательность заканчивают в случаях, если будут найдены либо последовательность в режиме текстового уплотнения, длиной 5 и более, либо цифровая последовательность, длиной 13 и более
18) если B = 1 и текущий режим текстового уплотнения, тогда:
19) переводят регистр в режим байтового уплотнения;
20) кодируют значение одного байта с использованием режима байтового уплотнения;
21) перемещают вперед указатель P на B;
22) переходят к шагу 3
23) иначе:
24) фиксируют режим байтового уплотнения;
25) кодируют B байтов с использованием режима байтового уплотнения;
26) перемещают вперед указатель P на B;
27) переходят к шагу 3.
ПРИЛОЖЕНИЕ Q
(Справочное)
Рекомендации по определению матрицы символа PDF417
Для определения матрицы символа в виде числа строк (r) и столбцов (c) до печати символа следует использовать ряд параметров.
Каждый параметр назначает одну характеристику, которая может ограничивать матрицу символа. Обозначения (в нижеуказанных уравнениях) A, c, k, QH, QV, r, X и Y соответствуют обозначениям, установленным в 3.2.
Формулы можно использовать непосредственно или для создания более сложного алгоритма.
Параметр 1 - число строк r
Параметр 2 - число столбцов c
Параметр 3 - размер X
Определяют в нормативном документе, устанавливающем требования по применению (4.8)
Параметр 4 - размер Y
Параметр 5 - горизонтальная свободная зона QH
Параметр 6 - вертикальная свободная зона QV
Параметр 7 - полезная длина символа W
Этот параметр может быть ограничен полем обзора сканера или шириной этикетки
W ≥ (17c + 69)X + 2QH
Параметр 8 - полезная высота символа H
Этот параметр может быть ограничен полем обзора сканера или шириной этикетки
H ≥ Yr + 2QV
Параметр 9 - параметры матрицы
(n + k) = (c × r) < 929
Параметр 10 - коэффициент сжатия символа A
До определения размера символа может быть вычислено число кодовых слов данных и кодовых слов коррекции ошибки. Следующий этап зависит от ограничений определенных параметров, указанных в применении. Если параметры применения определяют общий коэффициент сжатия символа, можно использовать рекомендации 2 настоящего приложения по вычислению числа столбцов области данных, требуемых для создания символа с данным коэффициентом сжатия.
Если, в противном случае, в применении ограничивается допустимая высота либо длина символа (или оба параметра), можно использовать более простые вычисления. Рекомендации 1 демонстрируют этот простой алгоритм, который следует использовать при ограниченной длине символа.
Рекомендации 1. В случае, когда общая длина W (включающая свободные зоны) задана, число столбцов данных можно вычислить, используя уравнение параметра 7 (округляя до ближайшего целого значения числа столбцов). В этом случае число строк выводится из общего числа кодовых слов:
(n + k) = (r × c).
Рекомендации 2. Коэффициент сжатия символа A представляет собой отношение высоты к длине символа, включая свободные зоны. Для получения заданного значения A необходимо решить приведенное ниже уравнение относительно числа столбцов (c), в котором допускается, что свободные зоны выражены в точных значениях X. Уравнение может использоваться для всех случаев получения наилучшей аппроксимации числа столбцов (c).

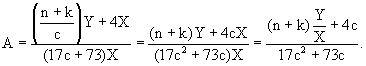
Таким образом
![]()
![]()
где A, c, n, k, X и Y соответствуют обозначениям, приведенным в 3.2.
QH = 2X
QV = 2X
Уравнение может быть записано в следующем виде
![]()
Это уравнение (при замене c на X) является квадратным уравнением вида
aX2 + bX + c = 0,
![]()
При подстановке значений параметров PDF417 решение квадратного уравнения, с отбрасыванием отрицательных значений, может быть записано в следующем виде
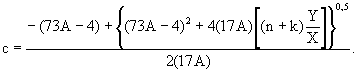
Значение n зависит от числа кодовых слов-заполнителей, которое неизвестно до определения параметров матрицы. Однако число исходных кодовых слов известно и оно может быть подставлено в виде m + 1 ≤ n в уравнении, представленном выше, следующим способом:
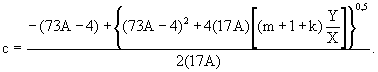
При определении положительного значения c может быть получен результат, не являющийся целым числом. Ближайшее значение целого числа с должно давать наилучшее значение числа столбцов для определения коэффициента сжатия.
Число строк задается величиной
r = INT [(m + 1 + k)/c] + 1.
Если (c × r) ≥ m + 1 + k + c, то
r = r - 1
При (c × r) = (n + k), число кодовых слов-заполнителей равно
(n + k) - (m + 1 + k)
Требуется получить коэффициент сжатия A = 0,5 для символа PDF417, в котором m + 1 + k = 277, X = 0,33 мм и Y = 1,00 мм.

![]()
![]()
![]()
r = INT (277/c) + 1
r = INT (34,6) + 1
r = 35.
(m + 1 + k) ≤ (c × r) < 929;
277 ≤ 280 < 929.
Число требуемых кодовых слов-заполнителей равно:
(c × r) - (m + 1 + k);
280 - 277 = 3.
Этот символ характеризуется следующими параметрами: длина 68,97 мм, высота 36,32 мм, фактический коэффициент сжатия 0,527, количество строк 35 и количество столбцов 8.
Если не удается достичь каких-либо приемлемых параметров и символ не соответствует требуемому размеру этикетки, следует придерживаться следующих рекомендаций:
a) по возможности, уменьшают содержание данных,
b) увеличивают размер этикетки в одном или двух измерениях,
c) уменьшают уровни коррекции ошибок,
d) уменьшают размер X или высоту модуля (Y).
ПРИЛОЖЕНИЕ R
(справочное)
Пример вычисления коэффициентов для генерации кодовых слов коррекции ошибок
Для подсчета коэффициентов каждого уровня коррекции ошибок должен использоваться порождающий полином gk(x):
gk(x) = (x - 3)(x - 32)(x - 33), ..., (x - 3k) = α0 + α1x + α2x2 + , ..., αk-1xk-1 + xk,
где k - общее количество кодовых слов коррекции ошибок;
αj - коэффициент показателей степени x, вычисляемых согласно порождающему полиному gk(x).
Сначала раскладывают в ряд приведенное выше уравнение, затем вычисляют дополнение коэффициента.
Для αj = α0, ..., αk-1
αj = αj mod 929
Требуется вычислить коэффициенты порождающего полинома для уровня коррекции ошибок 1.
s = 1 (уровень коррекции ошибок 1)
k = 2s+1 = 4 (количество кодовых слов коррекции ошибок)
g4(x) = (x - 3)(x - 32)(x - 33)(x - 34) = 59049 - 29160x + 3510x2 - 120x3 + x4
α0 = 59049 mod 929 = 522
α1 = -29160 mod 929 = 568
α2 = 3510 mod 929 = 723
α3 = -120 mod 929 = 809
Примечание - В приложении F приведены таблицы коэффициентов для вычисления кодовых слов коррекции ошибок PDF417, содержащие все значения коэффициентов, необходимые для кодирования символа PDF417 любого уровня коррекции ошибок.
ПРИЛОЖЕНИЕ S
(справочное)
Пример генерации кодовых слов коррекции ошибок
Для генерации кодовых слов коррекции ошибок должен использоваться алгоритм в соответствии с 4.10 (обозначения, используемые в приведенном примере соответствуют обозначениям в 4.10).
Данные PDF417 представлены кодовыми словами 5, 453, 178, 121, 239, перед которыми расположен дескриптор длины символа. Кодовые слова-заполнители отсутствуют. Тогда
n = 5 (количество кодовых слов, включая дескриптор длины символа)
d4 = 5
d3 = 453
d2 = 178
d1 = 121
d0 = 239
При выборе уровня коррекции ошибок 1 получают
s = 1
k = 21+1 = 4
α0, ..., α3 = 522, 568, 723, 809
Примечание - Пример, приведенный для представления всего процесса, упрощен и содержит только пять кодовых слов данных и 4 кодовых слова коррекции ошибок. Процесс значительно усложняется при увеличении числа кодовых слов данных и кодовых слов коррекции ошибок.
Порядок вычисления:
устанавливают Е0, ..., Е3 на нуль.
t1 = (d4 + E3) mod 929 = (5 + 0) mod 929 = 5
t2 = (t1 × α3) mod 929 = (5 × 809) mod 929 = 329
t3 = 929 - t2 = 929 - 329 = 600
E3 = (E2 + t3) mod 929 = (0 + 600) mod 929 = 600
t2 = (t1 × α2) mod 929 = (5 × 723) mod 929 = 828
t3 = 929 - t2 = 929 - 828 = 101
E2 = (E1 + t3) mod 929 = (0 + 101) mod 929 = 101
t2 = (t1 × α1) mod 929 = (5 × 568) mod 929 = 53
t3 = 929 - t2 = 929 - 53 = 876
E1 = (E0 + t3) mod 929 = (0 + 876) mod 929 = 876
t2 = (t1 × α0) mod 929 = (5 × 522) mod 929 = 752
t3 = 929 - t2 = 929 - 752 = 177
E0 = t3 mod 929 = 177 mod 929 = 177
t1 = (d3 + E3) mod 929 = (453 + 600) mod 929 = 124
t2= (t1 × α3) mod 929 = (124 × 809) mod 929 = 913
t3 = 929 - t2 = 929 - 913= 16
E3 = (E2 + t3) mod 929 = (101 + 16) mod 929 = 117
t2 = (t1 × α2) mod 929 = (124 × 723) mod 929 = 468
t3 = 929 - t2 = 929 - 468 = 461
E2 = (E1 + t3) mod 929 = (876 + 461) mod 929 = 408
t2 = (t1 × α1) mod 929 = (124 × 568) mod 929 = 757
t3 = 929 - t2 = 929 - 757= 172
E1 = (E0 + t3) mod 929 = (177 + 172) mod 929 = 349
t2 = (t1 × α0) mod 929 = (124 × 522) mod 929 = 627
t3 = 929 - t2 = 929 - 627 = 302
E0 = t3 mod 929 = 302 mod 929 = 302
t1 = (d2 + E3) mod 929 = (178 + 117) mod 929 = 295
t2 = (t1 × α3) mod 929 = (295 × 809) mod 929 = 831
t3 = 929 - t2 = 929 - 831 = 98
E3 = (E2 + t3) mod 929 = (408 + 98) mod 929 = 506
t2 = (t1 × α2) mod 929 = (295 × 723) mod 929 = 544
t3 = 929 - t2 = 929 - 544 = 385
E2 = (E1 + t3) mod 929 = (349 + 385) mod 929 = 734
t2 = (t1 × α2) mod 929 = (295 × 568) mod 929 = 340
t3 = 929 - t2 = 929 - 340 = 589
E1 = (E0 + t3) mod 929 = (302 + 589) mod 929 = 891
t2 = (t1 × α0) mod 929 = (295 × 522) mod 929 = 705
t3 = 929 - t2 = 929 - 705 = 224
E0 = t3 mod 929 = 224 mod 929 = 224
t1 = (d1 + E3) mod 929 = (121 + 506) mod 929 = 627
t2 = (t1 × α3) mod 929 = (627 × 809) mod 929 = 9
t3 = 929 - t2 = 929 - 9 = 920
E3 = (E2 + t3) mod 929 = (734 + 920) mod 929 = 725
t2 = (t1 × α2) mod 929 = (627 × 723) mod 929 = 898
t3 = 929 - t2 = 929 - 898 = 31
E2 = (E1 + t3) mod 929 = (891 + 31) mod 929 = 922
t2 = (t1 × α1) mod 929 = (627 × 568) mod 929 = 329
t3 = 929 - t2 = 929 - 329 = 600
E1 = (E0 + t3) mod 929 = (224 + 600) mod 929 = 824
t2 = (t1 × α0) mod 929 = (627 × 522) mod 929 = 286
t3 = 929 - t2 = 929 - 286 = 643
E0 = t3 mod 929 = 643 mod 929 = 643
t1 = (d0 + E3) mod 929 = (239 + 725) mod 929 = 35
t2 = (t1 × α3) mod 929 = (35 × 809) mod 929 = 445
t3 = 929 - t2 = 929 - 445 = 484
E3 = (E2 + t3) mod 929 = (922 + 484) mod 929 = 477
t2 = (t1 × α2) mod 929 = (35 × 723) mod 929 = 222
t3 = 929 - t2 = 929 - 222 = 707
E2 = (E1 + t3) mod 929 = (824 + 707) mod 929 = 602
t2 = (t1 × α1) mod 929 = (35 × 568) mod 929 = 371
t3 = 929 - t2 = 929 - 371 = 558
E1 = (E0 + t3) mod 929 = (643 + 558) mod 929 = 272
t2 = (t1 × α0) mod 929 = (35 × 522) mod 929 = 619
t3 = 929 - t2 = 929 - 619 = 310
E0 = t3 mod 929 = 310 mod 929 = 310
В конце вычисляют дополнения приведенных выше результатов и получают 4 кодовых слова коррекции ошибок для закодированных данных символа PDF417:
Е3 = 929 - Е3 = 929 - 477 = 452
Е2 = 929 - Е2 = 929 - 602 = 327
Е1 = 929 - Е1 = 929 - 272 = 657
Е0 = 929 - Е0 = 929 - 310 = 619
ПРИЛОЖЕНИЕ T
(справочное)
Процедура схемы деления для генерации кодовых слов коррекции ошибок
Эта процедура представляет собой альтернативу процедуре, установленной в 4.10, и использует схему деления в качестве базы определения кодовых слов коррекции ошибок.
Схема деления приведена на рисунке Т1.
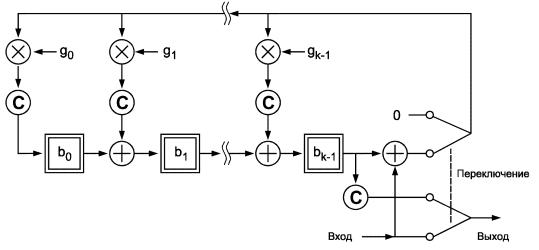
![]() - дополнение по модулю
- дополнение по модулю
![]() - сложение по модулю
- сложение по модулю
![]() - умножение по модулю
- умножение по модулю
Рисунок T.1 - Схема кодирования кодовых слов коррекции ошибок
Регистры от b0 до bk-1 должны быть установлены в исходное состояние в виде нулей. Математика по модулю должна быть задана следующими уравнениями:
x ![]() y = (x +
y) mod 929,
y = (x +
y) mod 929,
x ![]() y = (x × y) mod 929,
y = (x × y) mod 929,
![]() x = (929
- x) mod 929,
x = (929
- x) mod 929,
где x и y являются числами от 0 до 928;
![]() - дополнение по
модулю;
- дополнение по
модулю;
![]() - сложение по
модулю;
- сложение по
модулю;
![]() - умножение по модулю.
- умножение по модулю.
Генерирование кодирования происходит в два этапа. На первом этапе с переключением в нижнее положение данные символа проходят и к выводу и к схеме. Первый этап завершается после n синхронизирующих импульсов. На втором этапе (синхронизирующие импульсы n + 1, ..., n + k) с переключением в верхнее положение генерируются кодовые слова коррекции ошибок Ek-1 E0 путем смещения регистров по порядку и дополнения вывода данных при удержании ввода данных на нуле.
ПРИЛОЖЕНИЕ U
(справочное)
Совместимость с автоматическим распознаванием
PDF417 может считываться с помощью соответствующим образом запрограммированных декодеров штриховых кодов, которые были разработаны для автоматического распознавания его от других символик. Используемый декодером набор символик должен быть ограничен до количества, которое требуется в данном применении для обеспечения наивысшей надежности считывания.
ПРИЛОЖЕНИЕ V
(справочное)
Соответствие международных и русских терминов и обозначений, встречающихся в тексте настоящего стандарта
Данное приложение включено в дополнение к международному стандарту ИСО/МЭК 15438 и содержит соответствие терминов и обозначений на русском языке (в настоящем стандарте) и английском языке (в ИСО/МЭК 15438) для удобства пользователей при переводе документов с одного языка на другой.
Таблица V.1 - Соответствие международных и русских наименований кодовых слов
|
русское |
международное |
|
Кодовое слово коррекции ошибок |
Error correction codeword |
|
Функциональное кодовое слово |
function codeword |
|
Кодовое слово фиксации в режиме |
Mode Latch codeword |
|
Кодовое слово регистра в режиме |
Mode Shift codeword |
|
Кодовое слово индикатора строки |
Row Indicator codeword |
|
Дескриптор длины символа |
Symbol Length Descriptor |
|
Кодовое слово данных |
data codeword |
|
Левый индикатор строки |
Left row indicator |
|
Правый индикатор строки |
Right row indicator |
|
Кодовое слово-заполнитель |
pad codeword |
|
Фиксация в режиме текстового уплотнения |
Text Compaction mode latch |
|
Фиксация в режиме байтового уплотнения |
Byte Compaction mode latch |
|
Фиксация в режиме цифрового уплотнения |
Numeric Compaction mode latch |
|
Регистр в режиме байтового уплотнения |
mode shift to Byte Compaction mode |
|
Инициализация считывающего устройства |
reader initialization |
|
Ограничитель Макро PDF417 |
Macro PDF417 Terminator |
|
Начало необязательного поля Макро PDF417 |
Beginning of Macro PDF417 Optional Field |
|
Идентификатор интерпретации расширенного канала пользователя |
identifier for a user defined ECI |
|
Идентификатор общего назначения формата интерпретации расширенного канала |
identifier for a general purpose ECI format |
|
Идентификатор интерпретации расширенного канала для набора знаков или кодовой страницы |
identifier for an ECI of a character set or code page |
|
Начало управляющего блока Макро PDF417 или Макро-маркер |
Beginning of Macro PDF417 Control Block или Macro marker |
|
Указатель поля |
field designator |
|
Знак символа СТАРТ |
START character (Start pattern) |
|
Знак символа СТОП |
STOP character (Stop pattern) |
Таблица V.2 - Соответствие международных и русских наименований знаков
|
Обозначение знака |
Наименование знака |
|
|
русское |
международное |
|
|
al |
Знак фиксации в подрежиме прописных букв |
latch to uppercase alphabetic sub-mode |
|
ll |
Знак фиксации в подрежиме строчных букв |
latch to lowercase alphabetic sub-mode |
|
ml |
Знак фиксации в подрежиме смешанных знаков |
latch to mixed sub-mode |
|
pl |
Знак фиксации в подрежиме знаков пунктуации |
latch to punctuation sub-mode |
Таблица V.3 - Соответствие международных и русских наименований и обозначений режимов и подрежимов и блоков PDF417
|
русское |
международное |
|
Режим уплотнения |
compaction mode |
|
Режим текстового уплотнения |
Text Compaction mode |
|
Режим байтового уплотнения |
Byte Compaction mode |
|
Режим цифрового уплотнения |
Numeric Compaction mode |
|
Подрежим прописных букв |
Alpha sub-mode |
|
Подрежим строчных букв |
Lower sub-mode |
|
Подрежим смешанных знаков |
Mixed sub-mode |
|
Подрежим знаков пунктуации |
Punctuation sub-mode |
|
Буферизированный режим |
buffered mode |
|
Небуферизированный режим |
unbuffered mode |
|
Режим базового канала |
Basic Channel |
|
Режим расширенного канала |
Extended Channel mode |
Таблица V.4 - Соответствие международных и русских наименований свойств PDF417
|
Наименование свойства PDF417 |
|
|
русское |
международное |
|
Уплотнение данных |
Data compaction |
|
Интерпретация расширенного канала |
Extended Channel Interpretation |
|
Макро ПДФ417 |
Macro PDF417 |
|
Декодируемость от края до края |
Edge to edge decodable |
|
Перекрестное сканирование строк |
Cross row scanning |
|
Коррекция ошибок |
Error correction |
|
Компакт ПДФ417 |
Compact PDF417 |
|
Идентификатор глобальной метки |
Global Label Identifier |
|
Управляющий блок Макро ПДФ417 |
Macro PDF417 Control Block |
|
Модель базового канала |
Basic Channel Model |
|
Модель расширенного канала |
Extended Channel Model |
|
Кластер |
cluster |
|
Коэффициент сжатия символа |
symbol aspect ratio |
|
Идентификатор символики |
symbology identifier |
|
Коэффициент сжатия модуля |
aspect ratio of the module |
|
Глобальный порог |
global threshold |
|
Управляющий заголовок Макро PDF417 |
Macro PDF417 Control Header |
Таблица V.5 - Соответствие международных и русских наименований полей PDF417 и их атрибутов
|
Наименование полей PDF417 |
|
|
русское |
международное |
|
Индекс сегмента |
segment index |
|
Идентификация файла |
file ID |
|
Имя файла |
File Name |
|
Число сегментов |
Segment Count |
|
Отметка времени |
Time Stamp |
|
Отправитель |
Sender |
|
Получатель |
Addressee |
|
Размер файла |
File Size |
|
Контрольная сумма |
Checksum |
|
Необязательное поле |
optional field |
|
Последовательность-указатель |
tag sequence |
|
Указатель поля |
field designator |
|
Индекс Макро |
Macro Index |
|
Окончания файла Макро |
Macro end-of-file |
Таблица V.6 - Соответствие международных и русских наименований и обозначений управляющих знаков
|
Наименование знака |
|||
|
международное |
русское |
международное |
русское |
|
NUL |
ПУС |
NULL |
ПУСТО |
|
SOH |
НЗ |
START OF HEADING |
НАЧАЛО ЗАГОЛОВКА |
|
STX |
НТ |
START OF TEXT |
НАЧАЛО ТЕКСТА |
|
ЕТХ |
КТ |
END OF TEXT |
КОНЕЦ ТЕКСТА |
|
EOT |
КП |
END OF TRANSMISSION |
КОНЕЦ ПЕРЕДАЧИ |
|
ENQ |
КТМ |
ENQUIRY |
КТО ТАМ? |
|
ACK |
ДА |
ACKNOWLEDGE |
ПОДТВЕРЖДЕНИЕ |
|
BEL |
ЗВ |
BELL |
ЗВОНОК |
|
BS |
ВШ |
BACKSPACE |
ВОЗВРАТ НА ШАГ |
|
HT |
ГТ |
HORIZONTAL TABULATION |
ГОРИЗОНТАЛЬНАЯ ТАБУЛЯЦИЯ |
|
LF |
ПС |
LINE FEED |
ПЕРЕВОД СТРОКИ |
|
VT |
ВТ |
VERTICAL TABULATION |
ВЕРТИКАЛЬНАЯ ТАБУЛЯЦИЯ |
|
FF |
ПФ |
FORM FEED |
ПЕРЕВОД ФОРМАТА |
|
CR |
ВК |
CARRIAGE RETURN |
ВОЗВРАТ КАРЕТКИ |
|
SO |
ВЫХ |
SHIFT-OUT |
ВЫХОД |
|
SI |
ВХ |
SHIFT-IN |
ВХОД |
|
DLE |
АР1 |
DATA LINK ESCAPE |
АВТОРЕГИСТР ОДИН |
|
DC1 |
СУ1 |
DEVICE CONTROL ONE |
СИМВОЛ УСТРОЙСТВА ОДИН |
|
DC2 |
СУ2 |
DEVICE CONTROL TWO |
СИМВОЛ УСТРОЙСТВА ДВА |
|
DC3 |
СУ3 |
DEVICE CONTROL THREE |
СИМВОЛ УСТРОЙСТВА ТРИ |
|
DC4 |
СУ4 |
DEVICE CONTROL FOUR |
СИМВОЛ УСТРОЙСТВА ЧЕТЫРЕ |
|
NAK |
НЕТ |
NEGATIVE ACKNOWLEDGE |
ОТРИЦАНИЕ |
|
SYN |
СИН |
SYNCHRONOUS IDLE |
СИНХРОНИЗАЦИЯ |
|
ETB |
КБ |
END OF TRANSMISSION BLOCK |
КОНЕЦ БЛОКА |
|
CAN |
АН |
CANCEL |
АННУЛИРОВАНИЕ |
|
EM |
КН |
END OF MEDIUM |
КОНЕЦ НОСИТЕЛЯ |
|
SUB |
ЗМ |
SUBSTITUTE CHARACTER |
ЗАМЕНА СИМВОЛА |
|
ESC |
АР2 |
ESCAPE |
АВТОРЕГИСТР ДВА |
|
FS |
РФ |
FILE SEPARATOR |
РАЗДЕЛИТЕЛЬ ФАЙЛОВ |
|
GS |
РГ |
GROUP SEPARATOR |
|
|
RS |
РЗ |
RECORD SEPARATOR |
|
|
US |
РЭ |
UNIT SEPARATOR |
|
|
DEL |
ЗБ |
DELETE |
ЗАБОЙ |
|
NBSP |
НПР |
NO-BREAK SPACE |
НЕПРЕРЫВАЮЩИЙ ПРОБЕЛ |
Примечания
1 Русские наименования и обозначения знаков по ГОСТ 27465, кроме знака NBSP.
2 Русские наименования и обозначения знака NBSP по ГОСТ 34.302.2
ПРИЛОЖЕНИЕ W
(справочное)
Соответствие межгосударственных стандартов международным стандартам
В таблице W.1 приведены сведения о соответствии межгосударственных стандартов международным стандартам, указанным в разделе 2.
Таблица W.1 - Соответствие межгосударственных стандартов международным стандартам
|
Обозначение и наименование ссылочного межгосударственного стандарта |
Обозначение и наименование ссылочного международного стандарта и условное обозначение степени его соответствия ссылочному межгосударственному стандарту |
|
ГОСТ 27463-87 «Системы обработки информации. 7-ми битные кодированные наборы символов» |
ИСО 646-91 «Информационная технология - 7-битный кодированный набор знаков ИСО для обмена информацией» |
|
ГОСТ 30640-99 (ЕН 796-95) «Автоматическая идентификация. Штриховое кодирование. Идентификаторы символик» |
ЕН 796-96 «Штриховое кодирование. Идентификаторы символик» |
|
ГОСТ 30721-2000/ГОСТ Р 51294.3-99 «Автоматическая идентификация. Кодирование штриховое. Термины и определения» |
ЕН 1556-98 «Штриховое кодирование. Терминология» |
Примечания
1 ГОСТ 27463 и ГОСТ 30721 разработаны на основе соответствующих международных стандартов и не содержат их аутентичный текст.
2 ГОСТ 30640 не действует на территории Российской Федерации, российским пользователям следует применять ГОСТ Р 51294.1.
ПРИЛОЖЕНИЕ X
(справочное)
Соответствие государственных стандартов Российской Федерации международным стандартам
В таблице X.1 приведены сведения о соответствии государственных стандартов Российской Федерации международным стандартам, указанным в разделе 3.
Таблица X.1 - Соответствие государственных стандартов Российской Федерации международным стандартам
|
Обозначение и наименование ссылочного государственного стандарта Российской Федерации |
Обозначение и наименование ссылочного международного стандарта и условное обозначение степени его соответствия ссылочному государственному стандарту |
|
ГОСТ Р 51294.7-2001 (ИСО/МЭК 15416-2000) «Автоматическая идентификация. Кодирование штриховое. Линейные символы штрихового кода. Требования к испытаниям качества печати» |
ИСО/МЭК 15416-2000 «Информационная технология - Технологии автоматической идентификации и сбора данных - Спецификации испытаний качества печати штриховых кодов - Линейные символы» |
|
ГОСТ Р 51294.1-99 «Автоматическая идентификация. Кодирование штриховое. Идентификаторы символик» |
ЕН 796-96 «Штриховое кодирование. Идентификаторы символик» |
Библиография
[1] Техническая спецификация АИМ Интернешнл «Интерпретации расширенного канала» - Часть 1. Идентификационные схемы и протокол (AIM International Technical Specification: Extended Channel Interpretations - Part 1: Identification Schemes and Protocol)
[2] АИМ США «Единые спецификации символики ПДФ417», 1994 (AIM USA «Uniform Symbology Specification PDF417», 1994)
[3] АИМ Европа «Единые спецификации символики ПДФ417», 1994 (AIM Europe «Uniform Symbology Specification PDF417», 1994)
[4] ANSI X3.4-1986 (R1997) Информационные системы - Наборы кодированных знаков - 7-битный Американский национальный стандартный код для обмена информацией (7-битный ASCII) (ANSI X3.4-1986 (R1997) Information Systems - Coded Character Sets - 7-Bit American National Standard Code for Information Interchange (7-Bit ASCII))
[5] Техническая спецификация АИМ Интернешнл «Интерпретации расширенного канала» - Часть 2. Регистрация наборов кодированных знаков и прочих форматов данных (AIM International Procedure Standard: Extended Channel Interpretations - Part 2: Registration of Coded Character Sets and Other Data Formats)
[6] «Теория и практика кодов контроля ошибки» Richard E. Blahut (издано Addison Wesley, 1984 год) (с стр. 260) (Theory and Practice of Error Control Codes’ Richard E. Blahut (published by Addison Wesley, 1984) (page 260 etc.)
Ключевые слова: штриховой код, символика, символ, кодирование, многострочная символика, PDF417